 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Layer Normalization for Universal Approximation
May 19, 2025Universal approximation theorem (UAT) is a fundamental theory for deep neural networks (DNNs), demonstrating their powerful representation capacity to represent and approximate any function. The analyses and proofs of UAT are based on traditional network with only linear and nonlinear activation functions, but omitting normalization layers, which are commonly employed to enhance the training of modern networks. This paper conducts research on UAT of DNNs with normalization layers for the first time. We theoretically prove that an infinitely wide network -- composed solely of parallel layer normalization (PLN) and linear layers -- has universal approximation capacity. Additionally, we investigate the minimum number of neurons required to approximate $L$-Lipchitz continuous functions, with a single hidden-layer network. We compare the approximation capacity of PLN with traditional activation functions in theory. Different from the traditional activation functions, we identify that PLN can act as both activation function and normalization in deep neural networks at the same time. We also find that PLN can improve the performance when replacing LN in transformer architectures, which reveals the potential of PLN used in neural architectures.
Spot the Fake: Large Multimodal Model-Based Synthetic Image Detection with Artifact Explanation
Mar 19, 2025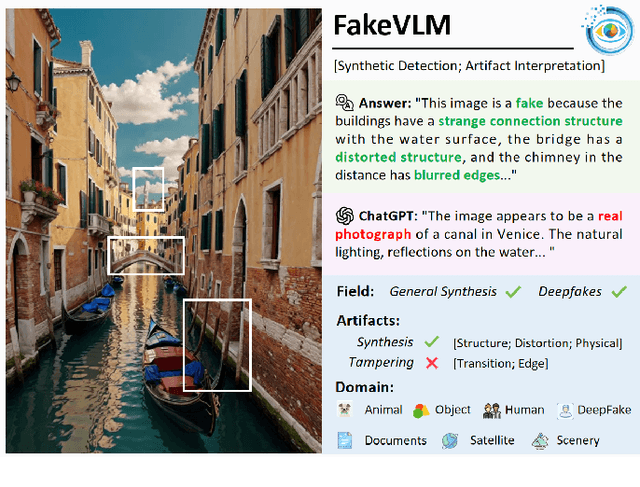
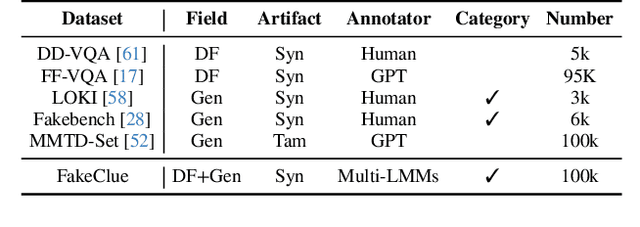

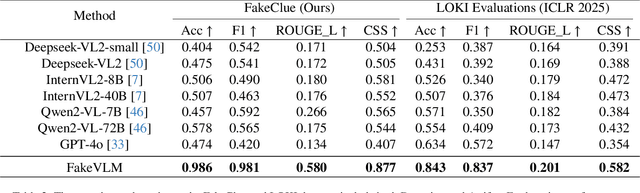
With the rapid advancement of Artificial Intelligence Generated Content (AIGC) technologies, synthetic images have become increasingly prevalent in everyday life, posing new challenges for authenticity assessment and detection. Despite the effectiveness of existing methods in evaluating image authenticity and locating forgeries, these approaches often lack human interpretability and do not fully address the growing complexity of synthetic data. To tackle these challenges, we introduce FakeVLM, a specialized large multimodal model designed for both general synthetic image and DeepFake detection tasks. FakeVLM not only excels in distinguishing real from fake images but also provides clear, natural language explanations for image artifacts, enhancing interpretability. Additionally, we present FakeClue, a comprehensive dataset containing over 100,000 images across seven categories, annotated with fine-grained artifact clues in natural language. FakeVLM demonstrates performance comparable to expert models while eliminating the need for additional classifiers, making it a robust solution for synthetic data detection. Extensive evaluations across multiple datasets confirm the superiority of FakeVLM in both authenticity classification and artifact explanation tasks, setting a new benchmark for synthetic image detection. The dataset and code will be released in: https://github.com/opendatalab/FakeVLM.
LEGION: Learning to Ground and Explain for Synthetic Image Detection
Mar 19, 2025The rapid advancements in generative technology have emerged as a double-edged sword. While offering powerful tools that enhance convenience, they also pose significant social concerns. As defenders, current synthetic image detection methods often lack artifact-level textual interpretability and are overly focused on image manipulation detection, and current datasets usually suffer from outdated generators and a lack of fine-grained annotations. In this paper, we introduce SynthScars, a high-quality and diverse dataset consisting of 12,236 fully synthetic images with human-expert annotations. It features 4 distinct image content types, 3 categories of artifacts, and fine-grained annotations covering pixel-level segmentation, detailed textual explanations, and artifact category labels. Furthermore, we propose LEGION (LEarning to Ground and explain for Synthetic Image detectiON), a multimodal large language model (MLLM)-based image forgery analysis framework that integrates artifact detection, segmentation, and explanation. Building upon this capability, we further explore LEGION as a controller, integrating it into image refinement pipelines to guide the generation of higher-quality and more realistic images. Extensive experiments show that LEGION outperforms existing methods across multiple benchmarks, particularly surpassing the second-best traditional expert on SynthScars by 3.31% in mIoU and 7.75% in F1 score. Moreover, the refined images generated under its guidance exhibit stronger alignment with human preferences. The code, model, and dataset will be released.
Bench-CoE: a Framework for Collaboration of Experts from Benchmark
Dec 05, 2024Large Language Models (LLMs) are key technologies driving intelligent systems to handle multiple tasks. To meet the demands of various tasks, an increasing number of LLMs-driven experts with diverse capabilities have been developed, accompanied by corresponding benchmarks to evaluate their performance. This paper proposes the Bench-CoE framework, which enables Collaboration of Experts (CoE) by effectively leveraging benchmark evaluations to achieve optimal performance across various tasks. Bench-CoE includes a set of expert models, a router for assigning tasks to corresponding experts, and a benchmark dataset for training the router. Moreover, we formulate Query-Level and Subject-Level approaches based on our framework, and analyze the merits and drawbacks of these two approaches. Finally, we conduct a series of experiments with vary data distributions on both language and multimodal tasks to validate that our proposed Bench-CoE outperforms any single model in terms of overall performance. We hope this method serves as a baseline for further research in this area. The code is available at \url{https://github.com/ZhangXJ199/Bench-CoE}.