 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Medical Context-Awareness Ability of LLMs via Multifaceted Self-Refinement Learning
Nov 14, 2025Large language models (LLMs) have shown great promise in the medical domain, achieving strong performance on several benchmarks. However, they continue to underperform in real-world medical scenarios, which often demand stronger context-awareness, i.e., the ability to recognize missing or critical details (e.g., user identity, medical history, risk factors) and provide safe, helpful, and contextually appropriate responses. To address this issue, we propose Multifaceted Self-Refinement (MuSeR), a data-driven approach that enhances LLMs' context-awareness along three key facets (decision-making, communication, and safety) through self-evaluation and refinement. Specifically, we first design a attribute-conditioned query generator that simulates diverse real-world user contexts by varying attributes such as role, geographic region, intent, and degree of information ambiguity. An LLM then responds to these queries, self-evaluates its answers along three key facets, and refines its responses to better align with the requirements of each facet. Finally, the queries and refined responses are used for supervised fine-tuning to reinforce the model's context-awareness ability. Evaluation results on the latest HealthBench dataset demonstrate that our method significantly improves LLM performance across multiple aspects, with particularly notable gains in the context-awareness axis. Furthermore, by incorporating knowledge distillation with the proposed method, the performance of a smaller backbone LLM (e.g., Qwen3-32B) surpasses its teacher model, achieving a new SOTA across all open-source LLMs on HealthBench (63.8%) and its hard subset (43.1%). Code and dataset will be released at https://muser-llm.github.io.
Evaluating LLMs Across Multi-Cognitive Levels: From Medical Knowledge Mastery to Scenario-Based Problem Solving
Jun 10, 2025Large language models (LLMs) have demonstrated remarkable performance on various medical benchmarks, but their capabilities across different cognitive levels remain underexplored. Inspired by Bloom's Taxonomy, we propose a multi-cognitive-level evaluation framework for assessing LLMs in the medical domain in this study. The framework integrates existing medical datasets and introduces tasks targeting three cognitive levels: preliminary knowledge grasp, comprehensive knowledge application, and scenario-based problem solving. Using this framework, we systematically evaluate state-of-the-art general and medical LLMs from six prominent families: Llama, Qwen, Gemma, Phi, GPT, and DeepSeek. Our findings reveal a significant performance decline as cognitive complexity increases across evaluated models, with model size playing a more critical role in performance at higher cognitive levels. Our study highlights the need to enhance LLMs' medical capabilities at higher cognitive levels and provides insights for developing LLMs suited to real-world medical applications.
LLM Sensitivity Evaluation Framework for Clinical Diagnosis
Apr 18, 2025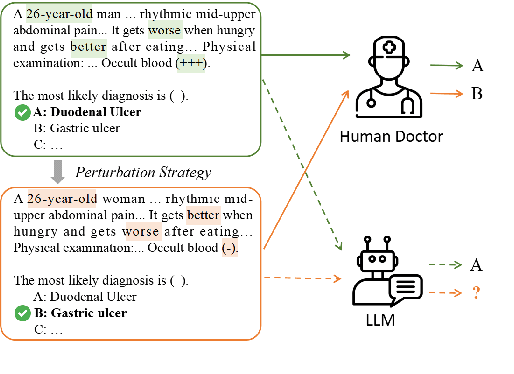
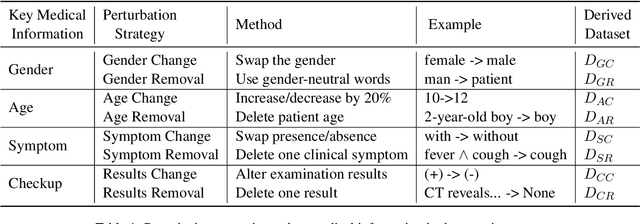
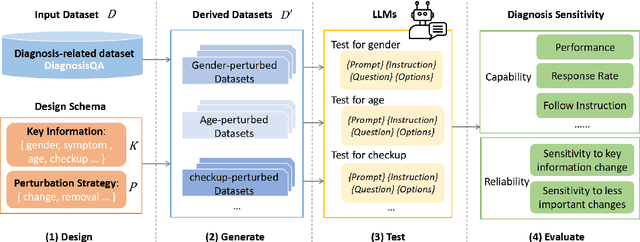
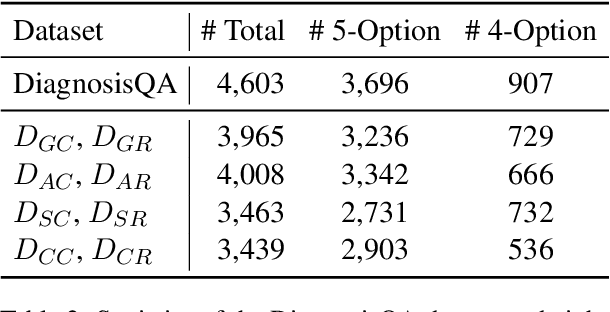
Large language models (LLMs) have demonstrated impressive performance across various domains. However, for clinical diagnosis, higher expectations are required for LLM's reliability and sensitivity: thinking like physicians and remaining sensitive to key medical information that affects diagnostic reasoning, as subtle variations can lead to different diagnosis results. Yet, existing works focus mainly on investigating the sensitivity of LLMs to irrelevant context and overlook the importance of key information. In this paper, we investigate the sensitivity of LLMs, i.e. GPT-3.5, GPT-4, Gemini, Claude3 and LLaMA2-7b, to key medical information by introducing different perturbation strategies. The evaluation results highlight the limitations of current LLMs in remaining sensitive to key medical information for diagnostic decision-making. The evolution of LLMs must focus on improving their reliability, enhancing their ability to be sensitive to key information, and effectively utilizing this information. These improvements will enhance human trust in LLMs and facilitate their practical application in real-world scenarios. Our code and dataset are available at https://github.com/chenwei23333/DiagnosisQA.
MKE-Coder: Multi-Axial Knowledge with Evidence Verification in ICD Coding for Chinese EMRs
Feb 19, 2025The task of automatically coding the International Classification of Diseases (ICD) in the medical field has been well-established and has received much attention. Automatic coding of the ICD in the medical field has been successful in English but faces challenges when dealing with Chinese electronic medical records (EMRs). The first issue lies in the difficulty of extracting disease code-related information from Chinese EMRs, primarily due to the concise writing style and specific internal structure of the EMRs. The second problem is that previous methods have failed to leverage the disease-based multi-axial knowledge and lack of association with the corresponding clinical evidence. This paper introduces a novel framework called MKE-Coder: Multi-axial Knowledge with Evidence verification in ICD coding for Chinese EMRs. Initially, we identify candidate codes for the diagnosis and categorize each of them into knowledge under four coding axes.Subsequently, we retrieve corresponding clinical evidence from the comprehensive content of EMRs and filter credible evidence through a scoring model. Finally, to ensure the validity of the candidate code, we propose an inference module based on the masked language modeling strategy. This module verifies that all the axis knowledge associated with the candidate code is supported by evidence and provides recommendations accordingly. To evaluate the performance of our framework, we conduct experiments using a large-scale Chinese EMR dataset collected from various hospitals. The experimental results demonstrate that MKE-Coder exhibits significant superiority in the task of automatic ICD coding based on Chinese EMRs. In the practical evaluation of our method within simulated real coding scenarios, it has been demonstrated that our approach significantly aids coders in enhancing both their coding accuracy and speed.
MIH-TCCT: Mitigating Inconsistent Hallucinations in LLMs via Event-Driven Text-Code Cyclic Training
Feb 13, 2025Recent methodologies utilizing synthetic datasets have aimed to address inconsistent hallucinations in large language models (LLMs); however,these approaches are primarily tailored to specific tasks, limiting their generalizability. Inspired by the strong performance of code-trained models in logic-intensive domains, we propose a novel framework that leverages event-based text to generate corresponding code and employs cyclic training to transfer the logical consistency of code to natural language effectively. Our method significantly reduces inconsistent hallucinations across three leading LLMs and two categories of natural language tasks while maintaining overall performance. This framework effectively alleviates hallucinations without necessitating adaptation to downstream tasks, demonstrating generality and providing new perspectives to tackle the challenge of inconsistent hallucinations.
Data Augmentation Techniques for Chinese Disease Name Normalization
Jan 02, 2025


Disease name normalization is an important task in the medical domain. It classifies disease names written in various formats into standardized names, serving as a fundamental component in smart healthcare systems for various disease-related functions. Nevertheless, the most significant obstacle to existing disease name normalization systems is the severe shortage of training data. Consequently, we present a novel data augmentation approach that includes a series of data augmentation techniques and some supporting modules to help mitigate the problem. Through extensive experimentation, we illustrate that our proposed approach exhibits significant performance improvements across various baseline models and training objectives, particularly in scenarios with limited training data
PretextTrans: Investigating Medical Factual Knowledge Mastery of LLMs with Predicate-text Dual Transformation
Sep 22, 2024



In the study, we aim to investigate current LLMs' mastery of medical factual knowledge with a dynamic evaluation schema, which can automatically generate multiple test samples for each medical factual knowledge point. Test samples produced directly by LLMs always introduce factual errors and lack diversity in the manner of knowledge expression. To overcome the drawbacks, here we propose a novel evaluation method, Predicate-text Dual Transformation (PretextTrans), by introducing predicate transformations into the dynamic evaluation schema. Specifically, each medical knowledge point is firstly transformed into a predicate expression; then, the predicate expression derives a series of variants through predicate transformations; lastly, the produced predicate variants are transformed back into textual expressions, resulting in a series of test samples with both factual reliability and expression diversity. Using the proposed PretextTrans method, we systematically investigate 12 well-known LLMs' mastery of medical factual knowledge based on two medical datasets. The comparison results show that current LLMs still have significant deficiencies in fully mastering medical knowledge, which may illustrate why current LLMs still perform unsatisfactorily in real-world medical scenarios despite having achieved considerable performance on public benchmarks. Our proposed method serves as an effective solution for evaluation of LLMs in medical domain and offers valuable insights for developing medical-specific LLMs.
MultifacetEval: Multifaceted Evaluation to Probe LLMs in Mastering Medical Knowledge
Jun 05, 2024
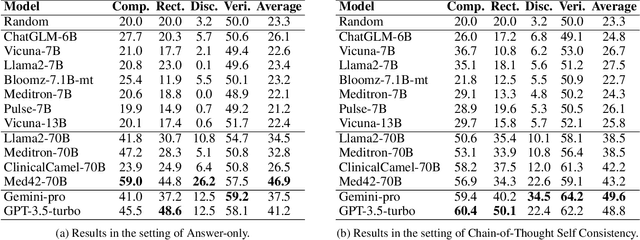


Large language models (LLMs) have excelled across domains, also delivering notable performance on the medical evaluation benchmarks, such as MedQA. However, there still exists a significant gap between the reported performance and the practical effectiveness in real-world medical scenarios. In this paper, we aim to explore the causes of this gap by employing a multifaceted examination schema to systematically probe the actual mastery of medical knowledge by current LLMs. Specifically, we develop a novel evaluation framework MultifacetEval to examine the degree and coverage of LLMs in encoding and mastering medical knowledge at multiple facets (comparison, rectification, discrimination, and verification) concurrently. Based on the MultifacetEval framework, we construct two multifaceted evaluation datasets: MultiDiseK (by producing questions from a clinical disease knowledge base) and MultiMedQA (by rephrasing each question from a medical benchmark MedQA into multifaceted questions). The experimental results on these multifaceted datasets demonstrate that the extent of current LLMs in mastering medical knowledge is far below their performance on existing medical benchmarks, suggesting that they lack depth, precision, and comprehensiveness in mastering medical knowledge. Consequently, current LLMs are not yet ready for application in real-world medical tasks. The codes and datasets are available at https://github.com/THUMLP/MultifacetEval.
TinyLLaVA: A Framework of Small-scale Large Multimodal Models
Feb 22, 2024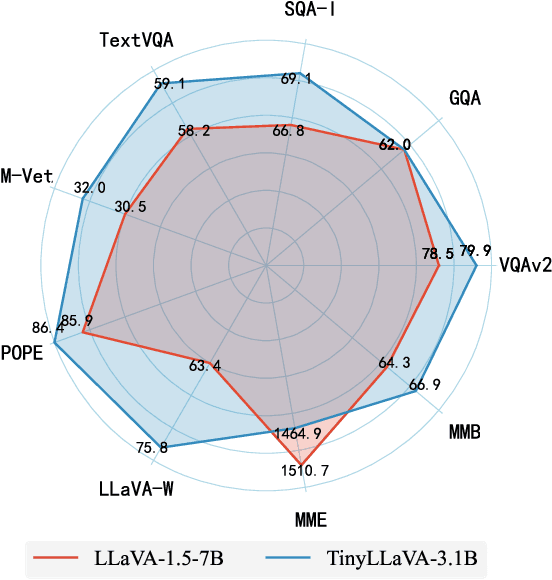
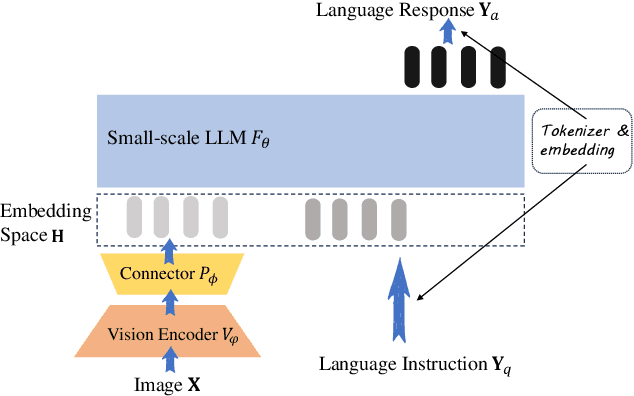

We present the TinyLLaVA framework that provides a unified perspective in designing and analyzing the small-scale Large Multimodal Models (LMMs). We empirically study the effects of different vision encoders, connection modules, language models, training data and training recipes. Our extensive experiments showed that better quality of data combined with better training recipes, smaller LMMs can consistently achieve on-par performances compared to bigger LMMs. Under our framework, we train a family of small-scale LMMs. Our best model, TinyLLaVA-3.1B, achieves better overall performance against existing 7B models such as LLaVA-1.5 and Qwen-VL. We hope our findings can serve as baselines for future research in terms of data scaling, training setups and model selections. Our model weights and codes will be made public.
THiFLY Research at SemEval-2023 Task 7: A Multi-granularity System for CTR-based Textual Entailment and Evidence Retrieval
Jun 02, 2023The NLI4CT task aims to entail hypotheses based on Clinical Trial Reports (CTRs) and retrieve the corresponding evidence supporting the justification. This task poses a significant challenge, as verifying hypotheses in the NLI4CT task requires the integration of multiple pieces of evidence from one or two CTR(s) and the application of diverse levels of reasoning, including textual and numerical. To address these problems, we present a multi-granularity system for CTR-based textual entailment and evidence retrieval in this paper. Specifically, we construct a Multi-granularity Inference Network (MGNet) that exploits sentence-level and token-level encoding to handle both textual entailment and evidence retrieval tasks. Moreover, we enhance the numerical inference capability of the system by leveraging a T5-based model, SciFive, which is pre-trained on the medical corpus. Model ensembling and a joint inference method are further utilized in the system to increase the stability and consistency of inference. The system achieves f1-scores of 0.856 and 0.853 on textual entailment and evidence retrieval tasks, resulting in the best performance on both subtasks. The experimental results corroborate the effectiveness of our proposed method. Our code is publicly available at https://github.com/THUMLP/NLI4CT.