 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering State Variables Hidden in Experimental Data
Dec 20, 2021
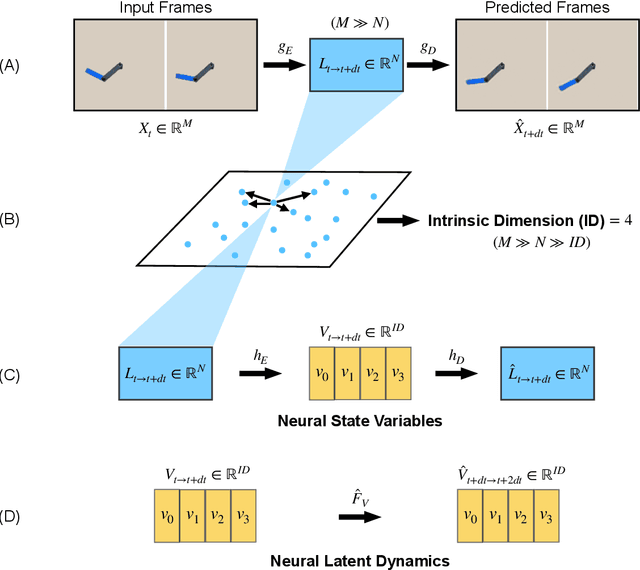
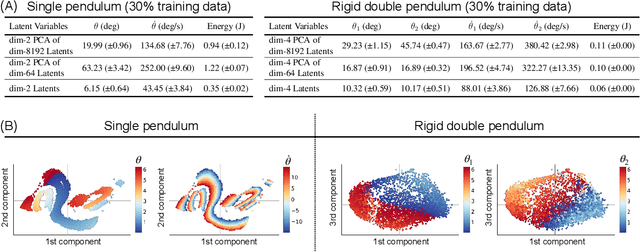
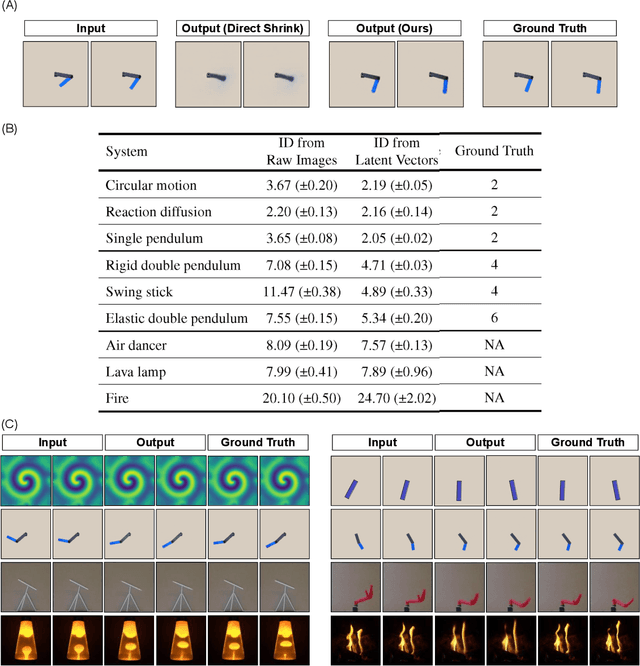
All physical laws are described as relationships between state variables that give a complete and non-redundant description of the relevant system dynamics. However, despite the prevalence of computing power and AI, the process of identifying the hidden state variables themselves has resisted automation. Most data-driven methods for modeling physical phenomena still assume that observed data streams already correspond to relevant state variables. A key challenge is to identify the possible sets of state variables from scratch, given only high-dimensional observational data. Here we propose a new principle for determining how many state variables an observed system is likely to have, and what these variables might be, directly from video streams. We demonstrate the effectiveness of this approach using video recordings of a variety of physical dynamical systems, ranging from elastic double pendulums to fire flames. Without any prior knowledge of the underlying physics, our algorithm discovers the intrinsic dimension of the observed dynamics and identifies candidate sets of state variables. We suggest that this approach could help catalyze the understanding, prediction and control of increasingly complex systems. Project website is at: https://www.cs.columbia.edu/~bchen/neural-state-variables
ClimateGAN: Raising Climate Change Awareness by Generating Images of Floods
Oct 06, 2021
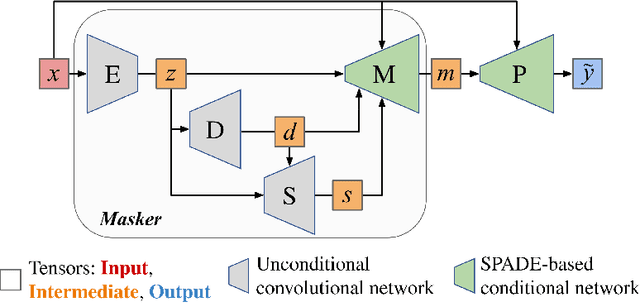

Climate change is a major threat to humanity, and the actions required to prevent its catastrophic consequences include changes in both policy-making and individual behaviour. However, taking action requires understanding the effects of climate change, even though they may seem abstract and distant. Projecting the potential consequences of extreme climate events such as flooding in familiar places can help make the abstract impacts of climate change more concrete and encourage action. As part of a larger initiative to build a website that projects extreme climate events onto user-chosen photos, we present our solution to simulate photo-realistic floods on authentic images. To address this complex task in the absence of suitable training data, we propose ClimateGAN, a model that leverages both simulated and real data for unsupervised domain adaptation and conditional image generation. In this paper, we describe the details of our framework, thoroughly evaluate components of our architecture and demonstrate that our model is capable of robustly generating photo-realistic flooding.
Beyond Categorical Label Representations for Image Classification
Apr 06, 2021We find that the way we choose to represent data labels can have a profound effect on the quality of trained models. For example, training an image classifier to regress audio labels rather than traditional categorical probabilities produces a more reliable classification. This result is surprising, considering that audio labels are more complex than simpler numerical probabilities or text. We hypothesize that high dimensional, high entropy label representations are generally more useful because they provide a stronger error signal. We support this hypothesis with evidence from various label representations including constant matrices, spectrograms, shuffled spectrograms, Gaussian mixtures, and uniform random matrices of various dimensionalities. Our experiments reveal that high dimensional, high entropy labels achieve comparable accuracy to text (categorical) labels on the standard image classification task, but features learned through our label representations exhibit more robustness under various adversarial attacks and better effectiveness with a limited amount of training data. These results suggest that label representation may play a more important role than previously thought. The project website is at \url{https://www.creativemachineslab.com/label-representation.html}.
RealCause: Realistic Causal Inference Benchmarking
Nov 30, 2020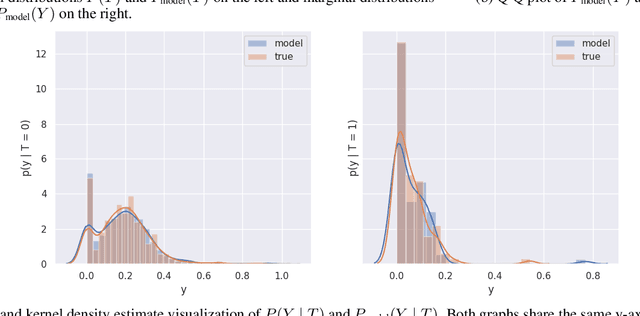
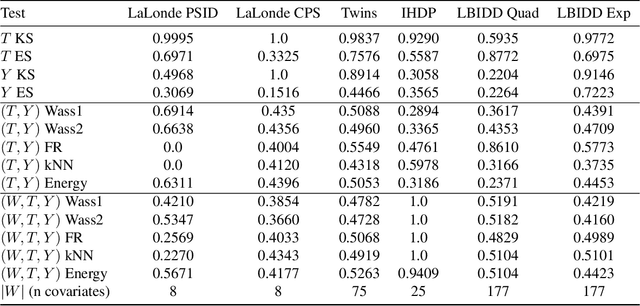
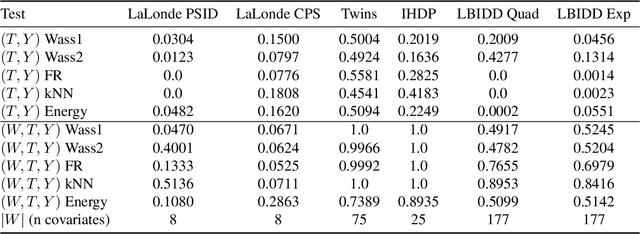
There are many different causal effect estimators in causal inference. However, it is unclear how to choose between these estimators because there is no ground-truth for causal effects. A commonly used option is to simulate synthetic data, where the ground-truth is known. However, the best causal estimators on synthetic data are unlikely to be the best causal estimators on realistic data. An ideal benchmark for causal estimators would both (a) yield ground-truth values of the causal effects and (b) be representative of real data. Using flexible generative models, we provide a benchmark that both yields ground-truth and is realistic. Using this benchmark, we evaluate 66 different causal estimators.