 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Field Reconstruction via Voronoi-Enhanced Physics-Informed Neural Networks with End-to-End Sensor Placement Optimization
Mar 10, 2026(short version abstract, full in article)High-fidelity flow field reconstruction is important in fluid dynamics, but it is challenged by sparse and spatiotemporally incomplete sensor measurements, as well as failures of pre-deployed measurement points that can invalidate pre-trained reconstruction models. Physics-informed neural networks (PINNs) alleviate dependence on large labeled datasets by incorporating governing physics, yet sensor placement optimization, a key factor in reconstruction accuracy and robustness, remains underexplored. In this study, we propose a PINN with Voronoi-enhanced Sensor Optimization (VSOPINN). VSOPINN enables differentiable soft Voronoi construction for sparse sensor data rasterization, end-to-end fusion of centroidal Voronoi tessellation (CVT) with PINNs for adaptive sensor placement, and unified layout optimization for multi-condition flow reconstruction through a shared encoder-multi-decoder architecture. We validate VSOPINN on three representative problems: lid-driven cavity flow, vascular flow, and annular rotating flow. Results show that VSOPINN significantly improves reconstruction accuracy across different Reynolds numbers, adaptively learns effective sensor layouts, and remains robust under partial sensor failure. The study clarifies the intrinsic relationship between sensor placement and reconstruction precision in PINN-based flow field reconstruction.
MUSA-PINN: Multi-scale Weak-form Physics-Informed Neural Networks for Fluid Flow in Complex Geometries
Mar 10, 2026While Physics-Informed Neural Networks (PINNs) offer a mesh-free approach to solving PDEs, standard point-wise residual minimization suffers from convergence pathologies in topologically complex domains like Triply Periodic Minimal Surfaces (TPMS). The locality bias of point-wise constraints fails to propagate global information through tortuous channels, causing unstable gradients and conservation violations. To address this, we propose the Multi-scale Weak-form PINN (MUSA-PINN), which reformulates PDE constraints as integral conservation laws over hierarchical spherical control volumes. We enforce continuity and momentum conservation via flux-balance residuals on control surfaces. Our method utilizes a three-scale subdomain strategy-comprising large volumes for long-range coupling, skeleton-aware meso-scale volumes aligned with transport pathways, and small volumes for local refinement-alongside a two-stage training schedule prioritizing continuity. Experiments on steady incompressible flow in TPMS geometries show MUSA-PINN outperforms state-of-the-art baselines, reducing relative errors by up to 93% and preserving mass conservation.
A Particle Algorithm for Mean-Field Variational Inference
Dec 29, 2024Variational inference is a fast and scalable alternative to Markov chain Monte Carlo and has been widely applied to posterior inference tasks in statistics and machine learning. A traditional approach for implementing mean-field variational inference (MFVI) is coordinate ascent variational inference (CAVI), which relies crucially on parametric assumptions on complete conditionals. In this paper, we introduce a novel particle-based algorithm for mean-field variational inference, which we term PArticle VI (PAVI). Notably, our algorithm does not rely on parametric assumptions on complete conditionals, and it applies to the nonparametric setting. We provide non-asymptotic finite-particle convergence guarantee for our algorithm. To our knowledge, this is the first end-to-end guarantee for particle-based MFVI.
Which Spaces can be Embedded in $L_p$-type Reproducing Kernel Banach Space? A Characterization via Metric Entropy
Oct 16, 2024
In this paper, we establish a novel connection between the metric entropy growth and the embeddability of function spaces into reproducing kernel Hilbert/Banach spaces. Metric entropy characterizes the information complexity of function spaces and has implications for their approximability and learnability. Classical results show that embedding a function space into a reproducing kernel Hilbert space (RKHS) implies a bound on its metric entropy growth. Surprisingly, we prove a \textbf{converse}: a bound on the metric entropy growth of a function space allows its embedding to a $L_p-$type Reproducing Kernel Banach Space (RKBS). This shows that the ${L}_p-$type RKBS provides a broad modeling framework for learnable function classes with controlled metric entropies. Our results shed new light on the power and limitations of kernel methods for learning complex function spaces.
Which Spaces can be Embedded in $\mathcal{L}_p$-type Reproducing Kernel Banach Space? A Characterization via Metric Entropy
Oct 14, 2024In this paper, we establish a novel connection between the metric entropy growth and the embeddability of function spaces into reproducing kernel Hilbert/Banach spaces. Metric entropy characterizes the information complexity of function spaces and has implications for their approximability and learnability. Classical results show that embedding a function space into a reproducing kernel Hilbert space (RKHS) implies a bound on its metric entropy growth. Surprisingly, we prove a \textbf{converse}: a bound on the metric entropy growth of a function space allows its embedding to a $\mathcal{L}_p-$type Reproducing Kernel Banach Space (RKBS). This shows that the $\mathcal{L}_p-$type RKBS provides a broad modeling framework for learnable function classes with controlled metric entropies. Our results shed new light on the power and limitations of kernel methods for learning complex function spaces.
Discovering State Variables Hidden in Experimental Data
Dec 20, 2021
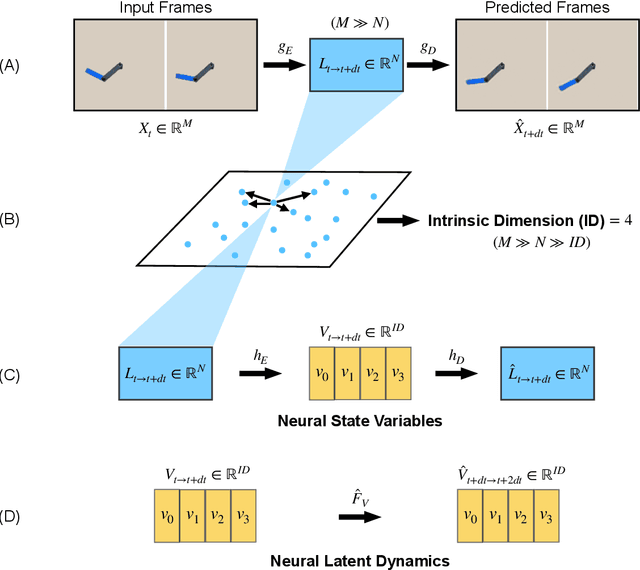
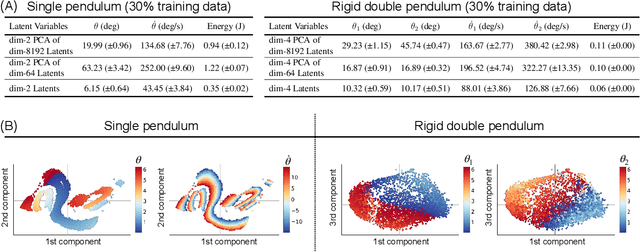
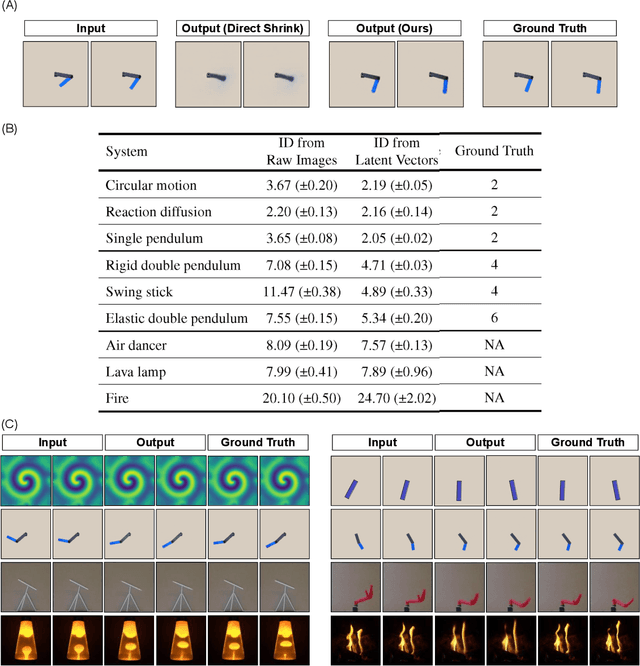
All physical laws are described as relationships between state variables that give a complete and non-redundant description of the relevant system dynamics. However, despite the prevalence of computing power and AI, the process of identifying the hidden state variables themselves has resisted automation. Most data-driven methods for modeling physical phenomena still assume that observed data streams already correspond to relevant state variables. A key challenge is to identify the possible sets of state variables from scratch, given only high-dimensional observational data. Here we propose a new principle for determining how many state variables an observed system is likely to have, and what these variables might be, directly from video streams. We demonstrate the effectiveness of this approach using video recordings of a variety of physical dynamical systems, ranging from elastic double pendulums to fire flames. Without any prior knowledge of the underlying physics, our algorithm discovers the intrinsic dimension of the observed dynamics and identifies candidate sets of state variables. We suggest that this approach could help catalyze the understanding, prediction and control of increasingly complex systems. Project website is at: https://www.cs.columbia.edu/~bchen/neural-state-variables
A Physics-Informed Deep Learning Paradigm for Traffic State Estimation and Fundamental Diagram Discovery
Jun 09, 2021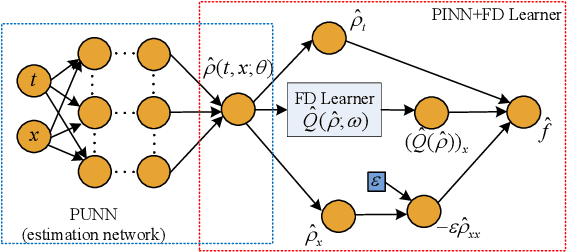
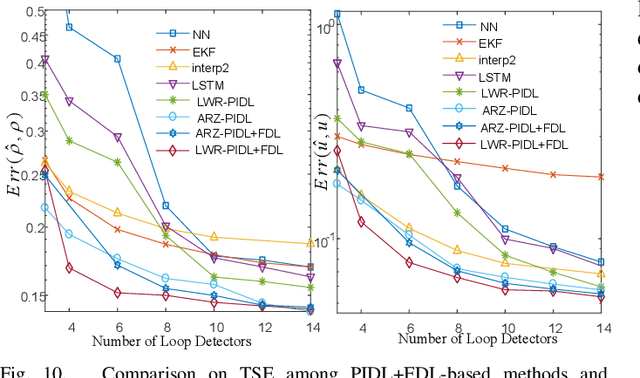


Traffic state estimation (TSE) bifurcates into two main categories, model-driven and data-driven (e.g., machine learning, ML) approaches, while each suffers from either deficient physics or small data. To mitigate these limitations, recent studies introduced hybrid methods, such as physics-informed deep learning (PIDL), which contains both model-driven and data-driven components. This paper contributes an improved paradigm, called physics-informed deep learning with a fundamental diagram learner (PIDL+FDL), which integrates ML terms into the model-driven component to learn a functional form of a fundamental diagram (FD), i.e., a mapping from traffic density to flow or velocity. The proposed PIDL+FDL has the advantages of performing the TSE learning, model parameter discovery, and FD discovery simultaneously. This paper focuses on highway TSE with observed data from loop detectors, using traffic density or velocity as traffic variables. We demonstrate the use of PIDL+FDL to solve popular first-order and second-order traffic flow models and reconstruct the FD relation as well as model parameters that are outside the FD term. We then evaluate the PIDL+FDL-based TSE using the Next Generation SIMulation (NGSIM) dataset. The experimental results show the superiority of the PIDL+FDL in terms of improved estimation accuracy and data efficiency over advanced baseline TSE methods, and additionally, the capacity to properly learn the unknown underlying FD relation.
The Discovery of Dynamics via Linear Multistep Methods and Deep Learning: Error Estimation
Mar 21, 2021
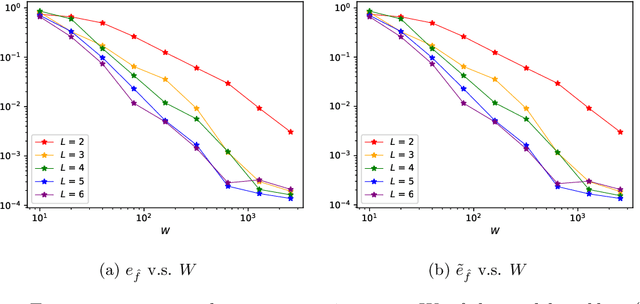
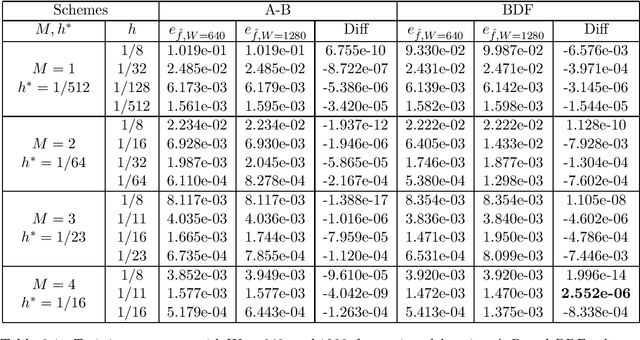
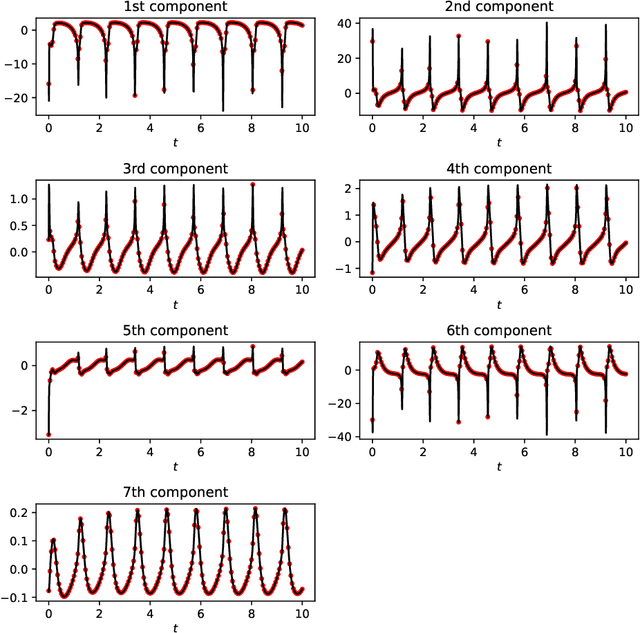
Identifying hidden dynamics from observed data is a significant and challenging task in a wide range of applications. Recently, the combination of linear multistep methods (LMMs) and deep learning has been successfully employed to discover dynamics, whereas a complete convergence analysis of this approach is still under development. In this work, we consider the deep network-based LMMs for the discovery of dynamics. We put forward error estimates for these methods using the approximation property of deep networks. It indicates, for certain families of LMMs, that the $\ell^2$ grid error is bounded by the sum of $O(h^p)$ and the network approximation error, where $h$ is the time step size and $p$ is the local truncation error order. Numerical results of several physically relevant examples are provided to demonstrate our theory.
Physics-Informed Deep Learning for Traffic State Estimation
Jan 17, 2021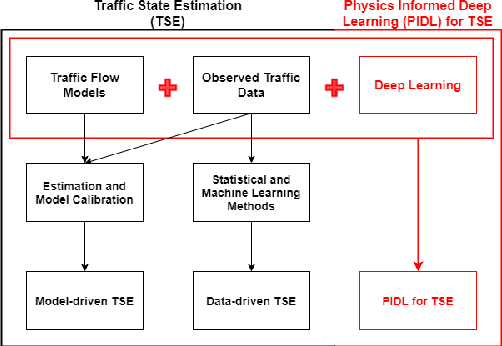
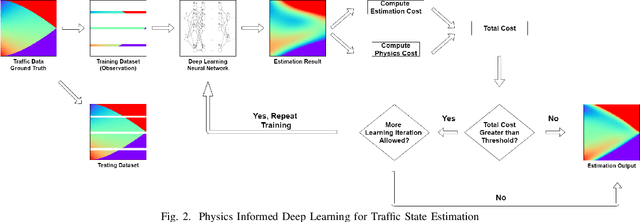

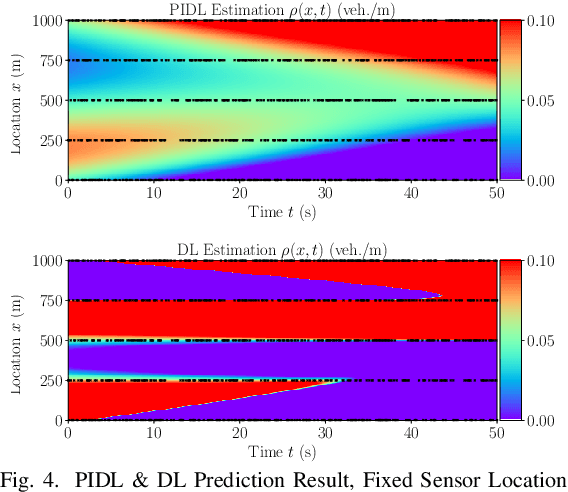
Traffic state estimation (TSE), which reconstructs the traffic variables (e.g., density) on road segments using partially observed data, plays an important role on efficient traffic control and operation that intelligent transportation systems (ITS) need to provide to people. Over decades, TSE approaches bifurcate into two main categories, model-driven approaches and data-driven approaches. However, each of them has limitations: the former highly relies on existing physical traffic flow models, such as Lighthill-Whitham-Richards (LWR) models, which may only capture limited dynamics of real-world traffic, resulting in low-quality estimation, while the latter requires massive data in order to perform accurate and generalizable estimation. To mitigate the limitations, this paper introduces a physics-informed deep learning (PIDL) framework to efficiently conduct high-quality TSE with small amounts of observed data. PIDL contains both model-driven and data-driven components, making possible the integration of the strong points of both approaches while overcoming the shortcomings of either. This paper focuses on highway TSE with observed data from loop detectors, using traffic density as the traffic variables. We demonstrate the use of PIDL to solve (with data from loop detectors) two popular physical traffic flow models, i.e., Greenshields-based LWR and three-parameter-based LWR, and discover the model parameters. We then evaluate the PIDL-based highway TSE using the Next Generation SIMulation (NGSIM) dataset. The experimental results show the advantages of the PIDL-based approach in terms of estimation accuracy and data efficiency over advanced baseline TSE methods.
A non-cooperative meta-modeling game for automated third-party calibrating, validating, and falsifying constitutive laws with parallelized adversarial attacks
Apr 13, 2020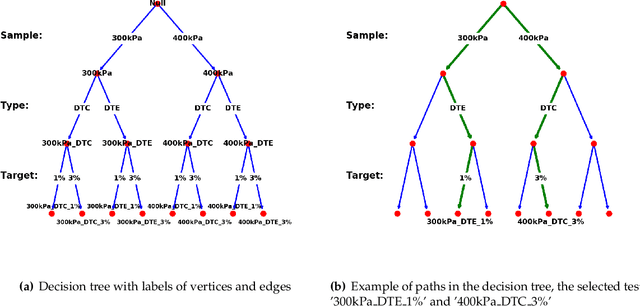
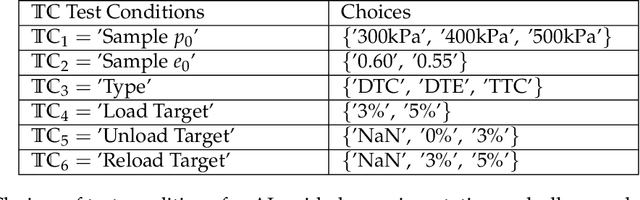
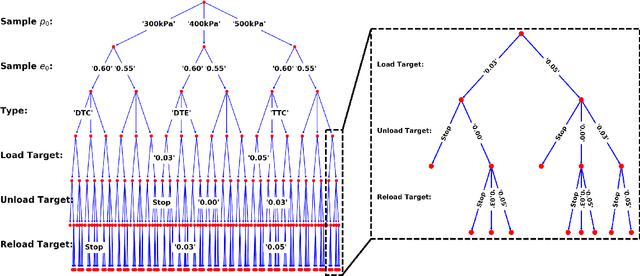
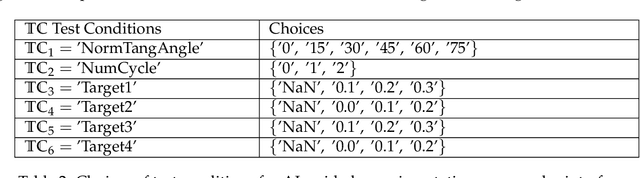
The evaluation of constitutive models, especially for high-risk and high-regret engineering applications, requires efficient and rigorous third-party calibration, validation and falsification. While there are numerous efforts to develop paradigms and standard procedures to validate models, difficulties may arise due to the sequential, manual and often biased nature of the commonly adopted calibration and validation processes, thus slowing down data collections, hampering the progress towards discovering new physics, increasing expenses and possibly leading to misinterpretations of the credibility and application ranges of proposed models. This work attempts to introduce concepts from game theory and machine learning techniques to overcome many of these existing difficulties. We introduce an automated meta-modeling game where two competing AI agents systematically generate experimental data to calibrate a given constitutive model and to explore its weakness, in order to improve experiment design and model robustness through competition. The two agents automatically search for the Nash equilibrium of the meta-modeling game in an adversarial reinforcement learning framework without human intervention. By capturing all possible design options of the laboratory experiments into a single decision tree, we recast the design of experiments as a game of combinatorial moves that can be resolved through deep reinforcement learning by the two competing players. Our adversarial framework emulates idealized scientific collaborations and competitions among researchers to achieve a better understanding of the application range of the learned material laws and prevent misinterpretations caused by conventional AI-based third-party validation.