 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttacking Cooperative Multi-Agent Reinforcement Learning by Adversarial Minority Influence
Paper and Code
Feb 07, 2023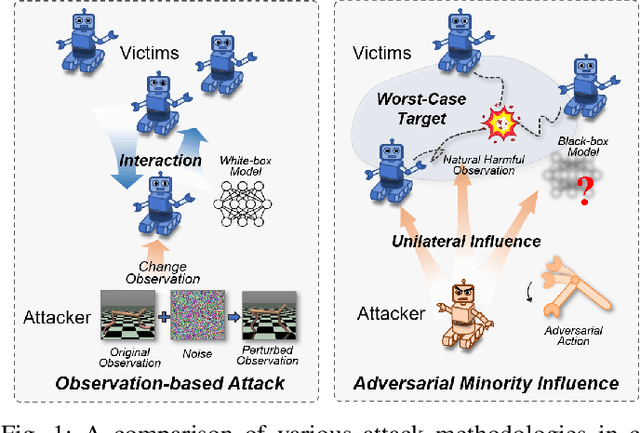


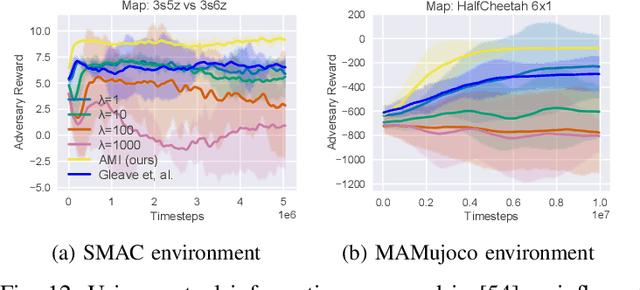
Cooperative multi-agent reinforcement learning (c-MARL) offers a general paradigm for a group of agents to achieve a shared goal by taking individual decisions, yet is found to be vulnerable to adversarial attacks. Though harmful, adversarial attacks also play a critical role in evaluating the robustness and finding blind spots of c-MARL algorithms. However, existing attacks are not sufficiently strong and practical, which is mainly due to the ignorance of complex influence between agents and cooperative nature of victims in c-MARL. In this paper, we propose adversarial minority influence (AMI), the first practical attack against c-MARL by introducing an adversarial agent. AMI addresses the aforementioned problems by unilaterally influencing other cooperative victims to a targeted worst-case cooperation. Technically, to maximally deviate victim policy under complex agent-wise influence, our unilateral attack characterize and maximize the influence from adversary to victims. This is done by adapting a unilateral agent-wise relation metric derived from mutual information, which filters out the detrimental influence from victims to adversary. To fool victims into a jointly worst-case failure, our targeted attack influence victims to a long-term, cooperatively worst case by distracting each victim to a specific target. Such target is learned by a reinforcement learning agent in a trial-and-error process. Extensive experiments in simulation environments, including discrete control (SMAC), continuous control (MAMujoco) and real-world robot swarm control demonstrate the superiority of our AMI approach. Our codes are available in https://anonymous.4open.science/r/AMI.