 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAGA: Terrain-aware Active Gaze Learning for Generalizable Agile Humanoid Locomotion
Jun 04, 2026Agile humanoid locomotion across diverse challenging terrain demands both wide perceptual coverage and precise local geometry understanding. Motivated by the way humans selectively look at relevant terrain during locomotion, we introduce TAGA, a Terrain-aware Active Gaze learning framework for Attention-based humanoid control. By fusing vision, proprioception, and motion commands, our framework guides the model to learn anticipatory cues and actively attend to specific areas of the height scan, selectively using these informative regions for the downstream network. This adaptively increases the information density of observations under tight onboard computational constraints, thus enabling fine-grained perceptive locomotion over larger-scale terrains. We find that such gaze behaviors can naturally emerge through reinforcement learning alone, without requiring additional supervision or explicit guidance, significantly improve training efficiency. As a result, the trained policy demonstrates robust and generalizable locomotion in simulation and on hardware, including reliable terrain-aware foothold selection, elevated-platform traversal, competitive sparse-foothold traversal, and the largest reported real-world gap traversal distance of 1.2m among perceptive humanoid locomotion systems, while maintaining stability under severe perceptual disturbances and environmental interference.
GPO: Growing Policy Optimization for Legged Robot Locomotion and Whole-Body Control
Jan 28, 2026Training reinforcement learning (RL) policies for legged robots remains challenging due to high-dimensional continuous actions, hardware constraints, and limited exploration. Existing methods for locomotion and whole-body control work well for position-based control with environment-specific heuristics (e.g., reward shaping, curriculum design, and manual initialization), but are less effective for torque-based control, where sufficiently exploring the action space and obtaining informative gradient signals for training is significantly more difficult. We introduce Growing Policy Optimization (GPO), a training framework that applies a time-varying action transformation to restrict the effective action space in the early stage, thereby encouraging more effective data collection and policy learning, and then progressively expands it to enhance exploration and achieve higher expected return. We prove that this transformation preserves the PPO update rule and introduces only bounded, vanishing gradient distortion, thereby ensuring stable training. We evaluate GPO on both quadruped and hexapod robots, including zero-shot deployment of simulation-trained policies on hardware. Policies trained with GPO consistently achieve better performance. These results suggest that GPO provides a general, environment-agnostic optimization framework for learning legged locomotion.
FARE: Fast-Slow Agentic Robotic Exploration
Jan 21, 2026This work advances autonomous robot exploration by integrating agent-level semantic reasoning with fast local control. We introduce FARE, a hierarchical autonomous exploration framework that integrates a large language model (LLM) for global reasoning with a reinforcement learning (RL) policy for local decision making. FARE follows a fast-slow thinking paradigm. The slow-thinking LLM module interprets a concise textual description of the unknown environment and synthesizes an agent-level exploration strategy, which is then grounded into a sequence of global waypoints through a topological graph. To further improve reasoning efficiency, this module employs a modularity-based pruning mechanism that reduces redundant graph structures. The fast-thinking RL module executes exploration by reacting to local observations while being guided by the LLM-generated global waypoints. The RL policy is additionally shaped by a reward term that encourages adherence to the global waypoints, enabling coherent and robust closed-loop behavior. This architecture decouples semantic reasoning from geometric decision, allowing each module to operate in its appropriate temporal and spatial scale. In challenging simulated environments, our results show that FARE achieves substantial improvements in exploration efficiency over state-of-the-art baselines. We further deploy FARE on hardware and validate it in complex, large scale $200m\times130m$ building environment.
HELM: Human-Preferred Exploration with Language Models
Mar 10, 2025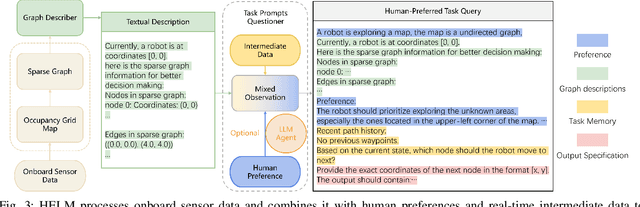
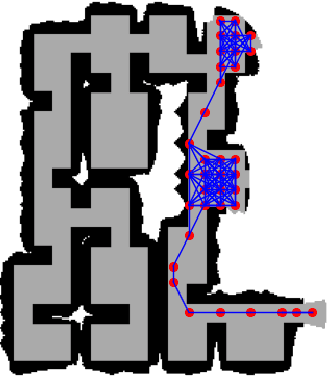
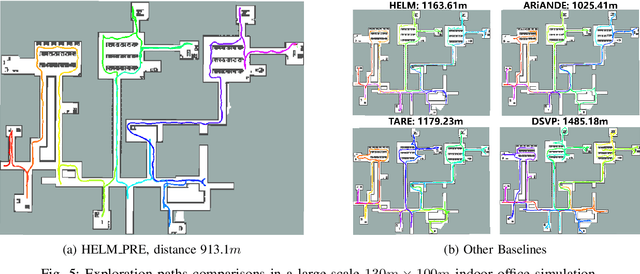
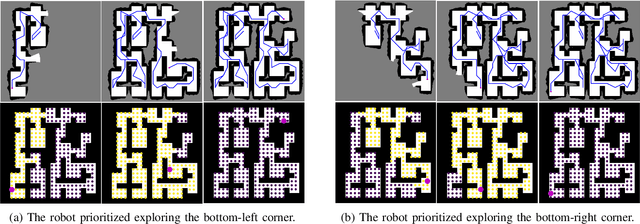
In autonomous exploration tasks, robots are required to explore and map unknown environments while efficiently planning in dynamic and uncertain conditions. Given the significant variability of environments, human operators often have specific preference requirements for exploration, such as prioritizing certain areas or optimizing for different aspects of efficiency. However, existing methods struggle to accommodate these human preferences adaptively, often requiring extensive parameter tuning or network retraining. With the recent advancements in Large Language Models (LLMs), which have been widely applied to text-based planning and complex reasoning, their potential for enhancing autonomous exploration is becoming increasingly promising. Motivated by this, we propose an LLM-based human-preferred exploration framework that seamlessly integrates a mobile robot system with LLMs. By leveraging the reasoning and adaptability of LLMs, our approach enables intuitive and flexible preference control through natural language while maintaining a task success rate comparable to state-of-the-art traditional methods. Experimental results demonstrate that our framework effectively bridges the gap between human intent and policy preference in autonomous exploration, offering a more user-friendly and adaptable solution for real-world robotic applications.
SIGMA: Sheaf-Informed Geometric Multi-Agent Pathfinding
Feb 10, 2025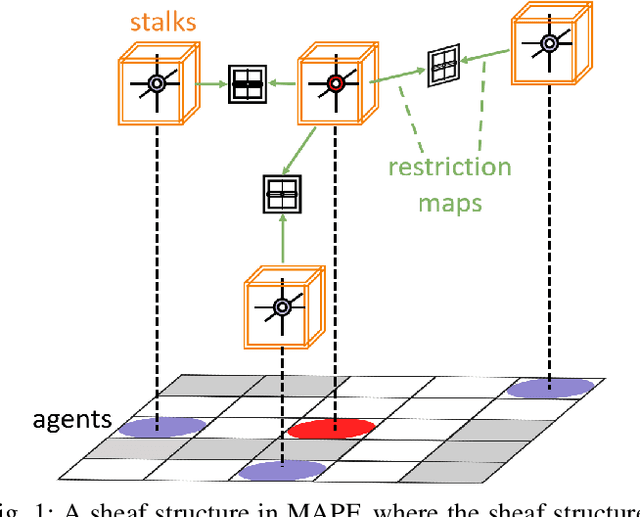



The Multi-Agent Path Finding (MAPF) problem aims to determine the shortest and collision-free paths for multiple agents in a known, potentially obstacle-ridden environment. It is the core challenge for robotic deployments in large-scale logistics and transportation. Decentralized learning-based approaches have shown great potential for addressing the MAPF problems, offering more reactive and scalable solutions. However, existing learning-based MAPF methods usually rely on agents making decisions based on a limited field of view (FOV), resulting in short-sighted policies and inefficient cooperation in complex scenarios. There, a critical challenge is to achieve consensus on potential movements between agents based on limited observations and communications. To tackle this challenge, we introduce a new framework that applies sheaf theory to decentralized deep reinforcement learning, enabling agents to learn geometric cross-dependencies between each other through local consensus and utilize them for tightly cooperative decision-making. In particular, sheaf theory provides a mathematical proof of conditions for achieving global consensus through local observation. Inspired by this, we incorporate a neural network to approximately model the consensus in latent space based on sheaf theory and train it through self-supervised learning. During the task, in addition to normal features for MAPF as in previous works, each agent distributedly reasons about a learned consensus feature, leading to efficient cooperation on pathfinding and collision avoidance. As a result, our proposed method demonstrates significant improvements over state-of-the-art learning-based MAPF planners, especially in relatively large and complex scenarios, demonstrating its superiority over baselines in various simulations and real-world robot experiments.
Bench-CoE: a Framework for Collaboration of Experts from Benchmark
Dec 05, 2024Large Language Models (LLMs) are key technologies driving intelligent systems to handle multiple tasks. To meet the demands of various tasks, an increasing number of LLMs-driven experts with diverse capabilities have been developed, accompanied by corresponding benchmarks to evaluate their performance. This paper proposes the Bench-CoE framework, which enables Collaboration of Experts (CoE) by effectively leveraging benchmark evaluations to achieve optimal performance across various tasks. Bench-CoE includes a set of expert models, a router for assigning tasks to corresponding experts, and a benchmark dataset for training the router. Moreover, we formulate Query-Level and Subject-Level approaches based on our framework, and analyze the merits and drawbacks of these two approaches. Finally, we conduct a series of experiments with vary data distributions on both language and multimodal tasks to validate that our proposed Bench-CoE outperforms any single model in terms of overall performance. We hope this method serves as a baseline for further research in this area. The code is available at \url{https://github.com/ZhangXJ199/Bench-CoE}.
Leveraging Partial Symmetry for Multi-Agent Reinforcement Learning
Dec 30, 2023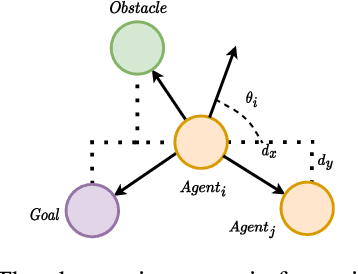
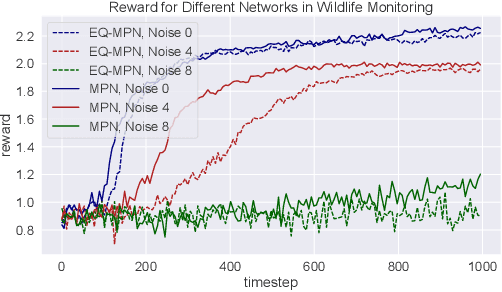

Incorporating symmetry as an inductive bias into multi-agent reinforcement learning (MARL) has led to improvements in generalization, data efficiency, and physical consistency. While prior research has succeeded in using perfect symmetry prior, the realm of partial symmetry in the multi-agent domain remains unexplored. To fill in this gap, we introduce the partially symmetric Markov game, a new subclass of the Markov game. We then theoretically show that the performance error introduced by utilizing symmetry in MARL is bounded, implying that the symmetry prior can still be useful in MARL even in partial symmetry situations. Motivated by this insight, we propose the Partial Symmetry Exploitation (PSE) framework that is able to adaptively incorporate symmetry prior in MARL under different symmetry-breaking conditions. Specifically, by adaptively adjusting the exploitation of symmetry, our framework is able to achieve superior sample efficiency and overall performance of MARL algorithms. Extensive experiments are conducted to demonstrate the superior performance of the proposed framework over baselines. Finally, we implement the proposed framework in real-world multi-robot testbed to show its superiority.