 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultifacetEval: Multifaceted Evaluation to Probe LLMs in Mastering Medical Knowledge
Paper and Code

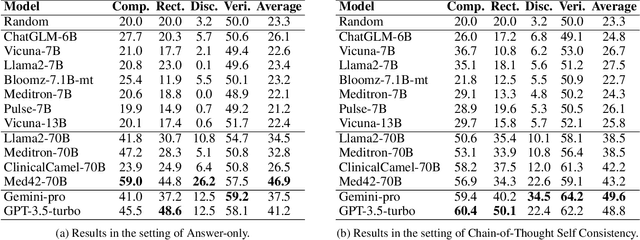


Large language models (LLMs) have excelled across domains, also delivering notable performance on the medical evaluation benchmarks, such as MedQA. However, there still exists a significant gap between the reported performance and the practical effectiveness in real-world medical scenarios. In this paper, we aim to explore the causes of this gap by employing a multifaceted examination schema to systematically probe the actual mastery of medical knowledge by current LLMs. Specifically, we develop a novel evaluation framework MultifacetEval to examine the degree and coverage of LLMs in encoding and mastering medical knowledge at multiple facets (comparison, rectification, discrimination, and verification) concurrently. Based on the MultifacetEval framework, we construct two multifaceted evaluation datasets: MultiDiseK (by producing questions from a clinical disease knowledge base) and MultiMedQA (by rephrasing each question from a medical benchmark MedQA into multifaceted questions). The experimental results on these multifaceted datasets demonstrate that the extent of current LLMs in mastering medical knowledge is far below their performance on existing medical benchmarks, suggesting that they lack depth, precision, and comprehensiveness in mastering medical knowledge. Consequently, current LLMs are not yet ready for application in real-world medical tasks. The codes and datasets are available at https://github.com/THUMLP/MultifacetEval.