 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-CMoE: Towards Continual Mixture of Experts for Large Vision-Language Models
Mar 27, 2025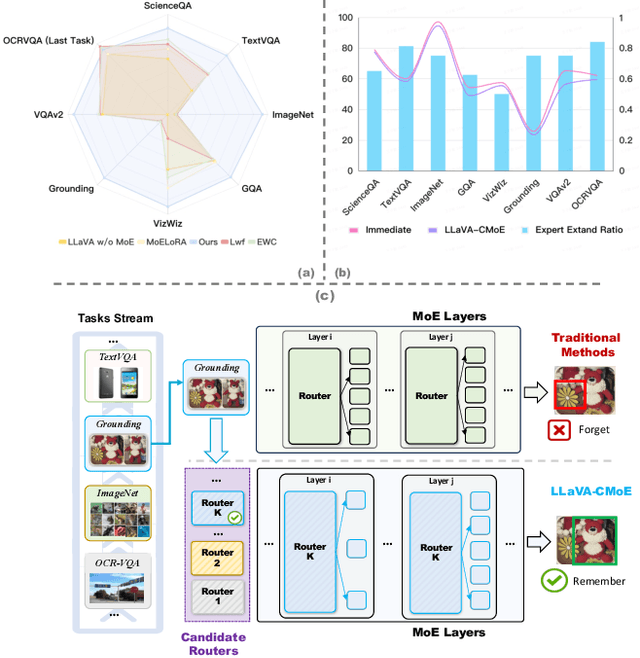
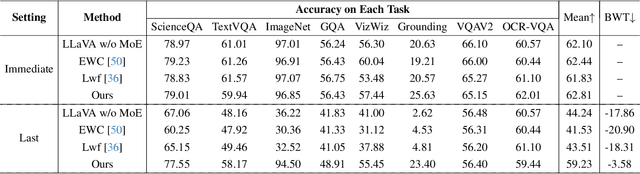
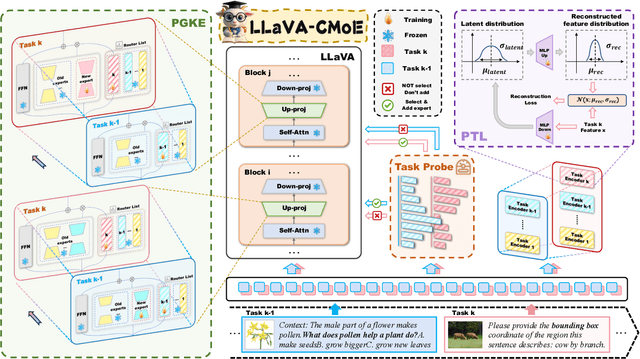
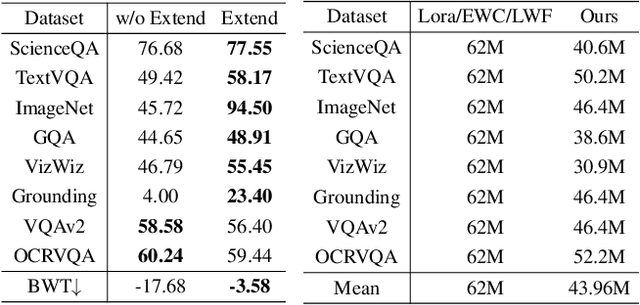
Although applying Mixture of Experts to large language models for learning new tasks is widely regarded as an effective strategy for continuous learning, there still remain two major challenges: (1) As the number of tasks grows, simple parameter expansion strategies can lead to excessively large models. (2) Modifying the parameters of the existing router results in the erosion of previously acquired knowledge. In this paper, we present an innovative framework named LLaVA-CMoE, which is a continuous Mixture of Experts (MoE) architecture without any replay data. Specifically, we have developed a method called Probe-Guided Knowledge Extension (PGKE), which employs probe experts to assess whether additional knowledge is required for a specific layer. This approach enables the model to adaptively expand its network parameters based on task distribution, thereby significantly improving the efficiency of parameter expansion. Additionally, we introduce a hierarchical routing algorithm called Probabilistic Task Locator (PTL), where high-level routing captures inter-task information and low-level routing focuses on intra-task details, ensuring that new task experts do not interfere with existing ones. Our experiments shows that our efficient architecture has substantially improved model performance on the Coin benchmark while maintaining a reasonable parameter count.
MIH-TCCT: Mitigating Inconsistent Hallucinations in LLMs via Event-Driven Text-Code Cyclic Training
Feb 13, 2025Recent methodologies utilizing synthetic datasets have aimed to address inconsistent hallucinations in large language models (LLMs); however,these approaches are primarily tailored to specific tasks, limiting their generalizability. Inspired by the strong performance of code-trained models in logic-intensive domains, we propose a novel framework that leverages event-based text to generate corresponding code and employs cyclic training to transfer the logical consistency of code to natural language effectively. Our method significantly reduces inconsistent hallucinations across three leading LLMs and two categories of natural language tasks while maintaining overall performance. This framework effectively alleviates hallucinations without necessitating adaptation to downstream tasks, demonstrating generality and providing new perspectives to tackle the challenge of inconsistent hallucinations.