 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering Properties of Self-Supervised Learning
Jan 30, 2025



Self-supervised learning (SSL) methods via joint embedding architectures have proven remarkably effective at capturing semantically rich representations with strong clustering properties, magically in the absence of label supervision. Despite this, few of them have explored leveraging these untapped properties to improve themselves. In this paper, we provide an evidence through various metrics that the encoder's output $encoding$ exhibits superior and more stable clustering properties compared to other components. Building on this insight, we propose a novel positive-feedback SSL method, termed Representation Soft Assignment (ReSA), which leverages the model's clustering properties to promote learning in a self-guided manner. Extensive experiments on standard SSL benchmarks reveal that models pretrained with ReSA outperform other state-of-the-art SSL methods by a significant margin. Finally, we analyze how ReSA facilitates better clustering properties, demonstrating that it effectively enhances clustering performance at both fine-grained and coarse-grained levels, shaping representations that are inherently more structured and semantically meaningful.
Modularizing while Training: a New Paradigm for Modularizing DNN Models
Jun 15, 2023Deep neural network (DNN) models have become increasingly crucial components in intelligent software systems. However, training a DNN model is typically expensive in terms of both time and money. To address this issue, researchers have recently focused on reusing existing DNN models - borrowing the idea of code reuse in software engineering. However, reusing an entire model could cause extra overhead or inherits the weakness from the undesired functionalities. Hence, existing work proposes to decompose an already trained model into modules, i.e., modularizing-after-training, and enable module reuse. Since trained models are not built for modularization, modularizing-after-training incurs huge overhead and model accuracy loss. In this paper, we propose a novel approach that incorporates modularization into the model training process, i.e., modularizing-while-training (MwT). We train a model to be structurally modular through two loss functions that optimize intra-module cohesion and inter-module coupling. We have implemented the proposed approach for modularizing Convolutional Neural Network (CNN) models in this work. The evaluation results on representative models demonstrate that MwT outperforms the state-of-the-art approach. Specifically, the accuracy loss caused by MwT is only 1.13 percentage points, which is 1.76 percentage points less than that of the baseline. The kernel retention rate of the modules generated by MwT is only 14.58%, with a reduction of 74.31% over the state-of-the-art approach. Furthermore, the total time cost required for training and modularizing is only 108 minutes, half of the baseline.
Reusing Deep Neural Network Models through Model Re-engineering
Apr 01, 2023



Training deep neural network (DNN) models, which has become an important task in today's software development, is often costly in terms of computational resources and time. With the inspiration of software reuse, building DNN models through reusing existing ones has gained increasing attention recently. Prior approaches to DNN model reuse have two main limitations: 1) reusing the entire model, while only a small part of the model's functionalities (labels) are required, would cause much overhead (e.g., computational and time costs for inference), and 2) model reuse would inherit the defects and weaknesses of the reused model, and hence put the new system under threats of security attack. To solve the above problem, we propose SeaM, a tool that re-engineers a trained DNN model to improve its reusability. Specifically, given a target problem and a trained model, SeaM utilizes a gradient-based search method to search for the model's weights that are relevant to the target problem. The re-engineered model that only retains the relevant weights is then reused to solve the target problem. Evaluation results on widely-used models show that the re-engineered models produced by SeaM only contain 10.11% weights of the original models, resulting 42.41% reduction in terms of inference time. For the target problem, the re-engineered models even outperform the original models in classification accuracy by 5.85%. Moreover, reusing the re-engineered models inherits an average of 57% fewer defects than reusing the entire model. We believe our approach to reducing reuse overhead and defect inheritance is one important step forward for practical model reuse.
Patching Weak Convolutional Neural Network Models through Modularization and Composition
Sep 11, 2022
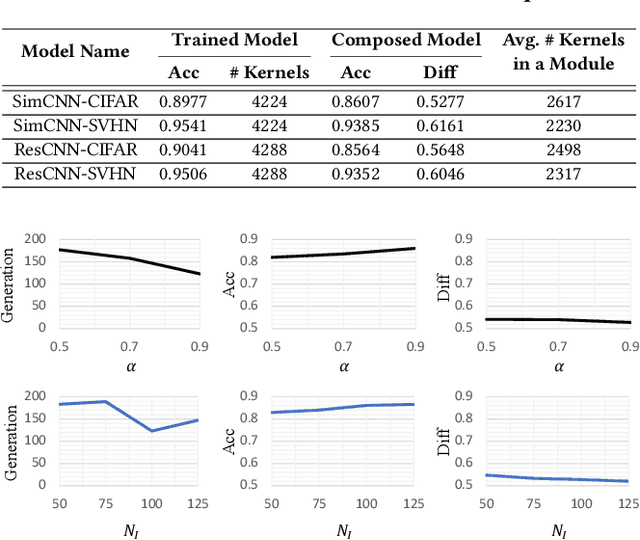
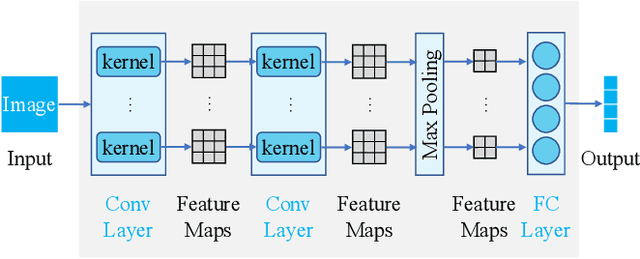

Despite great success in many applications, deep neural networks are not always robust in practice. For instance, a convolutional neuron network (CNN) model for classification tasks often performs unsatisfactorily in classifying some particular classes of objects. In this work, we are concerned with patching the weak part of a CNN model instead of improving it through the costly retraining of the entire model. Inspired by the fundamental concepts of modularization and composition in software engineering, we propose a compressed modularization approach, CNNSplitter, which decomposes a strong CNN model for $N$-class classification into $N$ smaller CNN modules. Each module is a sub-model containing a part of the convolution kernels of the strong model. To patch a weak CNN model that performs unsatisfactorily on a target class (TC), we compose the weak CNN model with the corresponding module obtained from a strong CNN model. The ability of the weak CNN model to recognize the TC can thus be improved through patching. Moreover, the ability to recognize non-TCs is also improved, as the samples misclassified as TC could be classified as non-TCs correctly. Experimental results with two representative CNNs on three widely-used datasets show that the averaged improvement on the TC in terms of precision and recall are 12.54% and 2.14%, respectively. Moreover, patching improves the accuracy of non-TCs by 1.18%. The results demonstrate that CNNSplitter can patch a weak CNN model through modularization and composition, thus providing a new solution for developing robust CNN models.