 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERMAID: Memory-Enhanced Retrieval and Reasoning with Multi-Agent Iterative Knowledge Grounding for Veracity Assessment
Jan 29, 2026Assessing the veracity of online content has become increasingly critical. Large language models (LLMs) have recently enabled substantial progress in automated veracity assessment, including automated fact-checking and claim verification systems. Typical veracity assessment pipelines break down complex claims into sub-claims, retrieve external evidence, and then apply LLM reasoning to assess veracity. However, existing methods often treat evidence retrieval as a static, isolated step and do not effectively manage or reuse retrieved evidence across claims. In this work, we propose MERMAID, a memory-enhanced multi-agent veracity assessment framework that tightly couples the retrieval and reasoning processes. MERMAID integrates agent-driven search, structured knowledge representations, and a persistent memory module within a Reason-Action style iterative process, enabling dynamic evidence acquisition and cross-claim evidence reuse. By retaining retrieved evidence in an evidence memory, the framework reduces redundant searches and improves verification efficiency and consistency. We evaluate MERMAID on three fact-checking benchmarks and two claim-verification datasets using multiple LLMs, including GPT, LLaMA, and Qwen families. Experimental results show that MERMAID achieves state-of-the-art performance while improving the search efficiency, demonstrating the effectiveness of synergizing retrieval, reasoning, and memory for reliable veracity assessment.
Latent Theory of Mind: A Decentralized Diffusion Architecture for Cooperative Manipulation
May 14, 2025



We present Latent Theory of Mind (LatentToM), a decentralized diffusion policy architecture for collaborative robot manipulation. Our policy allows multiple manipulators with their own perception and computation to collaborate with each other towards a common task goal with or without explicit communication. Our key innovation lies in allowing each agent to maintain two latent representations: an ego embedding specific to the robot, and a consensus embedding trained to be common to both robots, despite their different sensor streams and poses. We further let each robot train a decoder to infer the other robot's ego embedding from their consensus embedding, akin to theory of mind in latent space. Training occurs centrally, with all the policies' consensus encoders supervised by a loss inspired by sheaf theory, a mathematical theory for clustering data on a topological manifold. Specifically, we introduce a first-order cohomology loss to enforce sheaf-consistent alignment of the consensus embeddings. To preserve the expressiveness of the consensus embedding, we further propose structural constraints based on theory of mind and a directional consensus mechanism. Execution can be fully distributed, requiring no explicit communication between policies. In which case, the information is exchanged implicitly through each robot's sensor stream by observing the actions of the other robots and their effects on the scene. Alternatively, execution can leverage direct communication to share the robots' consensus embeddings, where the embeddings are shared once during each inference step and are aligned using the sheaf Laplacian. In our hardware experiments, LatentToM outperforms a naive decentralized diffusion baseline, and shows comparable performance with a state-of-the-art centralized diffusion policy for bi-manual manipulation. Project website: https://stanfordmsl.github.io/LatentToM/.
Demystifying Diffusion Policies: Action Memorization and Simple Lookup Table Alternatives
May 09, 2025Diffusion policies have demonstrated remarkable dexterity and robustness in intricate, high-dimensional robot manipulation tasks, while training from a small number of demonstrations. However, the reason for this performance remains a mystery. In this paper, we offer a surprising hypothesis: diffusion policies essentially memorize an action lookup table -- and this is beneficial. We posit that, at runtime, diffusion policies find the closest training image to the test image in a latent space, and recall the associated training action sequence, offering reactivity without the need for action generalization. This is effective in the sparse data regime, where there is not enough data density for the model to learn action generalization. We support this claim with systematic empirical evidence. Even when conditioned on wildly out of distribution (OOD) images of cats and dogs, the Diffusion Policy still outputs an action sequence from the training data. With this insight, we propose a simple policy, the Action Lookup Table (ALT), as a lightweight alternative to the Diffusion Policy. Our ALT policy uses a contrastive image encoder as a hash function to index the closest corresponding training action sequence, explicitly performing the computation that the Diffusion Policy implicitly learns. We show empirically that for relatively small datasets, ALT matches the performance of a diffusion model, while requiring only 0.0034 of the inference time and 0.0085 of the memory footprint, allowing for much faster closed-loop inference with resource constrained robots. We also train our ALT policy to give an explicit OOD flag when the distance between the runtime image is too far in the latent space from the training images, giving a simple but effective runtime monitor. More information can be found at: https://stanfordmsl.github.io/alt/.
SIGMA: Sheaf-Informed Geometric Multi-Agent Pathfinding
Feb 10, 2025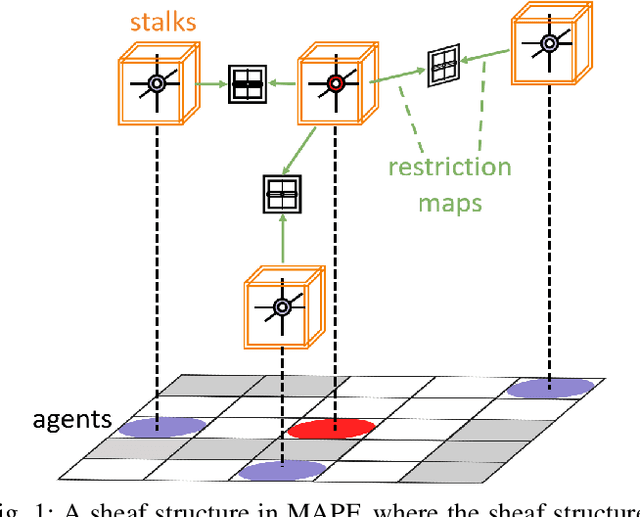



The Multi-Agent Path Finding (MAPF) problem aims to determine the shortest and collision-free paths for multiple agents in a known, potentially obstacle-ridden environment. It is the core challenge for robotic deployments in large-scale logistics and transportation. Decentralized learning-based approaches have shown great potential for addressing the MAPF problems, offering more reactive and scalable solutions. However, existing learning-based MAPF methods usually rely on agents making decisions based on a limited field of view (FOV), resulting in short-sighted policies and inefficient cooperation in complex scenarios. There, a critical challenge is to achieve consensus on potential movements between agents based on limited observations and communications. To tackle this challenge, we introduce a new framework that applies sheaf theory to decentralized deep reinforcement learning, enabling agents to learn geometric cross-dependencies between each other through local consensus and utilize them for tightly cooperative decision-making. In particular, sheaf theory provides a mathematical proof of conditions for achieving global consensus through local observation. Inspired by this, we incorporate a neural network to approximately model the consensus in latent space based on sheaf theory and train it through self-supervised learning. During the task, in addition to normal features for MAPF as in previous works, each agent distributedly reasons about a learned consensus feature, leading to efficient cooperation on pathfinding and collision avoidance. As a result, our proposed method demonstrates significant improvements over state-of-the-art learning-based MAPF planners, especially in relatively large and complex scenarios, demonstrating its superiority over baselines in various simulations and real-world robot experiments.
Hybrid Training for Enhanced Multi-task Generalization in Multi-agent Reinforcement Learning
Aug 24, 2024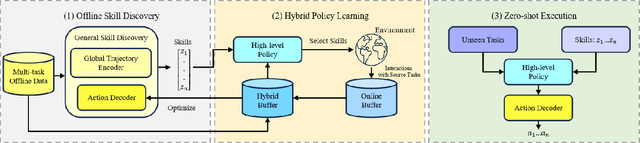
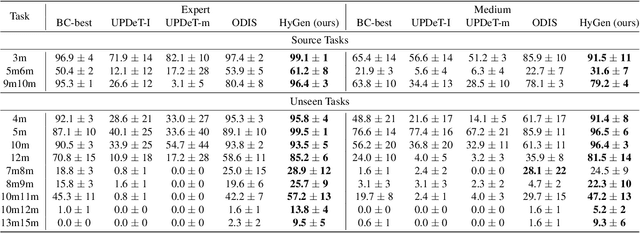
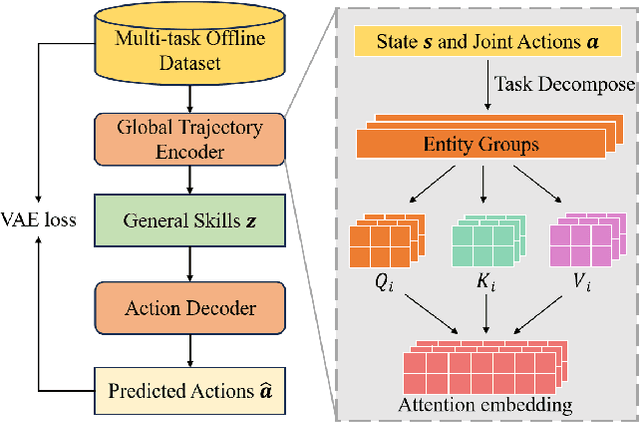
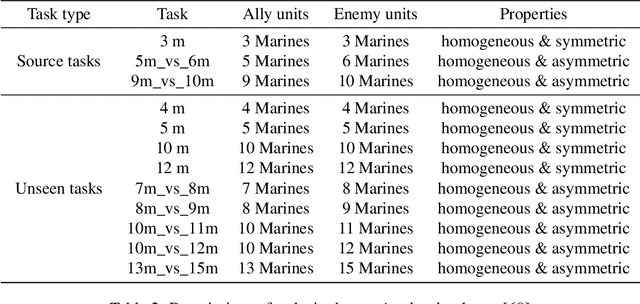
In multi-agent reinforcement learning (MARL), achieving multi-task generalization to diverse agents and objectives presents significant challenges. Existing online MARL algorithms primarily focus on single-task performance, but their lack of multi-task generalization capabilities typically results in substantial computational waste and limited real-life applicability. Meanwhile, existing offline multi-task MARL approaches are heavily dependent on data quality, often resulting in poor performance on unseen tasks. In this paper, we introduce HyGen, a novel hybrid MARL framework, Hybrid Training for Enhanced Multi-Task Generalization, which integrates online and offline learning to ensure both multi-task generalization and training efficiency. Specifically, our framework extracts potential general skills from offline multi-task datasets. We then train policies to select the optimal skills under the centralized training and decentralized execution paradigm (CTDE). During this stage, we utilize a replay buffer that integrates both offline data and online interactions. We empirically demonstrate that our framework effectively extracts and refines general skills, yielding impressive generalization to unseen tasks. Comparative analyses on the StarCraft multi-agent challenge show that HyGen outperforms a wide range of existing solely online and offline methods.
Social Behavior as a Key to Learning-based Multi-Agent Pathfinding Dilemmas
Aug 06, 2024The Multi-agent Path Finding (MAPF) problem involves finding collision-free paths for a team of agents in a known, static environment, with important applications in warehouse automation, logistics, or last-mile delivery. To meet the needs of these large-scale applications, current learning-based methods often deploy the same fully trained, decentralized network to all agents to improve scalability. However, such parameter sharing typically results in homogeneous behaviors among agents, which may prevent agents from breaking ties around symmetric conflict (e.g., bottlenecks) and might lead to live-/deadlocks. In this paper, we propose SYLPH, a novel learning-based MAPF framework aimed to mitigate the adverse effects of homogeneity by allowing agents to learn and dynamically select different social behaviors (akin to individual, dynamic roles), without affecting the scalability offered by parameter sharing. Specifically, SYLPH agents learn to select their Social Value Orientation (SVO) given the situation at hand, quantifying their own level of selfishness/altruism, as well as an SVO-conditioned MAPF policy dictating their movement actions. To these ends, each agent first determines the most influential other agent in the system by predicting future conflicts/interactions with other agents. Each agent selects its own SVO towards that agent, and trains its decentralized MAPF policy to enact this SVO until another agent becomes more influential. To further allow agents to consider each others' social preferences, each agent gets access to the SVO value of their neighbors. As a result of this hierarchical decision-making and exchange of social preferences, SYLPH endows agents with the ability to reason about the MAPF task through more latent spaces and nuanced contexts, leading to varied responses that can help break ties around symmetric conflicts. [...]
ALPHA: Attention-based Long-horizon Pathfinding in Highly-structured Areas
Oct 12, 2023The multi-agent pathfinding (MAPF) problem seeks collision-free paths for a team of agents from their current positions to their pre-set goals in a known environment, and is an essential problem found at the core of many logistics, transportation, and general robotics applications. Existing learning-based MAPF approaches typically only let each agent make decisions based on a limited field-of-view (FOV) around its position, as a natural means to fix the input dimensions of its policy network. However, this often makes policies short-sighted, since agents lack the ability to perceive and plan for obstacles/agents beyond their FOV. To address this challenge, we propose ALPHA, a new framework combining the use of ground truth proximal (local) information and fuzzy distal (global) information to let agents sequence local decisions based on the full current state of the system, and avoid such myopicity. We further allow agents to make short-term predictions about each others' paths, as a means to reason about each others' path intentions, thereby enhancing the level of cooperation among agents at the whole system level. Our neural structure relies on a Graph Transformer architecture to allow agents to selectively combine these different sources of information and reason about their inter-dependencies at different spatial scales. Our simulation experiments demonstrate that ALPHA outperforms both globally-guided MAPF solvers and communication-learning based ones, showcasing its potential towards scalability in realistic deployments.