 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
Scoring, Reasoning, and Selecting the Best! Ensembling Large Language Models via a Peer-Review Process
Dec 29, 2025We propose LLM-PeerReview, an unsupervised LLM Ensemble method that selects the most ideal response from multiple LLM-generated candidates for each query, harnessing the collective wisdom of multiple models with diverse strengths. LLM-PeerReview is built on a novel, peer-review-inspired framework that offers a clear and interpretable mechanism, while remaining fully unsupervised for flexible adaptability and generalization. Specifically, it operates in three stages: For scoring, we use the emerging LLM-as-a-Judge technique to evaluate each response by reusing multiple LLMs at hand; For reasoning, we can apply a principled graphical model-based truth inference algorithm or a straightforward averaging strategy to aggregate multiple scores to produce a final score for each response; Finally, the highest-scoring response is selected as the best ensemble output. LLM-PeerReview is conceptually simple and empirically powerful. The two variants of the proposed approach obtain strong results across four datasets, including outperforming the recent advanced model Smoothie-Global by 6.9% and 7.3% points, respectively.
LLMBoost: Make Large Language Models Stronger with Boosting
Dec 26, 2025Ensemble learning of LLMs has emerged as a promising alternative to enhance performance, but existing approaches typically treat models as black boxes, combining the inputs or final outputs while overlooking the rich internal representations and interactions across models.In this work, we introduce LLMBoost, a novel ensemble fine-tuning framework that breaks this barrier by explicitly leveraging intermediate states of LLMs. Inspired by the boosting paradigm, LLMBoost incorporates three key innovations. First, a cross-model attention mechanism enables successor models to access and fuse hidden states from predecessors, facilitating hierarchical error correction and knowledge transfer. Second, a chain training paradigm progressively fine-tunes connected models with an error-suppression objective, ensuring that each model rectifies the mispredictions of its predecessor with minimal additional computation. Third, a near-parallel inference paradigm design pipelines hidden states across models layer by layer, achieving inference efficiency approaching single-model decoding. We further establish the theoretical foundations of LLMBoost, proving that sequential integration guarantees monotonic improvements under bounded correction assumptions. Extensive experiments on commonsense reasoning and arithmetic reasoning tasks demonstrate that LLMBoost consistently boosts accuracy while reducing inference latency.
Dynamic Benchmark Construction for Evaluating Large Language Models on Real-World Codes
Aug 10, 2025As large language models LLMs) become increasingly integrated into software development workflows, rigorously evaluating their performance on complex, real-world code generation tasks has become essential. However, existing benchmarks often suffer from data contamination and limited test rigor, constraining their ability to reveal model failures effectively. To address these, we present CODE2BENCH, a end-to-end pipeline for dynamically constructing robust and contamination-resistant benchmarks from real-world GitHub repositories. Specifically, CODE2BENCH introduces three key innovations: (1) Automated Dynamism, achieved through periodic ingestion of recent code to minimize training data contamination; (2) Scope Graph-based dependency analysis, which enables structured classification of functions into benchmark instances with controlled dependency levels (distinguishing between Self-Contained (SC) tasks for cross-language evaluation and Weakly Self-Contained (WSC) tasks involving permitted library usage); and (3) Property-Based Testing (PBT) for the automated synthesis of rigorous test suites to enable thorough functional verification. Using this pipeline, we construct CODE2BENCH-2505, the first benchmark derived from 880 recent Python projects spanning diverse domains, comprising 1,163 code generation tasks with 100% average branch coverage on ground-truth implementations. Extensive evaluation of 16 LLMs using CODE2BENCH-2505 reveals that models consistently struggle with SC tasks requiring complex, non-standard logic and cross-language transfer, while showing relatively stronger performance on WSC tasks in Python. Our work introduces a contamination-resistant, language-agnostic methodology for dynamic benchmark construction, offering a principled foundation for the comprehensive and realistic evaluation of LLMs on real-world software development tasks.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Harnessing Multiple Large Language Models: A Survey on LLM Ensemble
Feb 25, 2025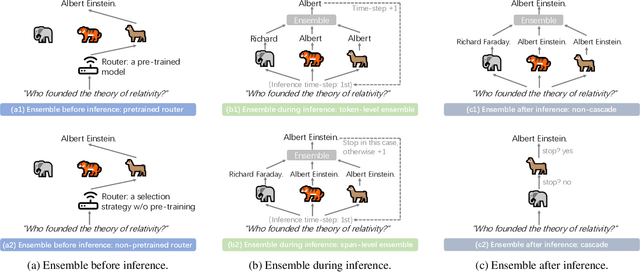
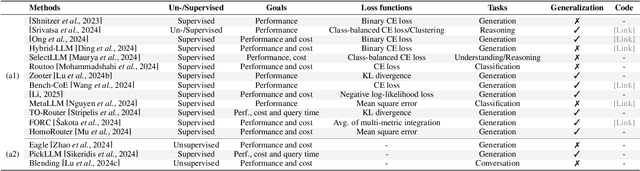
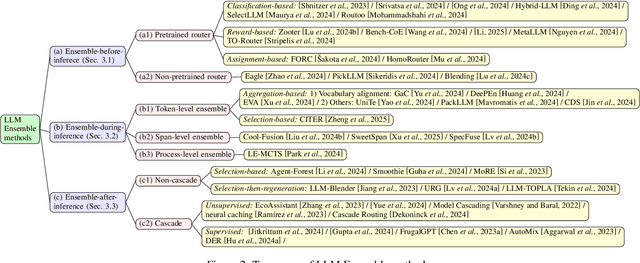
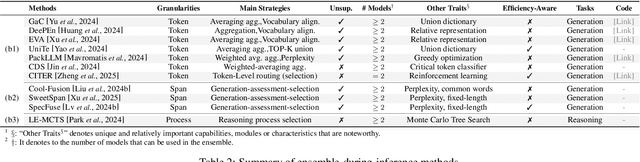
LLM Ensemble -- which involves the comprehensive use of multiple large language models (LLMs), each aimed at handling user queries during downstream inference, to benefit from their individual strengths -- has gained substantial attention recently. The widespread availability of LLMs, coupled with their varying strengths and out-of-the-box usability, has profoundly advanced the field of LLM Ensemble. This paper presents the first systematic review of recent developments in LLM Ensemble. First, we introduce our taxonomy of LLM Ensemble and discuss several related research problems. Then, we provide a more in-depth classification of the methods under the broad categories of "ensemble-before-inference, ensemble-during-inference, ensemble-after-inference", and review all relevant methods. Finally, we introduce related benchmarks and applications, summarize existing studies, and suggest several future research directions. A curated list of papers on LLM Ensemble is available at https://github.com/junchenzhi/Awesome-LLM-Ensemble.
Investigating White-Box Attacks for On-Device Models
Feb 26, 2024



Numerous mobile apps have leveraged deep learning capabilities. However, on-device models are vulnerable to attacks as they can be easily extracted from their corresponding mobile apps. Existing on-device attacking approaches only generate black-box attacks, which are far less effective and efficient than white-box strategies. This is because mobile deep learning frameworks like TFLite do not support gradient computing, which is necessary for white-box attacking algorithms. Thus, we argue that existing findings may underestimate the harmfulness of on-device attacks. To this end, we conduct a study to answer this research question: Can on-device models be directly attacked via white-box strategies? We first systematically analyze the difficulties of transforming the on-device model to its debuggable version, and propose a Reverse Engineering framework for On-device Models (REOM), which automatically reverses the compiled on-device TFLite model to the debuggable model. Specifically, REOM first transforms compiled on-device models into Open Neural Network Exchange format, then removes the non-debuggable parts, and converts them to the debuggable DL models format that allows attackers to exploit in a white-box setting. Our experimental results show that our approach is effective in achieving automated transformation among 244 TFLite models. Compared with previous attacks using surrogate models, REOM enables attackers to achieve higher attack success rates with a hundred times smaller attack perturbations. In addition, because the ONNX platform has plenty of tools for model format exchanging, the proposed method based on the ONNX platform can be adapted to other model formats. Our findings emphasize the need for developers to carefully consider their model deployment strategies, and use white-box methods to evaluate the vulnerability of on-device models.
YAYI 2: Multilingual Open-Source Large Language Models
Dec 22, 2023As the latest advancements in natural language processing, large language models (LLMs) have achieved human-level language understanding and generation abilities in many real-world tasks, and even have been regarded as a potential path to the artificial general intelligence. To better facilitate research on LLMs, many open-source LLMs, such as Llama 2 and Falcon, have recently been proposed and gained comparable performances to proprietary models. However, these models are primarily designed for English scenarios and exhibit poor performances in Chinese contexts. In this technical report, we propose YAYI 2, including both base and chat models, with 30 billion parameters. YAYI 2 is pre-trained from scratch on a multilingual corpus which contains 2.65 trillion tokens filtered by our pre-training data processing pipeline. The base model is aligned with human values through supervised fine-tuning with millions of instructions and reinforcement learning from human feedback. Extensive experiments on multiple benchmarks, such as MMLU and CMMLU, consistently demonstrate that the proposed YAYI 2 outperforms other similar sized open-source models.
Neural-Hidden-CRF: A Robust Weakly-Supervised Sequence Labeler
Sep 28, 2023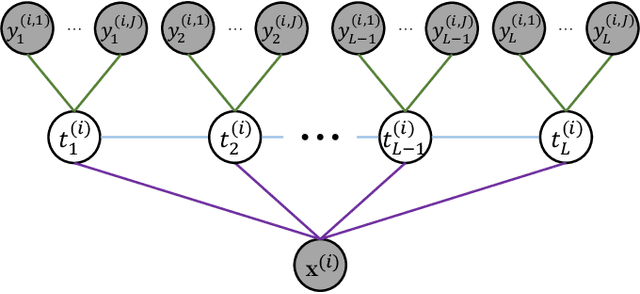

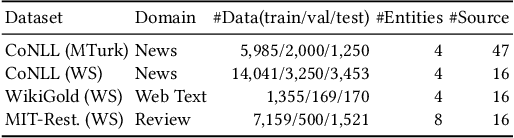
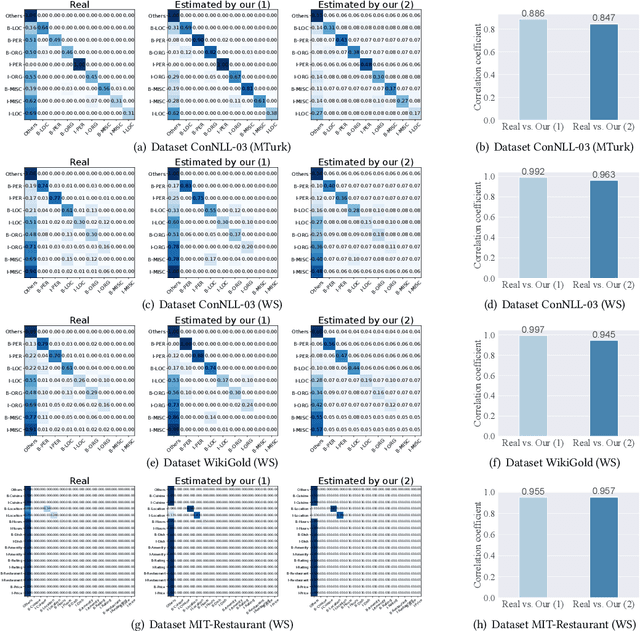
We propose a neuralized undirected graphical model called Neural-Hidden-CRF to solve the weakly-supervised sequence labeling problem. Under the umbrella of probabilistic undirected graph theory, the proposed Neural-Hidden-CRF embedded with a hidden CRF layer models the variables of word sequence, latent ground truth sequence, and weak label sequence with the global perspective that undirected graphical models particularly enjoy. In Neural-Hidden-CRF, we can capitalize on the powerful language model BERT or other deep models to provide rich contextual semantic knowledge to the latent ground truth sequence, and use the hidden CRF layer to capture the internal label dependencies. Neural-Hidden-CRF is conceptually simple and empirically powerful. It obtains new state-of-the-art results on one crowdsourcing benchmark and three weak-supervision benchmarks, including outperforming the recent advanced model CHMM by 2.80 F1 points and 2.23 F1 points in average generalization and inference performance, respectively.
Modularizing while Training: a New Paradigm for Modularizing DNN Models
Jun 15, 2023Deep neural network (DNN) models have become increasingly crucial components in intelligent software systems. However, training a DNN model is typically expensive in terms of both time and money. To address this issue, researchers have recently focused on reusing existing DNN models - borrowing the idea of code reuse in software engineering. However, reusing an entire model could cause extra overhead or inherits the weakness from the undesired functionalities. Hence, existing work proposes to decompose an already trained model into modules, i.e., modularizing-after-training, and enable module reuse. Since trained models are not built for modularization, modularizing-after-training incurs huge overhead and model accuracy loss. In this paper, we propose a novel approach that incorporates modularization into the model training process, i.e., modularizing-while-training (MwT). We train a model to be structurally modular through two loss functions that optimize intra-module cohesion and inter-module coupling. We have implemented the proposed approach for modularizing Convolutional Neural Network (CNN) models in this work. The evaluation results on representative models demonstrate that MwT outperforms the state-of-the-art approach. Specifically, the accuracy loss caused by MwT is only 1.13 percentage points, which is 1.76 percentage points less than that of the baseline. The kernel retention rate of the modules generated by MwT is only 14.58%, with a reduction of 74.31% over the state-of-the-art approach. Furthermore, the total time cost required for training and modularizing is only 108 minutes, half of the baseline.