 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMing-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
M2-omni: Advancing Omni-MLLM for Comprehensive Modality Support with Competitive Performance
Feb 26, 2025We present M2-omni, a cutting-edge, open-source omni-MLLM that achieves competitive performance to GPT-4o. M2-omni employs a unified multimodal sequence modeling framework, which empowers Large Language Models(LLMs) to acquire comprehensive cross-modal understanding and generation capabilities. Specifically, M2-omni can process arbitrary combinations of audio, video, image, and text modalities as input, generating multimodal sequences interleaving with audio, image, or text outputs, thereby enabling an advanced and interactive real-time experience. The training of such an omni-MLLM is challenged by significant disparities in data quantity and convergence rates across modalities. To address these challenges, we propose a step balance strategy during pre-training to handle the quantity disparities in modality-specific data. Additionally, a dynamically adaptive balance strategy is introduced during the instruction tuning stage to synchronize the modality-wise training progress, ensuring optimal convergence. Notably, we prioritize preserving strong performance on pure text tasks to maintain the robustness of M2-omni's language understanding capability throughout the training process. To our best knowledge, M2-omni is currently a very competitive open-source model to GPT-4o, characterized by its comprehensive modality and task support, as well as its exceptional performance. We expect M2-omni will advance the development of omni-MLLMs, thus facilitating future research in this domain.
FixNorm: Dissecting Weight Decay for Training Deep Neural Networks
Mar 29, 2021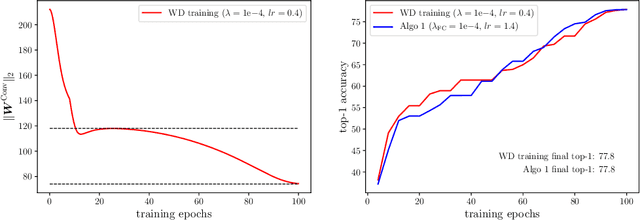

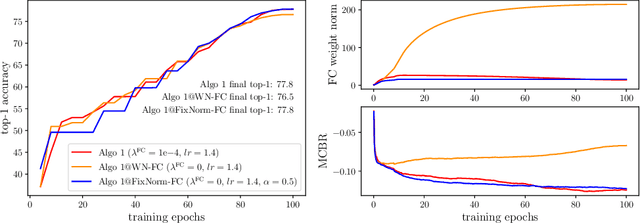
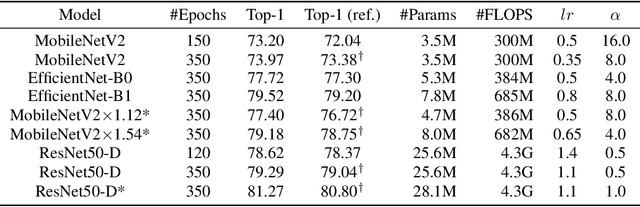
Weight decay is a widely used technique for training Deep Neural Networks(DNN). It greatly affects generalization performance but the underlying mechanisms are not fully understood. Recent works show that for layers followed by normalizations, weight decay mainly affects the effective learning rate. However, despite normalizations have been extensively adopted in modern DNNs, layers such as the final fully-connected layer do not satisfy this precondition. For these layers, the effects of weight decay are still unclear. In this paper, we comprehensively investigate the mechanisms of weight decay and find that except for influencing effective learning rate, weight decay has another distinct mechanism that is equally important: affecting generalization performance by controlling cross-boundary risk. These two mechanisms together give a more comprehensive explanation for the effects of weight decay. Based on this discovery, we propose a new training method called FixNorm, which discards weight decay and directly controls the two mechanisms. We also propose a simple yet effective method to tune hyperparameters of FixNorm, which can find near-optimal solutions in a few trials. On ImageNet classification task, training EfficientNet-B0 with FixNorm achieves 77.7%, which outperforms the original baseline by a clear margin. Surprisingly, when scaling MobileNetV2 to the same FLOPS and applying the same tricks with EfficientNet-B0, training with FixNorm achieves 77.4%, which is only 0.3% lower. A series of SOTA results show the importance of well-tuned training procedures, and further verify the effectiveness of our approach. We set up more well-tuned baselines using FixNorm, to facilitate fair comparisons in the community.