 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Algorithmic Reasoners informed Large Language Model for Multi-Agent Path Finding
Aug 25, 2025The development and application of large language models (LLM) have demonstrated that foundational models can be utilized to solve a wide array of tasks. However, their performance in multi-agent path finding (MAPF) tasks has been less than satisfactory, with only a few studies exploring this area. MAPF is a complex problem requiring both planning and multi-agent coordination. To improve the performance of LLM in MAPF tasks, we propose a novel framework, LLM-NAR, which leverages neural algorithmic reasoners (NAR) to inform LLM for MAPF. LLM-NAR consists of three key components: an LLM for MAPF, a pre-trained graph neural network-based NAR, and a cross-attention mechanism. This is the first work to propose using a neural algorithmic reasoner to integrate GNNs with the map information for MAPF, thereby guiding LLM to achieve superior performance. LLM-NAR can be easily adapted to various LLM models. Both simulation and real-world experiments demonstrate that our method significantly outperforms existing LLM-based approaches in solving MAPF problems.
Vision-fused Attack: Advancing Aggressive and Stealthy Adversarial Text against Neural Machine Translation
Sep 08, 2024
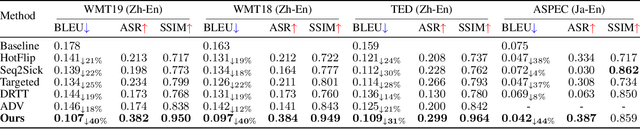
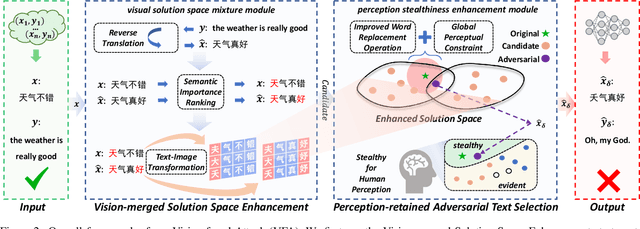
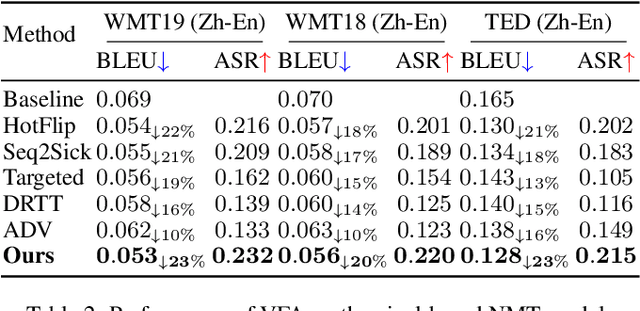
While neural machine translation (NMT) models achieve success in our daily lives, they show vulnerability to adversarial attacks. Despite being harmful, these attacks also offer benefits for interpreting and enhancing NMT models, thus drawing increased research attention. However, existing studies on adversarial attacks are insufficient in both attacking ability and human imperceptibility due to their sole focus on the scope of language. This paper proposes a novel vision-fused attack (VFA) framework to acquire powerful adversarial text, i.e., more aggressive and stealthy. Regarding the attacking ability, we design the vision-merged solution space enhancement strategy to enlarge the limited semantic solution space, which enables us to search for adversarial candidates with higher attacking ability. For human imperceptibility, we propose the perception-retained adversarial text selection strategy to align the human text-reading mechanism. Thus, the finally selected adversarial text could be more deceptive. Extensive experiments on various models, including large language models (LLMs) like LLaMA and GPT-3.5, strongly support that VFA outperforms the comparisons by large margins (up to 81%/14% improvements on ASR/SSIM).
Hierarchical Consensus-Based Multi-Agent Reinforcement Learning for Multi-Robot Cooperation Tasks
Jul 11, 2024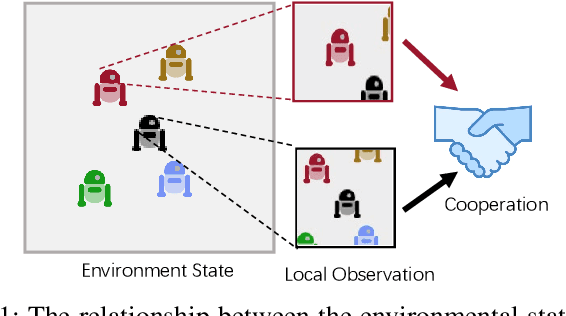
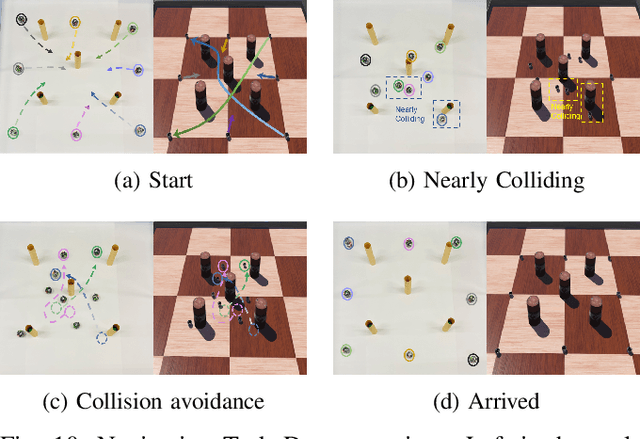
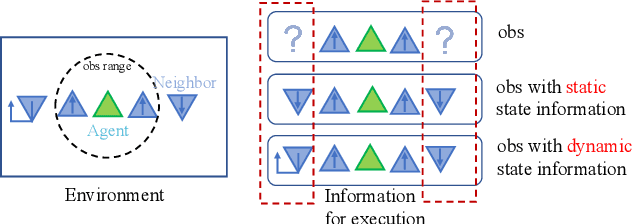

In multi-agent reinforcement learning (MARL), the Centralized Training with Decentralized Execution (CTDE) framework is pivotal but struggles due to a gap: global state guidance in training versus reliance on local observations in execution, lacking global signals. Inspired by human societal consensus mechanisms, we introduce the Hierarchical Consensus-based Multi-Agent Reinforcement Learning (HC-MARL) framework to address this limitation. HC-MARL employs contrastive learning to foster a global consensus among agents, enabling cooperative behavior without direct communication. This approach enables agents to form a global consensus from local observations, using it as an additional piece of information to guide collaborative actions during execution. To cater to the dynamic requirements of various tasks, consensus is divided into multiple layers, encompassing both short-term and long-term considerations. Short-term observations prompt the creation of an immediate, low-layer consensus, while long-term observations contribute to the formation of a strategic, high-layer consensus. This process is further refined through an adaptive attention mechanism that dynamically adjusts the influence of each consensus layer. This mechanism optimizes the balance between immediate reactions and strategic planning, tailoring it to the specific demands of the task at hand. Extensive experiments and real-world applications in multi-robot systems showcase our framework's superior performance, marking significant advancements over baselines.
Leveraging Partial Symmetry for Multi-Agent Reinforcement Learning
Dec 30, 2023

Incorporating symmetry as an inductive bias into multi-agent reinforcement learning (MARL) has led to improvements in generalization, data efficiency, and physical consistency. While prior research has succeeded in using perfect symmetry prior, the realm of partial symmetry in the multi-agent domain remains unexplored. To fill in this gap, we introduce the partially symmetric Markov game, a new subclass of the Markov game. We then theoretically show that the performance error introduced by utilizing symmetry in MARL is bounded, implying that the symmetry prior can still be useful in MARL even in partial symmetry situations. Motivated by this insight, we propose the Partial Symmetry Exploitation (PSE) framework that is able to adaptively incorporate symmetry prior in MARL under different symmetry-breaking conditions. Specifically, by adaptively adjusting the exploitation of symmetry, our framework is able to achieve superior sample efficiency and overall performance of MARL algorithms. Extensive experiments are conducted to demonstrate the superior performance of the proposed framework over baselines. Finally, we implement the proposed framework in real-world multi-robot testbed to show its superiority.
MIR2: Towards Provably Robust Multi-Agent Reinforcement Learning by Mutual Information Regularization
Oct 15, 2023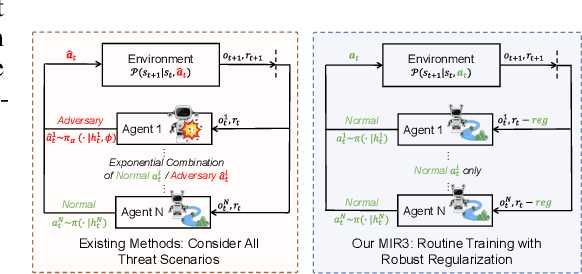


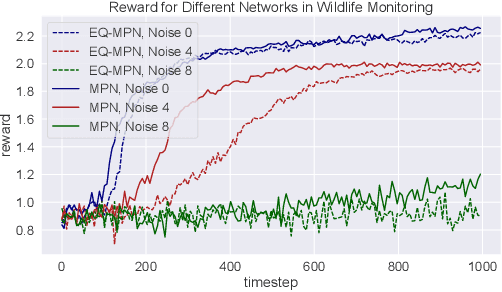
Robust multi-agent reinforcement learning (MARL) necessitates resilience to uncertain or worst-case actions by unknown allies. Existing max-min optimization techniques in robust MARL seek to enhance resilience by training agents against worst-case adversaries, but this becomes intractable as the number of agents grows, leading to exponentially increasing worst-case scenarios. Attempts to simplify this complexity often yield overly pessimistic policies, inadequate robustness across scenarios and high computational demands. Unlike these approaches, humans naturally learn adaptive and resilient behaviors without the necessity of preparing for every conceivable worst-case scenario. Motivated by this, we propose MIR2, which trains policy in routine scenarios and minimize Mutual Information as Robust Regularization. Theoretically, we frame robustness as an inference problem and prove that minimizing mutual information between histories and actions implicitly maximizes a lower bound on robustness under certain assumptions. Further analysis reveals that our proposed approach prevents agents from overreacting to others through an information bottleneck and aligns the policy with a robust action prior. Empirically, our MIR2 displays even greater resilience against worst-case adversaries than max-min optimization in StarCraft II, Multi-agent Mujoco and rendezvous. Our superiority is consistent when deployed in challenging real-world robot swarm control scenario. See code and demo videos in Supplementary Materials.
ESP: Exploiting Symmetry Prior for Multi-Agent Reinforcement Learning
Aug 09, 2023



Multi-agent reinforcement learning (MARL) has achieved promising results in recent years. However, most existing reinforcement learning methods require a large amount of data for model training. In addition, data-efficient reinforcement learning requires the construction of strong inductive biases, which are ignored in the current MARL approaches. Inspired by the symmetry phenomenon in multi-agent systems, this paper proposes a framework for exploiting prior knowledge by integrating data augmentation and a well-designed consistency loss into the existing MARL methods. In addition, the proposed framework is model-agnostic and can be applied to most of the current MARL algorithms. Experimental tests on multiple challenging tasks demonstrate the effectiveness of the proposed framework. Moreover, the proposed framework is applied to a physical multi-robot testbed to show its superiority.
Towards Benchmarking and Assessing Visual Naturalness of Physical World Adversarial Attacks
May 22, 2023Physical world adversarial attack is a highly practical and threatening attack, which fools real world deep learning systems by generating conspicuous and maliciously crafted real world artifacts. In physical world attacks, evaluating naturalness is highly emphasized since human can easily detect and remove unnatural attacks. However, current studies evaluate naturalness in a case-by-case fashion, which suffers from errors, bias and inconsistencies. In this paper, we take the first step to benchmark and assess visual naturalness of physical world attacks, taking autonomous driving scenario as the first attempt. First, to benchmark attack naturalness, we contribute the first Physical Attack Naturalness (PAN) dataset with human rating and gaze. PAN verifies several insights for the first time: naturalness is (disparately) affected by contextual features (i.e., environmental and semantic variations) and correlates with behavioral feature (i.e., gaze signal). Second, to automatically assess attack naturalness that aligns with human ratings, we further introduce Dual Prior Alignment (DPA) network, which aims to embed human knowledge into model reasoning process. Specifically, DPA imitates human reasoning in naturalness assessment by rating prior alignment and mimics human gaze behavior by attentive prior alignment. We hope our work fosters researches to improve and automatically assess naturalness of physical world attacks. Our code and dataset can be found at https://github.com/zhangsn-19/PAN.
Attacking Cooperative Multi-Agent Reinforcement Learning by Adversarial Minority Influence
Feb 07, 2023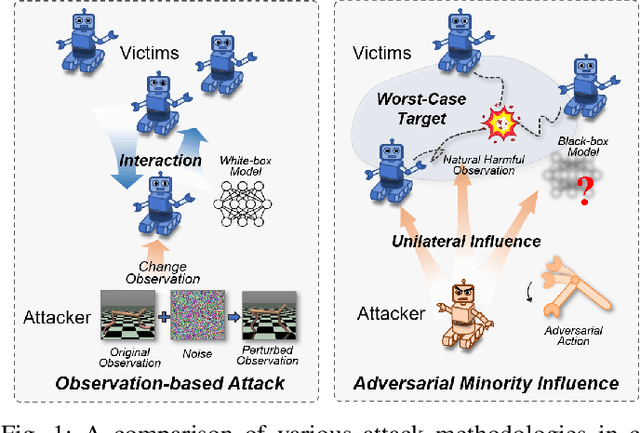


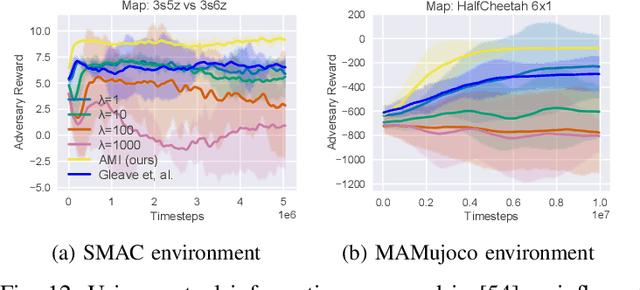
Cooperative multi-agent reinforcement learning (c-MARL) offers a general paradigm for a group of agents to achieve a shared goal by taking individual decisions, yet is found to be vulnerable to adversarial attacks. Though harmful, adversarial attacks also play a critical role in evaluating the robustness and finding blind spots of c-MARL algorithms. However, existing attacks are not sufficiently strong and practical, which is mainly due to the ignorance of complex influence between agents and cooperative nature of victims in c-MARL. In this paper, we propose adversarial minority influence (AMI), the first practical attack against c-MARL by introducing an adversarial agent. AMI addresses the aforementioned problems by unilaterally influencing other cooperative victims to a targeted worst-case cooperation. Technically, to maximally deviate victim policy under complex agent-wise influence, our unilateral attack characterize and maximize the influence from adversary to victims. This is done by adapting a unilateral agent-wise relation metric derived from mutual information, which filters out the detrimental influence from victims to adversary. To fool victims into a jointly worst-case failure, our targeted attack influence victims to a long-term, cooperatively worst case by distracting each victim to a specific target. Such target is learned by a reinforcement learning agent in a trial-and-error process. Extensive experiments in simulation environments, including discrete control (SMAC), continuous control (MAMujoco) and real-world robot swarm control demonstrate the superiority of our AMI approach. Our codes are available in https://anonymous.4open.science/r/AMI.