 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMing-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
LLaVA-CMoE: Towards Continual Mixture of Experts for Large Vision-Language Models
Mar 27, 2025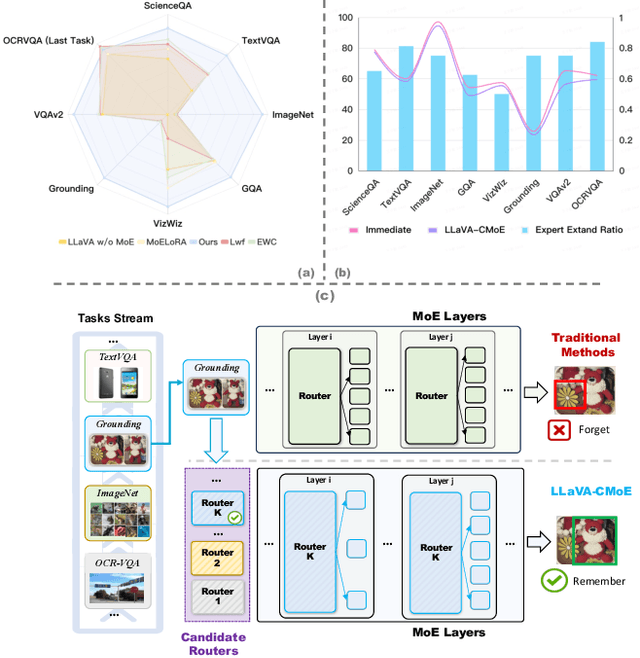
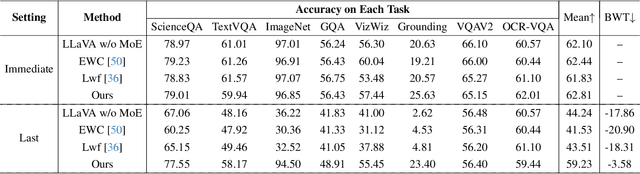
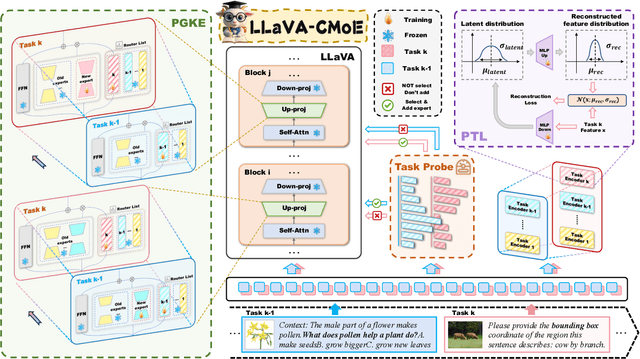
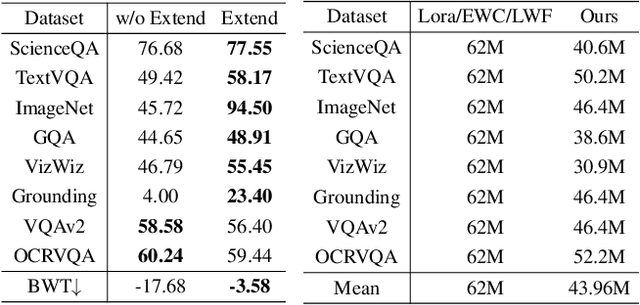
Although applying Mixture of Experts to large language models for learning new tasks is widely regarded as an effective strategy for continuous learning, there still remain two major challenges: (1) As the number of tasks grows, simple parameter expansion strategies can lead to excessively large models. (2) Modifying the parameters of the existing router results in the erosion of previously acquired knowledge. In this paper, we present an innovative framework named LLaVA-CMoE, which is a continuous Mixture of Experts (MoE) architecture without any replay data. Specifically, we have developed a method called Probe-Guided Knowledge Extension (PGKE), which employs probe experts to assess whether additional knowledge is required for a specific layer. This approach enables the model to adaptively expand its network parameters based on task distribution, thereby significantly improving the efficiency of parameter expansion. Additionally, we introduce a hierarchical routing algorithm called Probabilistic Task Locator (PTL), where high-level routing captures inter-task information and low-level routing focuses on intra-task details, ensuring that new task experts do not interfere with existing ones. Our experiments shows that our efficient architecture has substantially improved model performance on the Coin benchmark while maintaining a reasonable parameter count.
M2-omni: Advancing Omni-MLLM for Comprehensive Modality Support with Competitive Performance
Feb 26, 2025We present M2-omni, a cutting-edge, open-source omni-MLLM that achieves competitive performance to GPT-4o. M2-omni employs a unified multimodal sequence modeling framework, which empowers Large Language Models(LLMs) to acquire comprehensive cross-modal understanding and generation capabilities. Specifically, M2-omni can process arbitrary combinations of audio, video, image, and text modalities as input, generating multimodal sequences interleaving with audio, image, or text outputs, thereby enabling an advanced and interactive real-time experience. The training of such an omni-MLLM is challenged by significant disparities in data quantity and convergence rates across modalities. To address these challenges, we propose a step balance strategy during pre-training to handle the quantity disparities in modality-specific data. Additionally, a dynamically adaptive balance strategy is introduced during the instruction tuning stage to synchronize the modality-wise training progress, ensuring optimal convergence. Notably, we prioritize preserving strong performance on pure text tasks to maintain the robustness of M2-omni's language understanding capability throughout the training process. To our best knowledge, M2-omni is currently a very competitive open-source model to GPT-4o, characterized by its comprehensive modality and task support, as well as its exceptional performance. We expect M2-omni will advance the development of omni-MLLMs, thus facilitating future research in this domain.
Bootstrap Masked Visual Modeling via Hard Patches Mining
Dec 21, 2023Masked visual modeling has attracted much attention due to its promising potential in learning generalizable representations. Typical approaches urge models to predict specific contents of masked tokens, which can be intuitively considered as teaching a student (the model) to solve given problems (predicting masked contents). Under such settings, the performance is highly correlated with mask strategies (the difficulty of provided problems). We argue that it is equally important for the model to stand in the shoes of a teacher to produce challenging problems by itself. Intuitively, patches with high values of reconstruction loss can be regarded as hard samples, and masking those hard patches naturally becomes a demanding reconstruction task. To empower the model as a teacher, we propose Hard Patches Mining (HPM), predicting patch-wise losses and subsequently determining where to mask. Technically, we introduce an auxiliary loss predictor, which is trained with a relative objective to prevent overfitting to exact loss values. Also, to gradually guide the training procedure, we propose an easy-to-hard mask strategy. Empirically, HPM brings significant improvements under both image and video benchmarks. Interestingly, solely incorporating the extra loss prediction objective leads to better representations, verifying the efficacy of determining where is hard to reconstruct. The code is available at https://github.com/Haochen-Wang409/HPM.
Semantic-Aware Autoregressive Image Modeling for Visual Representation Learning
Dec 16, 2023The development of autoregressive modeling (AM) in computer vision lags behind natural language processing (NLP) in self-supervised pre-training. This is mainly caused by the challenge that images are not sequential signals and lack a natural order when applying autoregressive modeling. In this study, inspired by human beings' way of grasping an image, i.e., focusing on the main object first, we present a semantic-aware autoregressive image modeling (SemAIM) method to tackle this challenge. The key insight of SemAIM is to autoregressive model images from the semantic patches to the less semantic patches. To this end, we first calculate a semantic-aware permutation of patches according to their feature similarities and then perform the autoregression procedure based on the permutation. In addition, considering that the raw pixels of patches are low-level signals and are not ideal prediction targets for learning high-level semantic representation, we also explore utilizing the patch features as the prediction targets. Extensive experiments are conducted on a broad range of downstream tasks, including image classification, object detection, and instance/semantic segmentation, to evaluate the performance of SemAIM. The results demonstrate SemAIM achieves state-of-the-art performance compared with other self-supervised methods. Specifically, with ViT-B, SemAIM achieves 84.1% top-1 accuracy for fine-tuning on ImageNet, 51.3% AP and 45.4% AP for object detection and instance segmentation on COCO, which outperforms the vanilla MAE by 0.5%, 1.0%, and 0.5%, respectively.
DropPos: Pre-Training Vision Transformers by Reconstructing Dropped Positions
Sep 22, 2023As it is empirically observed that Vision Transformers (ViTs) are quite insensitive to the order of input tokens, the need for an appropriate self-supervised pretext task that enhances the location awareness of ViTs is becoming evident. To address this, we present DropPos, a novel pretext task designed to reconstruct Dropped Positions. The formulation of DropPos is simple: we first drop a large random subset of positional embeddings and then the model classifies the actual position for each non-overlapping patch among all possible positions solely based on their visual appearance. To avoid trivial solutions, we increase the difficulty of this task by keeping only a subset of patches visible. Additionally, considering there may be different patches with similar visual appearances, we propose position smoothing and attentive reconstruction strategies to relax this classification problem, since it is not necessary to reconstruct their exact positions in these cases. Empirical evaluations of DropPos show strong capabilities. DropPos outperforms supervised pre-training and achieves competitive results compared with state-of-the-art self-supervised alternatives on a wide range of downstream benchmarks. This suggests that explicitly encouraging spatial reasoning abilities, as DropPos does, indeed contributes to the improved location awareness of ViTs. The code is publicly available at https://github.com/Haochen-Wang409/DropPos.
Multi-Mode Online Knowledge Distillation for Self-Supervised Visual Representation Learning
Apr 13, 2023
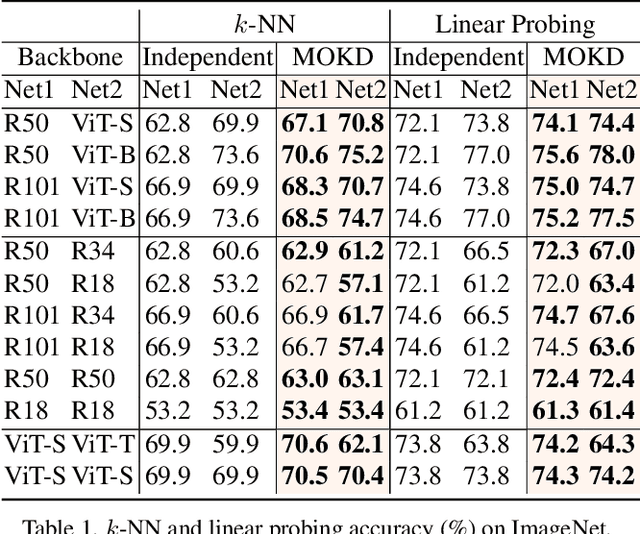

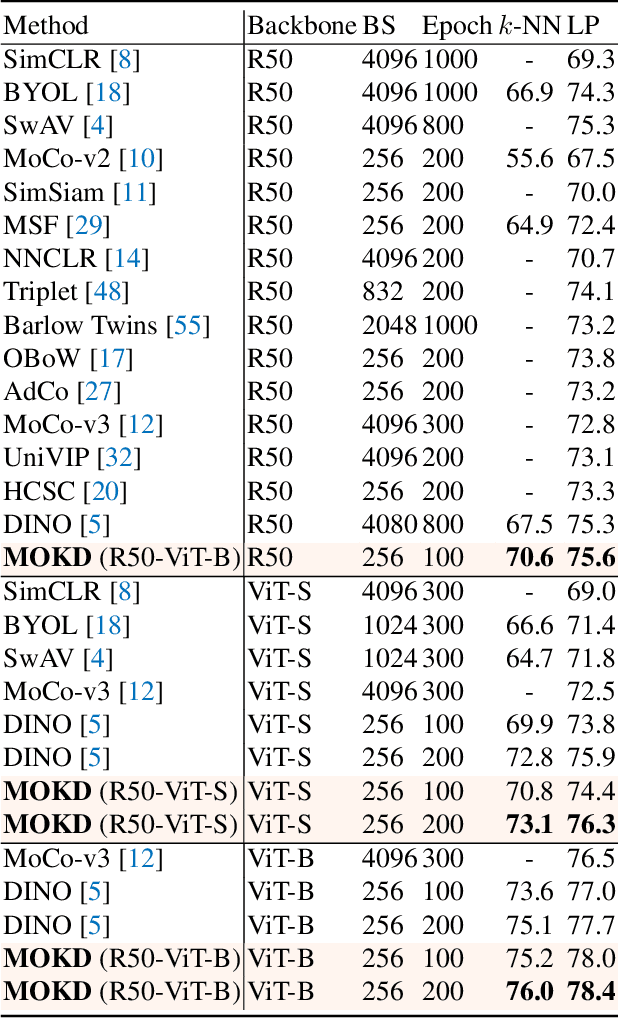
Self-supervised learning (SSL) has made remarkable progress in visual representation learning. Some studies combine SSL with knowledge distillation (SSL-KD) to boost the representation learning performance of small models. In this study, we propose a Multi-mode Online Knowledge Distillation method (MOKD) to boost self-supervised visual representation learning. Different from existing SSL-KD methods that transfer knowledge from a static pre-trained teacher to a student, in MOKD, two different models learn collaboratively in a self-supervised manner. Specifically, MOKD consists of two distillation modes: self-distillation and cross-distillation modes. Among them, self-distillation performs self-supervised learning for each model independently, while cross-distillation realizes knowledge interaction between different models. In cross-distillation, a cross-attention feature search strategy is proposed to enhance the semantic feature alignment between different models. As a result, the two models can absorb knowledge from each other to boost their representation learning performance. Extensive experimental results on different backbones and datasets demonstrate that two heterogeneous models can benefit from MOKD and outperform their independently trained baseline. In addition, MOKD also outperforms existing SSL-KD methods for both the student and teacher models.
Hard Patches Mining for Masked Image Modeling
Apr 12, 2023



Masked image modeling (MIM) has attracted much research attention due to its promising potential for learning scalable visual representations. In typical approaches, models usually focus on predicting specific contents of masked patches, and their performances are highly related to pre-defined mask strategies. Intuitively, this procedure can be considered as training a student (the model) on solving given problems (predict masked patches). However, we argue that the model should not only focus on solving given problems, but also stand in the shoes of a teacher to produce a more challenging problem by itself. To this end, we propose Hard Patches Mining (HPM), a brand-new framework for MIM pre-training. We observe that the reconstruction loss can naturally be the metric of the difficulty of the pre-training task. Therefore, we introduce an auxiliary loss predictor, predicting patch-wise losses first and deciding where to mask next. It adopts a relative relationship learning strategy to prevent overfitting to exact reconstruction loss values. Experiments under various settings demonstrate the effectiveness of HPM in constructing masked images. Furthermore, we empirically find that solely introducing the loss prediction objective leads to powerful representations, verifying the efficacy of the ability to be aware of where is hard to reconstruct.
Semantics-Consistent Feature Search for Self-Supervised Visual Representation Learning
Dec 13, 2022
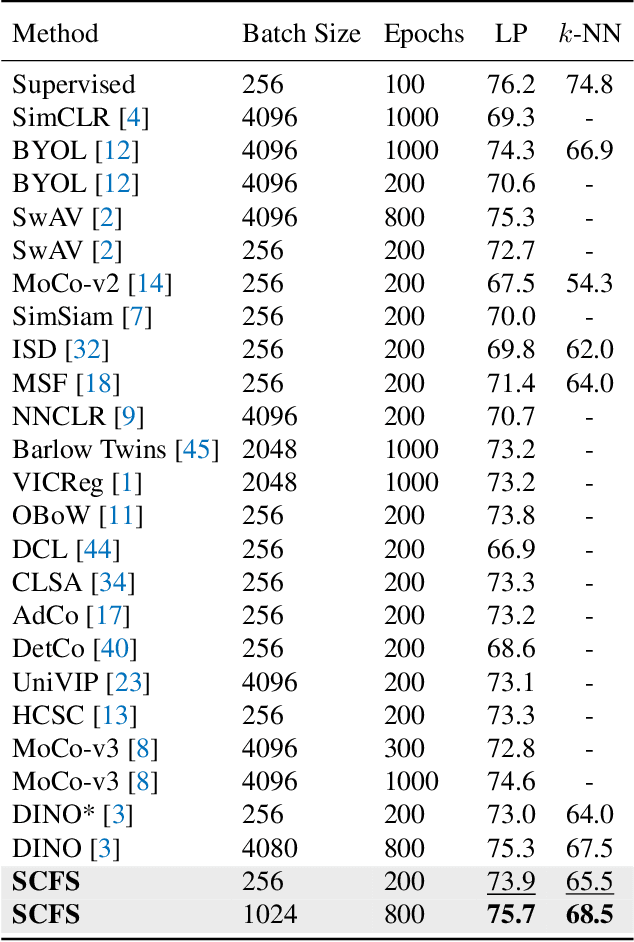


In contrastive self-supervised learning, the common way to learn discriminative representation is to pull different augmented "views" of the same image closer while pushing all other images further apart, which has been proven to be effective. However, it is unavoidable to construct undesirable views containing different semantic concepts during the augmentation procedure. It would damage the semantic consistency of representation to pull these augmentations closer in the feature space indiscriminately. In this study, we introduce feature-level augmentation and propose a novel semantics-consistent feature search (SCFS) method to mitigate this negative effect. The main idea of SCFS is to adaptively search semantics-consistent features to enhance the contrast between semantics-consistent regions in different augmentations. Thus, the trained model can learn to focus on meaningful object regions, improving the semantic representation ability. Extensive experiments conducted on different datasets and tasks demonstrate that SCFS effectively improves the performance of self-supervised learning and achieves state-of-the-art performance on different downstream tasks.