 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTennisExpert: Towards Expert-Level Analytical Sports Video Understanding
Mar 17, 2026Tennis is one of the most widely followed sports, generating extensive broadcast footage with strong potential for professional analysis, automated coaching, and real-time commentary. However, automatic tennis understanding remains underexplored due to two key challenges: (1) the lack of large-scale benchmarks with fine-grained annotations and expert-level commentary, and (2) the difficulty of building accurate yet efficient multimodal systems suitable for real-time deployment. To address these challenges, we introduce TennisVL, a large-scale tennis benchmark comprising over 200 professional matches (471.9 hours) and 40,000+ rally-level clips. Unlike existing commentary datasets that focus on descriptive play-by-play narration, TennisVL emphasizes expert analytical commentary capturing tactical reasoning, player decisions, and match momentum. Furthermore, we propose TennisExpert, a multimodal tennis understanding framework that integrates a video semantic parser with a memory-augmented model built on Qwen3-VL-8B. The parser extracts key match elements (e.g., scores, shot sequences, ball bounces, and player locations), while hierarchical memory modules capture both short- and long-term temporal context. Experiments show that TennisExpert consistently outperforms strong proprietary baselines, including GPT-5, Gemini, and Claude, and demonstrates improved ability to capture tactical context and match dynamics. Our dataset and code are publicly available at https://github.com/LZYAndy/TennisExpert.
Clustering Properties of Self-Supervised Learning
Jan 30, 2025



Self-supervised learning (SSL) methods via joint embedding architectures have proven remarkably effective at capturing semantically rich representations with strong clustering properties, magically in the absence of label supervision. Despite this, few of them have explored leveraging these untapped properties to improve themselves. In this paper, we provide an evidence through various metrics that the encoder's output $encoding$ exhibits superior and more stable clustering properties compared to other components. Building on this insight, we propose a novel positive-feedback SSL method, termed Representation Soft Assignment (ReSA), which leverages the model's clustering properties to promote learning in a self-guided manner. Extensive experiments on standard SSL benchmarks reveal that models pretrained with ReSA outperform other state-of-the-art SSL methods by a significant margin. Finally, we analyze how ReSA facilitates better clustering properties, demonstrating that it effectively enhances clustering performance at both fine-grained and coarse-grained levels, shaping representations that are inherently more structured and semantically meaningful.
TinyLLaVA-Video: A Simple Framework of Small-scale Large Multimodal Models for Video Understanding
Jan 26, 2025



We present the TinyLLaVA-Video, a video understanding model with parameters not exceeding 4B that processes video sequences in a simple manner, without the need for complex architectures, supporting both fps sampling and uniform frame sampling. Our model is characterized by modularity and scalability, allowing training and inference with limited computational resources and enabling users to replace components based on their needs. We validate the effectiveness of this framework through experiments, the best model achieving performance comparable to certain existing 7B models on multiple video understanding benchmarks. The code and training recipes are fully open source, with all components and training data publicly available. We hope this work can serve as a baseline for practitioners exploring small-scale multimodal models for video understanding. It is available at \url{https://github.com/ZhangXJ199/TinyLLaVA-Video}.
TinyLLaVA Factory: A Modularized Codebase for Small-scale Large Multimodal Models
May 20, 2024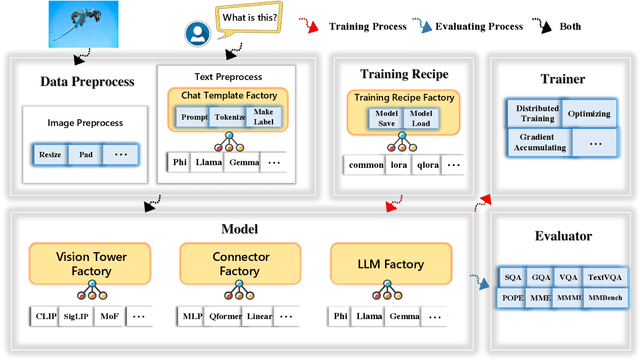
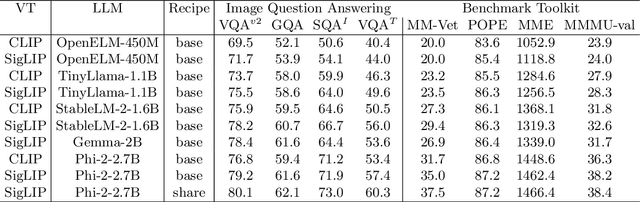
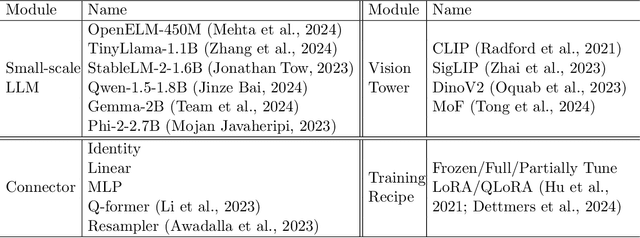
We present TinyLLaVA Factory, an open-source modular codebase for small-scale large multimodal models (LMMs) with a focus on simplicity of code implementations, extensibility of new features, and reproducibility of training results. Following the design philosophy of the factory pattern in software engineering, TinyLLaVA Factory modularizes the entire system into interchangeable components, with each component integrating a suite of cutting-edge models and methods, meanwhile leaving room for extensions to more features. In addition to allowing users to customize their own LMMs, TinyLLaVA Factory provides popular training recipes to let users pretrain and finetune their models with less coding effort. Empirical experiments validate the effectiveness of our codebase. The goal of TinyLLaVA Factory is to assist researchers and practitioners in exploring the wide landscape of designing and training small-scale LMMs with affordable computational resources.
TinyLLaVA: A Framework of Small-scale Large Multimodal Models
Feb 22, 2024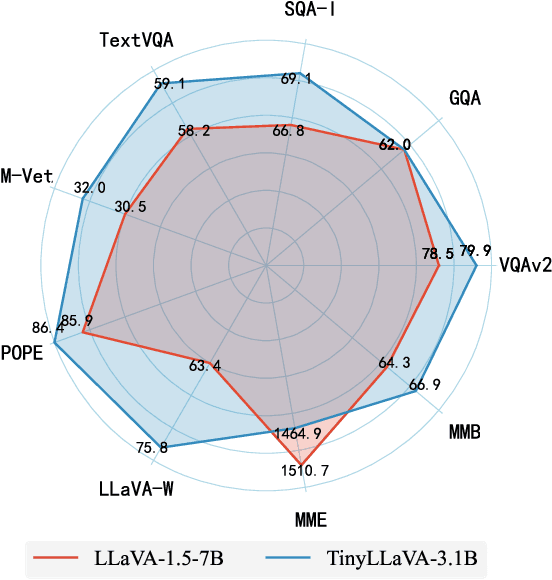
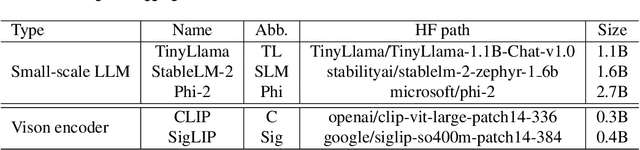
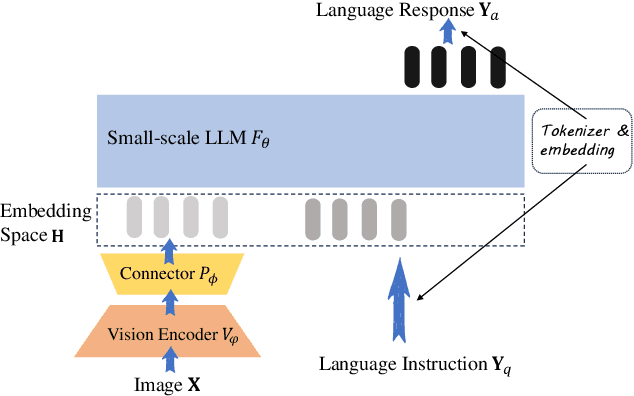

We present the TinyLLaVA framework that provides a unified perspective in designing and analyzing the small-scale Large Multimodal Models (LMMs). We empirically study the effects of different vision encoders, connection modules, language models, training data and training recipes. Our extensive experiments showed that better quality of data combined with better training recipes, smaller LMMs can consistently achieve on-par performances compared to bigger LMMs. Under our framework, we train a family of small-scale LMMs. Our best model, TinyLLaVA-3.1B, achieves better overall performance against existing 7B models such as LLaVA-1.5 and Qwen-VL. We hope our findings can serve as baselines for future research in terms of data scaling, training setups and model selections. Our model weights and codes will be made public.
Modulate Your Spectrum in Self-Supervised Learning
May 26, 2023



Whitening loss provides theoretical guarantee in avoiding feature collapse for self-supervised learning (SSL) using joint embedding architectures. One typical implementation of whitening loss is hard whitening that designs whitening transformation over embedding and imposes the loss on the whitened output. In this paper, we propose spectral transformation (ST) framework to map the spectrum of embedding to a desired distribution during forward pass, and to modulate the spectrum of embedding by implicit gradient update during backward pass. We show that whitening transformation is a special instance of ST by definition, and there exist other instances that can avoid collapse by our empirical investigation. Furthermore, we propose a new instance of ST, called IterNorm with trace loss (INTL). We theoretically prove that INTL can avoid collapse and modulate the spectrum of embedding towards an equal-eigenvalue distribution during the course of optimization. Moreover, INTL achieves 76.6% top-1 accuracy in linear evaluation on ImageNet using ResNet-50, which exceeds the performance of the supervised baseline, and this result is obtained by using a batch size of only 256. Comprehensive experiments show that INTL is a promising SSL method in practice. The code is available at https://github.com/winci-ai/intl.
An Investigation into Whitening Loss for Self-supervised Learning
Oct 07, 2022
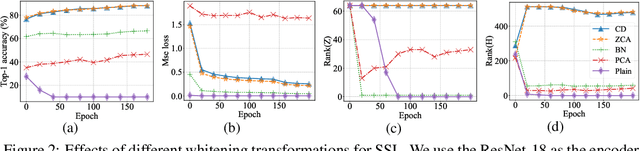


A desirable objective in self-supervised learning (SSL) is to avoid feature collapse. Whitening loss guarantees collapse avoidance by minimizing the distance between embeddings of positive pairs under the conditioning that the embeddings from different views are whitened. In this paper, we propose a framework with an informative indicator to analyze whitening loss, which provides a clue to demystify several interesting phenomena as well as a pivoting point connecting to other SSL methods. We reveal that batch whitening (BW) based methods do not impose whitening constraints on the embedding, but they only require the embedding to be full-rank. This full-rank constraint is also sufficient to avoid dimensional collapse. Based on our analysis, we propose channel whitening with random group partition (CW-RGP), which exploits the advantages of BW-based methods in preventing collapse and avoids their disadvantages requiring large batch size. Experimental results on ImageNet classification and COCO object detection reveal that the proposed CW-RGP possesses a promising potential for learning good representations. The code is available at https://github.com/winci-ai/CW-RGP.
Deep Multi-Branch Aggregation Network for Real-Time Semantic Segmentation in Street Scenes
Mar 08, 2022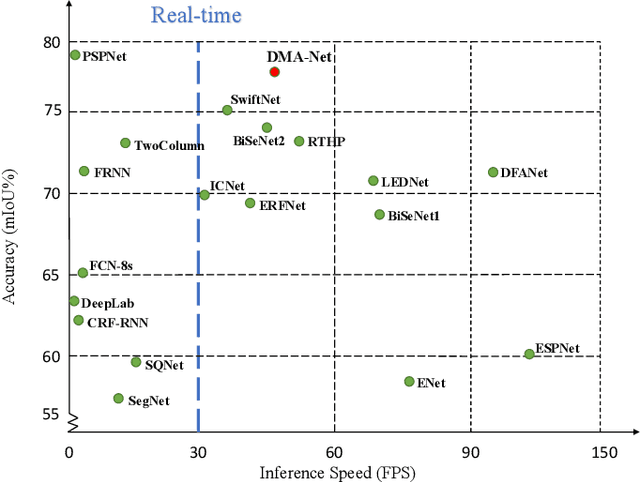


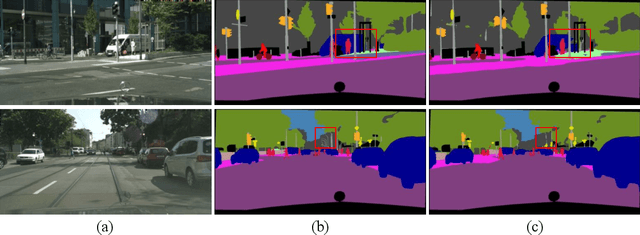
Real-time semantic segmentation, which aims to achieve high segmentation accuracy at real-time inference speed, has received substantial attention over the past few years. However, many state-of-the-art real-time semantic segmentation methods tend to sacrifice some spatial details or contextual information for fast inference, thus leading to degradation in segmentation quality. In this paper, we propose a novel Deep Multi-branch Aggregation Network (called DMA-Net) based on the encoder-decoder structure to perform real-time semantic segmentation in street scenes. Specifically, we first adopt ResNet-18 as the encoder to efficiently generate various levels of feature maps from different stages of convolutions. Then, we develop a Multi-branch Aggregation Network (MAN) as the decoder to effectively aggregate different levels of feature maps and capture the multi-scale information. In MAN, a lattice enhanced residual block is designed to enhance feature representations of the network by taking advantage of the lattice structure. Meanwhile, a feature transformation block is introduced to explicitly transform the feature map from the neighboring branch before feature aggregation. Moreover, a global context block is used to exploit the global contextual information. These key components are tightly combined and jointly optimized in a unified network. Extensive experimental results on the challenging Cityscapes and CamVid datasets demonstrate that our proposed DMA-Net respectively obtains 77.0% and 73.6% mean Intersection over Union (mIoU) at the inference speed of 46.7 FPS and 119.8 FPS by only using a single NVIDIA GTX 1080Ti GPU. This shows that DMA-Net provides a good tradeoff between segmentation quality and speed for semantic segmentation in street scenes.
Stage-Aware Feature Alignment Network for Real-Time Semantic Segmentation of Street Scenes
Mar 08, 2022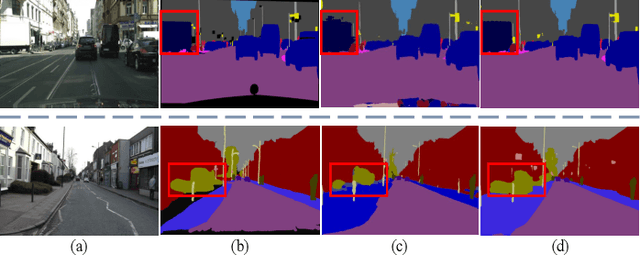

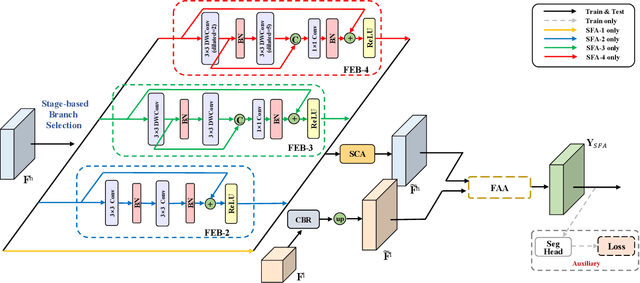
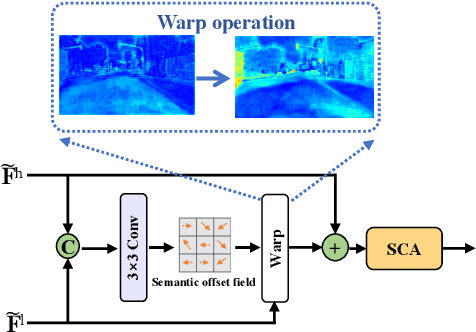
Over the past few years, deep convolutional neural network-based methods have made great progress in semantic segmentation of street scenes. Some recent methods align feature maps to alleviate the semantic gap between them and achieve high segmentation accuracy. However, they usually adopt the feature alignment modules with the same network configuration in the decoder and thus ignore the different roles of stages of the decoder during feature aggregation, leading to a complex decoder structure. Such a manner greatly affects the inference speed. In this paper, we present a novel Stage-aware Feature Alignment Network (SFANet) based on the encoder-decoder structure for real-time semantic segmentation of street scenes. Specifically, a Stage-aware Feature Alignment module (SFA) is proposed to align and aggregate two adjacent levels of feature maps effectively. In the SFA, by taking into account the unique role of each stage in the decoder, a novel stage-aware Feature Enhancement Block (FEB) is designed to enhance spatial details and contextual information of feature maps from the encoder. In this way, we are able to address the misalignment problem with a very simple and efficient multi-branch decoder structure. Moreover, an auxiliary training strategy is developed to explicitly alleviate the multi-scale object problem without bringing additional computational costs during the inference phase. Experimental results show that the proposed SFANet exhibits a good balance between accuracy and speed for real-time semantic segmentation of street scenes. In particular, based on ResNet-18, SFANet respectively obtains 78.1% and 74.7% mean of class-wise Intersection-over-Union (mIoU) at inference speeds of 37 FPS and 96 FPS on the challenging Cityscapes and CamVid test datasets by using only a single GTX 1080Ti GPU.