 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Medical Context-Awareness Ability of LLMs via Multifaceted Self-Refinement Learning
Nov 14, 2025Large language models (LLMs) have shown great promise in the medical domain, achieving strong performance on several benchmarks. However, they continue to underperform in real-world medical scenarios, which often demand stronger context-awareness, i.e., the ability to recognize missing or critical details (e.g., user identity, medical history, risk factors) and provide safe, helpful, and contextually appropriate responses. To address this issue, we propose Multifaceted Self-Refinement (MuSeR), a data-driven approach that enhances LLMs' context-awareness along three key facets (decision-making, communication, and safety) through self-evaluation and refinement. Specifically, we first design a attribute-conditioned query generator that simulates diverse real-world user contexts by varying attributes such as role, geographic region, intent, and degree of information ambiguity. An LLM then responds to these queries, self-evaluates its answers along three key facets, and refines its responses to better align with the requirements of each facet. Finally, the queries and refined responses are used for supervised fine-tuning to reinforce the model's context-awareness ability. Evaluation results on the latest HealthBench dataset demonstrate that our method significantly improves LLM performance across multiple aspects, with particularly notable gains in the context-awareness axis. Furthermore, by incorporating knowledge distillation with the proposed method, the performance of a smaller backbone LLM (e.g., Qwen3-32B) surpasses its teacher model, achieving a new SOTA across all open-source LLMs on HealthBench (63.8%) and its hard subset (43.1%). Code and dataset will be released at https://muser-llm.github.io.
Evaluating LLMs Across Multi-Cognitive Levels: From Medical Knowledge Mastery to Scenario-Based Problem Solving
Jun 10, 2025Large language models (LLMs) have demonstrated remarkable performance on various medical benchmarks, but their capabilities across different cognitive levels remain underexplored. Inspired by Bloom's Taxonomy, we propose a multi-cognitive-level evaluation framework for assessing LLMs in the medical domain in this study. The framework integrates existing medical datasets and introduces tasks targeting three cognitive levels: preliminary knowledge grasp, comprehensive knowledge application, and scenario-based problem solving. Using this framework, we systematically evaluate state-of-the-art general and medical LLMs from six prominent families: Llama, Qwen, Gemma, Phi, GPT, and DeepSeek. Our findings reveal a significant performance decline as cognitive complexity increases across evaluated models, with model size playing a more critical role in performance at higher cognitive levels. Our study highlights the need to enhance LLMs' medical capabilities at higher cognitive levels and provides insights for developing LLMs suited to real-world medical applications.
PretextTrans: Investigating Medical Factual Knowledge Mastery of LLMs with Predicate-text Dual Transformation
Sep 22, 2024



In the study, we aim to investigate current LLMs' mastery of medical factual knowledge with a dynamic evaluation schema, which can automatically generate multiple test samples for each medical factual knowledge point. Test samples produced directly by LLMs always introduce factual errors and lack diversity in the manner of knowledge expression. To overcome the drawbacks, here we propose a novel evaluation method, Predicate-text Dual Transformation (PretextTrans), by introducing predicate transformations into the dynamic evaluation schema. Specifically, each medical knowledge point is firstly transformed into a predicate expression; then, the predicate expression derives a series of variants through predicate transformations; lastly, the produced predicate variants are transformed back into textual expressions, resulting in a series of test samples with both factual reliability and expression diversity. Using the proposed PretextTrans method, we systematically investigate 12 well-known LLMs' mastery of medical factual knowledge based on two medical datasets. The comparison results show that current LLMs still have significant deficiencies in fully mastering medical knowledge, which may illustrate why current LLMs still perform unsatisfactorily in real-world medical scenarios despite having achieved considerable performance on public benchmarks. Our proposed method serves as an effective solution for evaluation of LLMs in medical domain and offers valuable insights for developing medical-specific LLMs.
MultifacetEval: Multifaceted Evaluation to Probe LLMs in Mastering Medical Knowledge
Jun 05, 2024
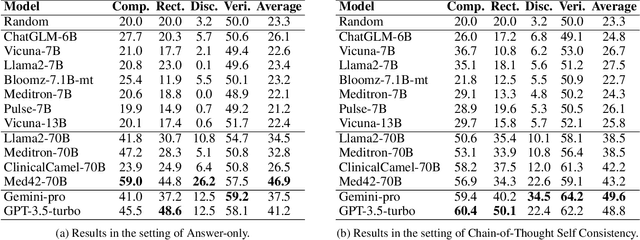


Large language models (LLMs) have excelled across domains, also delivering notable performance on the medical evaluation benchmarks, such as MedQA. However, there still exists a significant gap between the reported performance and the practical effectiveness in real-world medical scenarios. In this paper, we aim to explore the causes of this gap by employing a multifaceted examination schema to systematically probe the actual mastery of medical knowledge by current LLMs. Specifically, we develop a novel evaluation framework MultifacetEval to examine the degree and coverage of LLMs in encoding and mastering medical knowledge at multiple facets (comparison, rectification, discrimination, and verification) concurrently. Based on the MultifacetEval framework, we construct two multifaceted evaluation datasets: MultiDiseK (by producing questions from a clinical disease knowledge base) and MultiMedQA (by rephrasing each question from a medical benchmark MedQA into multifaceted questions). The experimental results on these multifaceted datasets demonstrate that the extent of current LLMs in mastering medical knowledge is far below their performance on existing medical benchmarks, suggesting that they lack depth, precision, and comprehensiveness in mastering medical knowledge. Consequently, current LLMs are not yet ready for application in real-world medical tasks. The codes and datasets are available at https://github.com/THUMLP/MultifacetEval.