 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaimDiff-RL: Fine-Grained Caption Reinforcement Learning through Visual Claim Comparison
May 19, 2026Long-form image captioning exposes a reward granularity problem in RL: captions are judged as whole sequences, while the important errors occur at the level of individual visual claims. A good dense caption should be both faithful and informative, avoiding hallucination without omitting salient details. Yet pairwise preferences, reference-based metrics, and holistic scalar rewards compress these local errors into a single sequence-level signal, obscuring the tradeoff between factuality and coverage. We introduce ClaimDiff-RL, a framework that uses reference-conditioned atomic claim differences as the reward unit for caption RL. Given an image, an actor caption, and a reference caption, a multimodal judge enumerates visually grounded differences, verifies each difference against the image, assigns open-vocabulary error types and severity levels, and produces per-difference statistics for reward composition. This makes hallucinated claims and omitted salient facts separately measurable and tunable. Experiments show that holistic scalar rewards can reduce hallucination by increasing missing facts, while ClaimDiff-RL exposes this faithfulness and coverage tradeoff and enables more balanced operating points. On a 160-image human-labeled diagnostic benchmark, public captioning benchmarks, and VQA benchmarks, ClaimDiff-RL improves the hallucination--missing-fact balance, preserves general capability, and even surpasses Gemini-3-Pro-Preview on several fine-grained Capability dimensions such as object counting, spatial relations, and scene recognition. These results suggest that typed, verifiable claim differences are an effective reward unit for fine-grained and diagnosable caption RL.
Towards Scalable Pre-training of Visual Tokenizers for Generation
Dec 15, 2025The quality of the latent space in visual tokenizers (e.g., VAEs) is crucial for modern generative models. However, the standard reconstruction-based training paradigm produces a latent space that is biased towards low-level information, leading to a foundation flaw: better pixel-level accuracy does not lead to higher-quality generation. This implies that pouring extensive compute into visual tokenizer pre-training translates poorly to improved performance in generation. We identify this as the ``pre-training scaling problem`` and suggest a necessary shift: to be effective for generation, a latent space must concisely represent high-level semantics. We present VTP, a unified visual tokenizer pre-training framework, pioneering the joint optimization of image-text contrastive, self-supervised, and reconstruction losses. Our large-scale study reveals two principal findings: (1) understanding is a key driver of generation, and (2) much better scaling properties, where generative performance scales effectively with compute, parameters, and data allocated to the pretraining of the visual tokenizer. After large-scale pre-training, our tokenizer delivers a competitive profile (78.2 zero-shot accuracy and 0.36 rFID on ImageNet) and 4.1 times faster convergence on generation compared to advanced distillation methods. More importantly, it scales effectively: without modifying standard DiT training specs, solely investing more FLOPS in pretraining VTP achieves 65.8\% FID improvement in downstream generation, while conventional autoencoder stagnates very early at 1/10 FLOPS. Our pre-trained models are available at https://github.com/MiniMax-AI/VTP.
Learning Low-Rank Representations for Model Compression
Nov 21, 2022



Vector Quantization (VQ) is an appealing model compression method to obtain a tiny model with less accuracy loss. While methods to obtain better codebooks and codes under fixed clustering dimensionality have been extensively studied, optimizations of the vectors in favour of clustering performance are not carefully considered, especially via the reduction of vector dimensionality. This paper reports our recent progress on the combination of dimensionality compression and vector quantization, proposing a Low-Rank Representation Vector Quantization ($\text{LR}^2\text{VQ}$) method that outperforms previous VQ algorithms in various tasks and architectures. $\text{LR}^2\text{VQ}$ joins low-rank representation with subvector clustering to construct a new kind of building block that is directly optimized through end-to-end training over the task loss. Our proposed design pattern introduces three hyper-parameters, the number of clusters $k$, the size of subvectors $m$ and the clustering dimensionality $\tilde{d}$. In our method, the compression ratio could be directly controlled by $m$, and the final accuracy is solely determined by $\tilde{d}$. We recognize $\tilde{d}$ as a trade-off between low-rank approximation error and clustering error and carry out both theoretical analysis and experimental observations that empower the estimation of the proper $\tilde{d}$ before fine-tunning. With a proper $\tilde{d}$, we evaluate $\text{LR}^2\text{VQ}$ with ResNet-18/ResNet-50 on ImageNet classification datasets, achieving 2.8\%/1.0\% top-1 accuracy improvements over the current state-of-the-art VQ-based compression algorithms with 43$\times$/31$\times$ compression factor.
Learning specialized activation functions with the Piecewise Linear Unit
Apr 08, 2021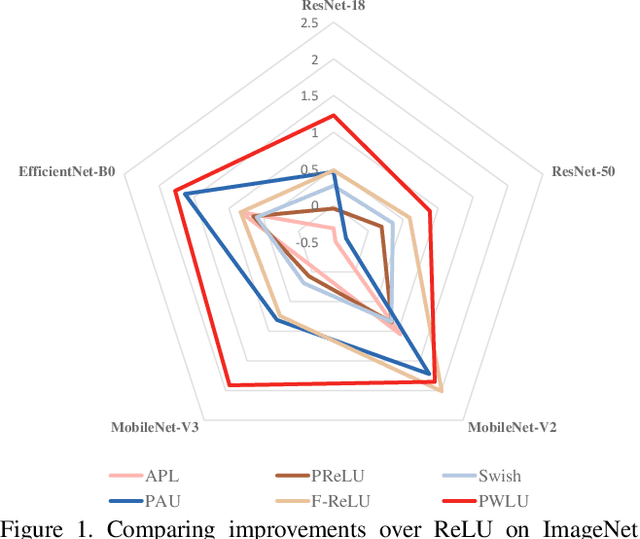
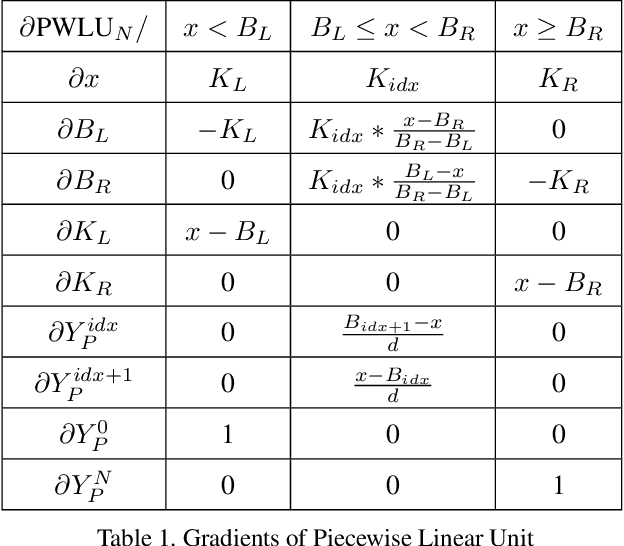
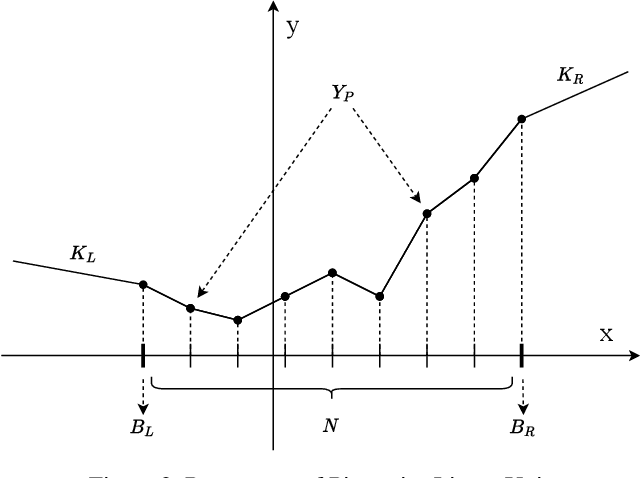
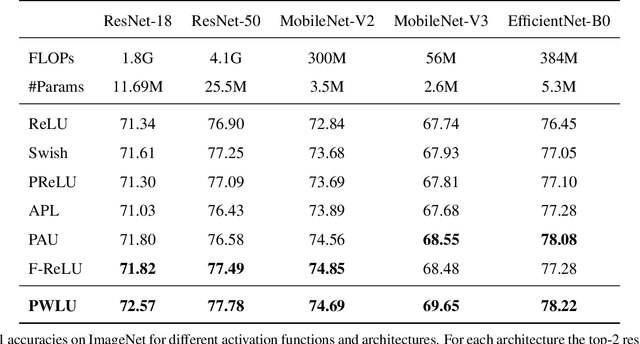
The choice of activation functions is crucial for modern deep neural networks. Popular hand-designed activation functions like Rectified Linear Unit(ReLU) and its variants show promising performance in various tasks and models. Swish, the automatically discovered activation function, has been proposed and outperforms ReLU on many challenging datasets. However, it has two main drawbacks. First, the tree-based search space is highly discrete and restricted, which is difficult for searching. Second, the sample-based searching method is inefficient, making it infeasible to find specialized activation functions for each dataset or neural architecture. To tackle these drawbacks, we propose a new activation function called Piecewise Linear Unit(PWLU), which incorporates a carefully designed formulation and learning method. It can learn specialized activation functions and achieves SOTA performance on large-scale datasets like ImageNet and COCO. For example, on ImageNet classification dataset, PWLU improves 0.9%/0.53%/1.0%/1.7%/1.0% top-1 accuracy over Swish for ResNet-18/ResNet-50/MobileNet-V2/MobileNet-V3/EfficientNet-B0. PWLU is also easy to implement and efficient at inference, which can be widely applied in real-world applications.
FixNorm: Dissecting Weight Decay for Training Deep Neural Networks
Mar 29, 2021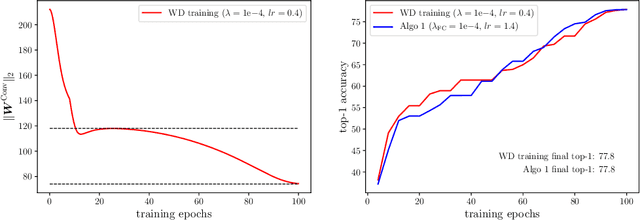

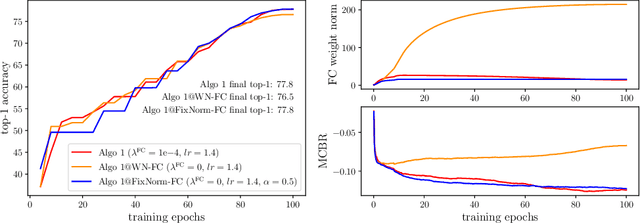
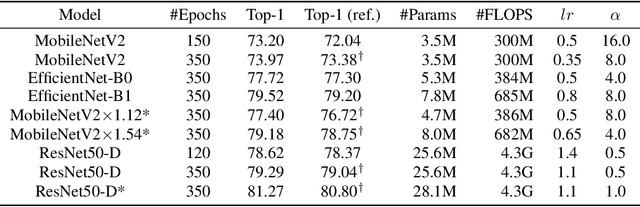
Weight decay is a widely used technique for training Deep Neural Networks(DNN). It greatly affects generalization performance but the underlying mechanisms are not fully understood. Recent works show that for layers followed by normalizations, weight decay mainly affects the effective learning rate. However, despite normalizations have been extensively adopted in modern DNNs, layers such as the final fully-connected layer do not satisfy this precondition. For these layers, the effects of weight decay are still unclear. In this paper, we comprehensively investigate the mechanisms of weight decay and find that except for influencing effective learning rate, weight decay has another distinct mechanism that is equally important: affecting generalization performance by controlling cross-boundary risk. These two mechanisms together give a more comprehensive explanation for the effects of weight decay. Based on this discovery, we propose a new training method called FixNorm, which discards weight decay and directly controls the two mechanisms. We also propose a simple yet effective method to tune hyperparameters of FixNorm, which can find near-optimal solutions in a few trials. On ImageNet classification task, training EfficientNet-B0 with FixNorm achieves 77.7%, which outperforms the original baseline by a clear margin. Surprisingly, when scaling MobileNetV2 to the same FLOPS and applying the same tricks with EfficientNet-B0, training with FixNorm achieves 77.4%, which is only 0.3% lower. A series of SOTA results show the importance of well-tuned training procedures, and further verify the effectiveness of our approach. We set up more well-tuned baselines using FixNorm, to facilitate fair comparisons in the community.
Towards Flops-constrained Face Recognition
Sep 02, 2019
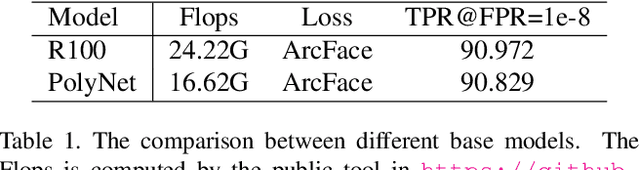
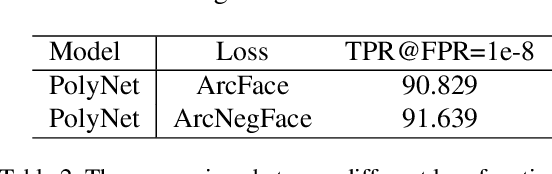
Large scale face recognition is challenging especially when the computational budget is limited. Given a \textit{flops} upper bound, the key is to find the optimal neural network architecture and optimization method. In this article, we briefly introduce the solutions of team 'trojans' for the ICCV19 - Lightweight Face Recognition Challenge~\cite{lfr}. The challenge requires each submission to be one single model with the computational budget no higher than 30 GFlops. We introduce a searched network architecture `Efficient PolyFace' based on the Flops constraint, a novel loss function `ArcNegFace', a novel frame aggregation method `QAN++', together with a bag of useful tricks in our implementation (augmentations, regular face, label smoothing, anchor finetuning, etc.). Our basic model, `Efficient PolyFace', takes 28.25 Gflops for the `deepglint-large' image-based track, and the `PolyFace+QAN++' solution takes 24.12 Gflops for the `iQiyi-large' video-based track. These two solutions achieve 94.198\% @ 1e-8 and 72.981\% @ 1e-4 in the two tracks respectively, which are the state-of-the-art results.
Crafting GBD-Net for Object Detection
Oct 08, 2016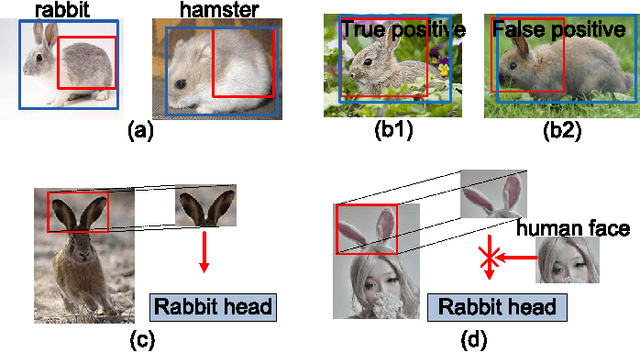
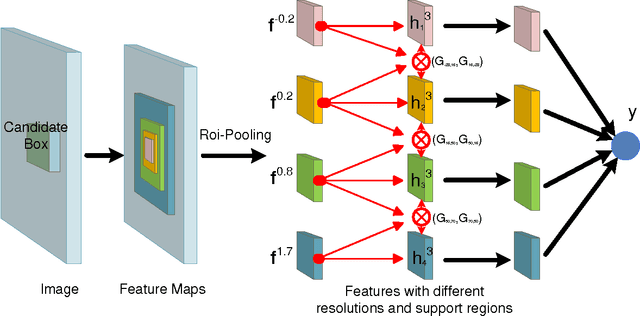
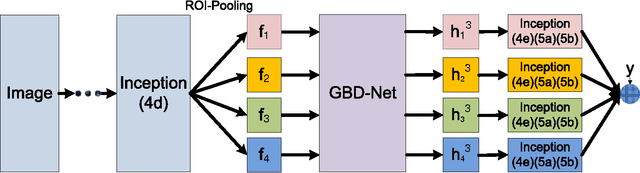
The visual cues from multiple support regions of different sizes and resolutions are complementary in classifying a candidate box in object detection. Effective integration of local and contextual visual cues from these regions has become a fundamental problem in object detection. In this paper, we propose a gated bi-directional CNN (GBD-Net) to pass messages among features from different support regions during both feature learning and feature extraction. Such message passing can be implemented through convolution between neighboring support regions in two directions and can be conducted in various layers. Therefore, local and contextual visual patterns can validate the existence of each other by learning their nonlinear relationships and their close interactions are modeled in a more complex way. It is also shown that message passing is not always helpful but dependent on individual samples. Gated functions are therefore needed to control message transmission, whose on-or-offs are controlled by extra visual evidence from the input sample. The effectiveness of GBD-Net is shown through experiments on three object detection datasets, ImageNet, Pascal VOC2007 and Microsoft COCO. This paper also shows the details of our approach in wining the ImageNet object detection challenge of 2016, with source code provided on \url{https://github.com/craftGBD/craftGBD}.