 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Algorithmic Reasoners informed Large Language Model for Multi-Agent Path Finding
Aug 25, 2025The development and application of large language models (LLM) have demonstrated that foundational models can be utilized to solve a wide array of tasks. However, their performance in multi-agent path finding (MAPF) tasks has been less than satisfactory, with only a few studies exploring this area. MAPF is a complex problem requiring both planning and multi-agent coordination. To improve the performance of LLM in MAPF tasks, we propose a novel framework, LLM-NAR, which leverages neural algorithmic reasoners (NAR) to inform LLM for MAPF. LLM-NAR consists of three key components: an LLM for MAPF, a pre-trained graph neural network-based NAR, and a cross-attention mechanism. This is the first work to propose using a neural algorithmic reasoner to integrate GNNs with the map information for MAPF, thereby guiding LLM to achieve superior performance. LLM-NAR can be easily adapted to various LLM models. Both simulation and real-world experiments demonstrate that our method significantly outperforms existing LLM-based approaches in solving MAPF problems.
MASLab: A Unified and Comprehensive Codebase for LLM-based Multi-Agent Systems
May 22, 2025LLM-based multi-agent systems (MAS) have demonstrated significant potential in enhancing single LLMs to address complex and diverse tasks in practical applications. Despite considerable advancements, the field lacks a unified codebase that consolidates existing methods, resulting in redundant re-implementation efforts, unfair comparisons, and high entry barriers for researchers. To address these challenges, we introduce MASLab, a unified, comprehensive, and research-friendly codebase for LLM-based MAS. (1) MASLab integrates over 20 established methods across multiple domains, each rigorously validated by comparing step-by-step outputs with its official implementation. (2) MASLab provides a unified environment with various benchmarks for fair comparisons among methods, ensuring consistent inputs and standardized evaluation protocols. (3) MASLab implements methods within a shared streamlined structure, lowering the barriers for understanding and extension. Building on MASLab, we conduct extensive experiments covering 10+ benchmarks and 8 models, offering researchers a clear and comprehensive view of the current landscape of MAS methods. MASLab will continue to evolve, tracking the latest developments in the field, and invite contributions from the broader open-source community.
Hierarchical Consensus-Based Multi-Agent Reinforcement Learning for Multi-Robot Cooperation Tasks
Jul 11, 2024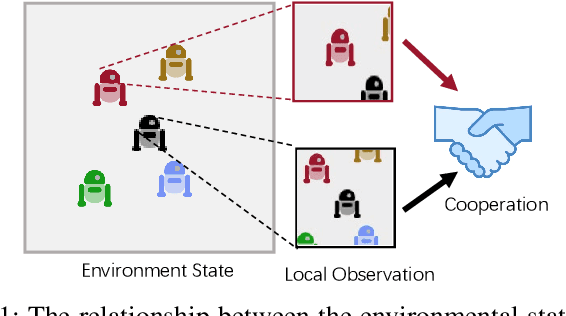
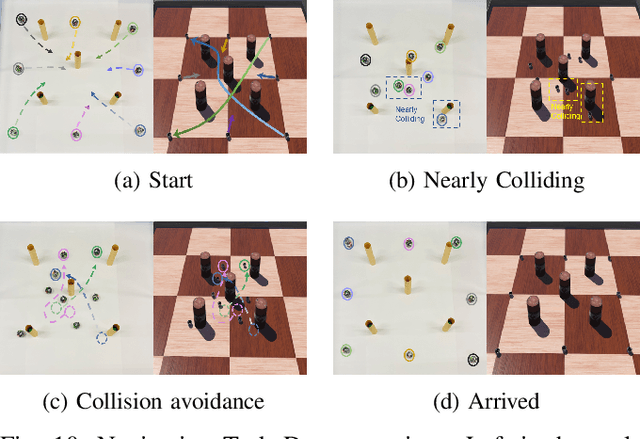

In multi-agent reinforcement learning (MARL), the Centralized Training with Decentralized Execution (CTDE) framework is pivotal but struggles due to a gap: global state guidance in training versus reliance on local observations in execution, lacking global signals. Inspired by human societal consensus mechanisms, we introduce the Hierarchical Consensus-based Multi-Agent Reinforcement Learning (HC-MARL) framework to address this limitation. HC-MARL employs contrastive learning to foster a global consensus among agents, enabling cooperative behavior without direct communication. This approach enables agents to form a global consensus from local observations, using it as an additional piece of information to guide collaborative actions during execution. To cater to the dynamic requirements of various tasks, consensus is divided into multiple layers, encompassing both short-term and long-term considerations. Short-term observations prompt the creation of an immediate, low-layer consensus, while long-term observations contribute to the formation of a strategic, high-layer consensus. This process is further refined through an adaptive attention mechanism that dynamically adjusts the influence of each consensus layer. This mechanism optimizes the balance between immediate reactions and strategic planning, tailoring it to the specific demands of the task at hand. Extensive experiments and real-world applications in multi-robot systems showcase our framework's superior performance, marking significant advancements over baselines.
Leveraging Partial Symmetry for Multi-Agent Reinforcement Learning
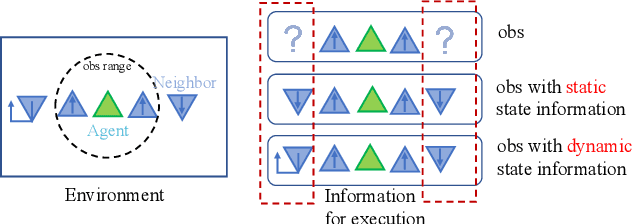
Dec 30, 2023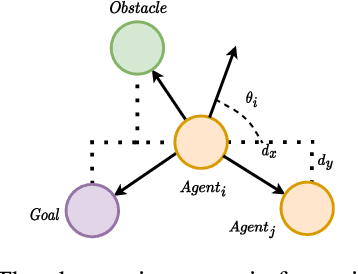
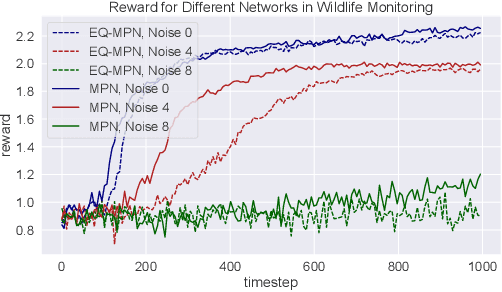

Incorporating symmetry as an inductive bias into multi-agent reinforcement learning (MARL) has led to improvements in generalization, data efficiency, and physical consistency. While prior research has succeeded in using perfect symmetry prior, the realm of partial symmetry in the multi-agent domain remains unexplored. To fill in this gap, we introduce the partially symmetric Markov game, a new subclass of the Markov game. We then theoretically show that the performance error introduced by utilizing symmetry in MARL is bounded, implying that the symmetry prior can still be useful in MARL even in partial symmetry situations. Motivated by this insight, we propose the Partial Symmetry Exploitation (PSE) framework that is able to adaptively incorporate symmetry prior in MARL under different symmetry-breaking conditions. Specifically, by adaptively adjusting the exploitation of symmetry, our framework is able to achieve superior sample efficiency and overall performance of MARL algorithms. Extensive experiments are conducted to demonstrate the superior performance of the proposed framework over baselines. Finally, we implement the proposed framework in real-world multi-robot testbed to show its superiority.
ESP: Exploiting Symmetry Prior for Multi-Agent Reinforcement Learning
Aug 09, 2023



Multi-agent reinforcement learning (MARL) has achieved promising results in recent years. However, most existing reinforcement learning methods require a large amount of data for model training. In addition, data-efficient reinforcement learning requires the construction of strong inductive biases, which are ignored in the current MARL approaches. Inspired by the symmetry phenomenon in multi-agent systems, this paper proposes a framework for exploiting prior knowledge by integrating data augmentation and a well-designed consistency loss into the existing MARL methods. In addition, the proposed framework is model-agnostic and can be applied to most of the current MARL algorithms. Experimental tests on multiple challenging tasks demonstrate the effectiveness of the proposed framework. Moreover, the proposed framework is applied to a physical multi-robot testbed to show its superiority.
Physics-Informed Deep Learning For Traffic State Estimation: A Survey and the Outlook
Mar 03, 2023For its robust predictive power (compared to pure physics-based models) and sample-efficient training (compared to pure deep learning models), physics-informed deep learning (PIDL), a paradigm hybridizing physics-based models and deep neural networks (DNN), has been booming in science and engineering fields. One key challenge of applying PIDL to various domains and problems lies in the design of a computational graph that integrates physics and DNNs. In other words, how physics are encoded into DNNs and how the physics and data components are represented. In this paper, we provide a variety of architecture designs of PIDL computational graphs and how these structures are customized to traffic state estimation (TSE), a central problem in transportation engineering. When observation data, problem type, and goal vary, we demonstrate potential architectures of PIDL computational graphs and compare these variants using the same real-world dataset.
A Physics-Informed Deep Learning Paradigm for Traffic State Estimation and Fundamental Diagram Discovery
Jun 09, 2021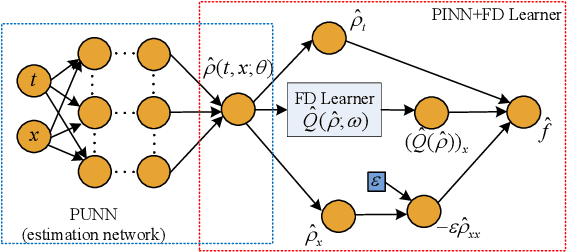
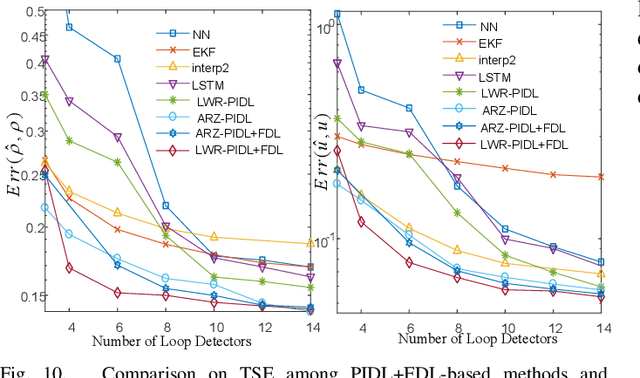


Traffic state estimation (TSE) bifurcates into two main categories, model-driven and data-driven (e.g., machine learning, ML) approaches, while each suffers from either deficient physics or small data. To mitigate these limitations, recent studies introduced hybrid methods, such as physics-informed deep learning (PIDL), which contains both model-driven and data-driven components. This paper contributes an improved paradigm, called physics-informed deep learning with a fundamental diagram learner (PIDL+FDL), which integrates ML terms into the model-driven component to learn a functional form of a fundamental diagram (FD), i.e., a mapping from traffic density to flow or velocity. The proposed PIDL+FDL has the advantages of performing the TSE learning, model parameter discovery, and FD discovery simultaneously. This paper focuses on highway TSE with observed data from loop detectors, using traffic density or velocity as traffic variables. We demonstrate the use of PIDL+FDL to solve popular first-order and second-order traffic flow models and reconstruct the FD relation as well as model parameters that are outside the FD term. We then evaluate the PIDL+FDL-based TSE using the Next Generation SIMulation (NGSIM) dataset. The experimental results show the superiority of the PIDL+FDL in terms of improved estimation accuracy and data efficiency over advanced baseline TSE methods, and additionally, the capacity to properly learn the unknown underlying FD relation.
Physics-Informed Deep Learning for Traffic State Estimation
Jan 17, 2021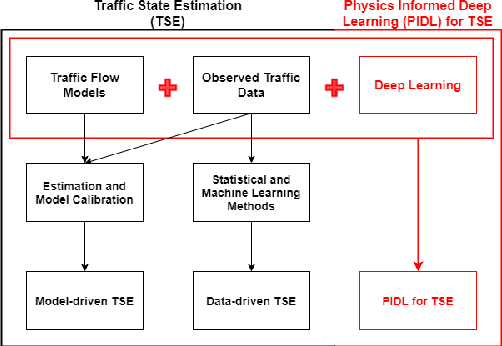
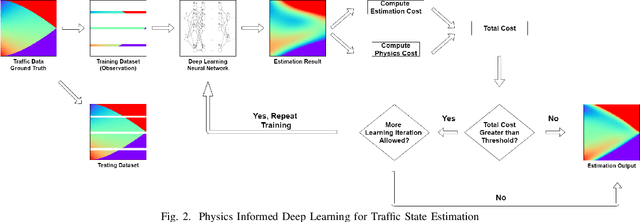

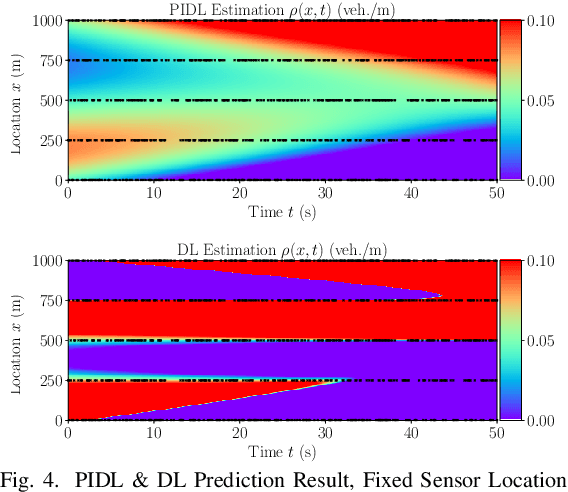
Traffic state estimation (TSE), which reconstructs the traffic variables (e.g., density) on road segments using partially observed data, plays an important role on efficient traffic control and operation that intelligent transportation systems (ITS) need to provide to people. Over decades, TSE approaches bifurcate into two main categories, model-driven approaches and data-driven approaches. However, each of them has limitations: the former highly relies on existing physical traffic flow models, such as Lighthill-Whitham-Richards (LWR) models, which may only capture limited dynamics of real-world traffic, resulting in low-quality estimation, while the latter requires massive data in order to perform accurate and generalizable estimation. To mitigate the limitations, this paper introduces a physics-informed deep learning (PIDL) framework to efficiently conduct high-quality TSE with small amounts of observed data. PIDL contains both model-driven and data-driven components, making possible the integration of the strong points of both approaches while overcoming the shortcomings of either. This paper focuses on highway TSE with observed data from loop detectors, using traffic density as the traffic variables. We demonstrate the use of PIDL to solve (with data from loop detectors) two popular physical traffic flow models, i.e., Greenshields-based LWR and three-parameter-based LWR, and discover the model parameters. We then evaluate the PIDL-based highway TSE using the Next Generation SIMulation (NGSIM) dataset. The experimental results show the advantages of the PIDL-based approach in terms of estimation accuracy and data efficiency over advanced baseline TSE methods.
A Physics-Informed Deep Learning Paradigm for Car-Following Models
Dec 25, 2020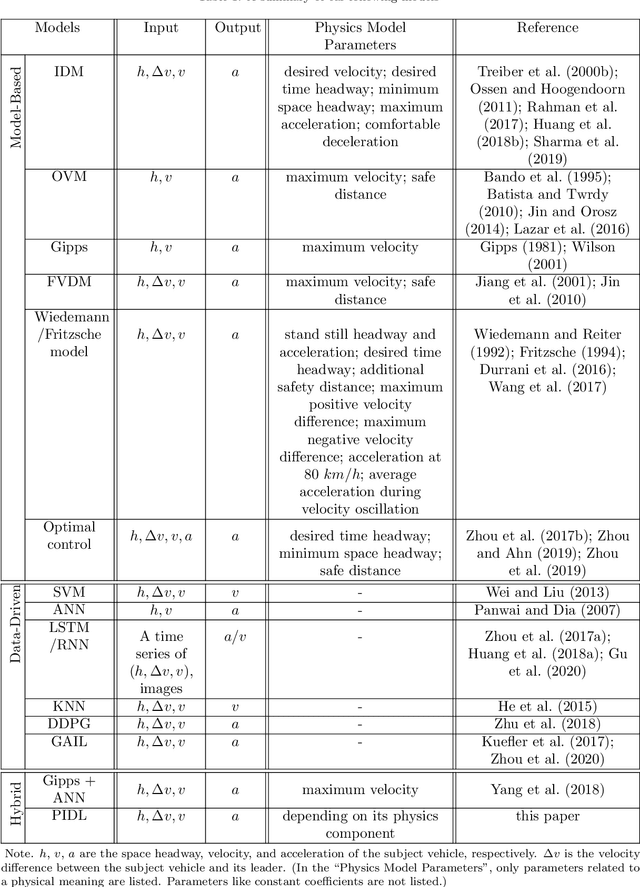



Car-following behavior has been extensively studied using physics-based models, such as the Intelligent Driver Model. These models successfully interpret traffic phenomena observed in the real-world but may not fully capture the complex cognitive process of driving. Deep learning models, on the other hand, have demonstrated their power in capturing observed traffic phenomena but require a large amount of driving data to train. This paper aims to develop a family of neural network based car-following models that are informed by physics-based models, which leverage the advantage of both physics-based (being data-efficient and interpretable) and deep learning based (being generalizable) models. We design physics-informed deep learning for car-following (PIDL-CF) architectures encoded with two popular physics-based models - IDM and OVM, on which acceleration is predicted for four traffic regimes: acceleration, deceleration, cruising, and emergency braking. Two types of PIDL-CFM problems are studied, one to predict acceleration only and the other to jointly predict acceleration and discover model parameters. We also demonstrate the superior performance of PIDL with the Next Generation SIMulation (NGSIM) dataset over baselines, especially when the training data is sparse. The results demonstrate the superior performance of neural networks informed by physics over those without. The developed PIDL-CF framework holds the potential for system identification of driving models and for the development of driving-based controls for automated vehicles.
A Survey on Autonomous Vehicle Control in the Era of Mixed-Autonomy: From Physics-Based to AI-Guided Driving Policy Learning
Jul 10, 2020

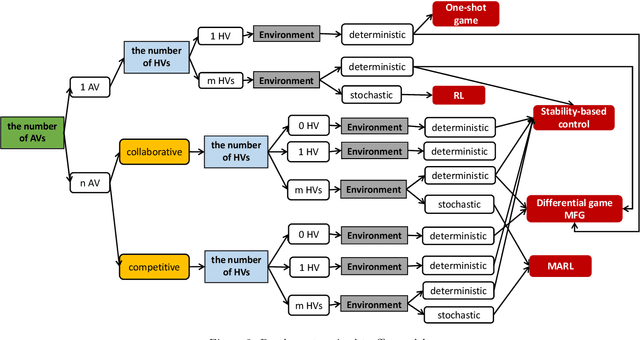
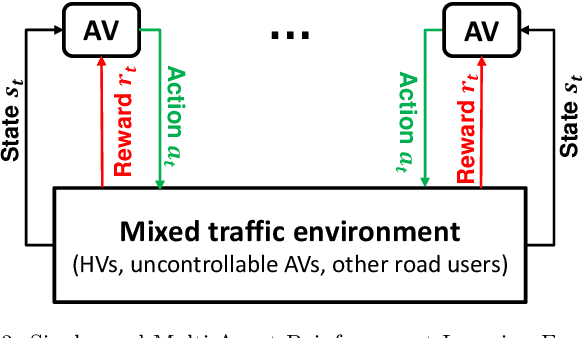
This paper serves as an introduction and overview of the potentially useful models and methodologies from artificial intelligence (AI) into the field of transportation engineering for autonomous vehicle (AV) control in the era of mixed autonomy. We will discuss state-of-the-art applications of AI-guided methods, identify opportunities and obstacles, raise open questions, and help suggest the building blocks and areas where AI could play a role in mixed autonomy. We divide the stage of autonomous vehicle (AV) deployment into four phases: the pure HVs, the HV-dominated, the AVdominated, and the pure AVs. This paper is primarily focused on the latter three phases. It is the first-of-its-kind survey paper to comprehensively review literature in both transportation engineering and AI for mixed traffic modeling. Models used for each phase are summarized, encompassing game theory, deep (reinforcement) learning, and imitation learning. While reviewing the methodologies, we primarily focus on the following research questions: (1) What scalable driving policies are to control a large number of AVs in mixed traffic comprised of human drivers and uncontrollable AVs? (2) How do we estimate human driver behaviors? (3) How should the driving behavior of uncontrollable AVs be modeled in the environment? (4) How are the interactions between human drivers and autonomous vehicles characterized? Hopefully this paper will not only inspire our transportation community to rethink the conventional models that are developed in the data-shortage era, but also reach out to other disciplines, in particular robotics and machine learning, to join forces towards creating a safe and efficient mixed traffic ecosystem.