 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoGramBench: Benchmarking the Geometric Program Reasoning in Modern LLMs
May 23, 2025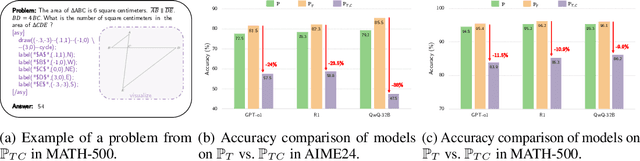
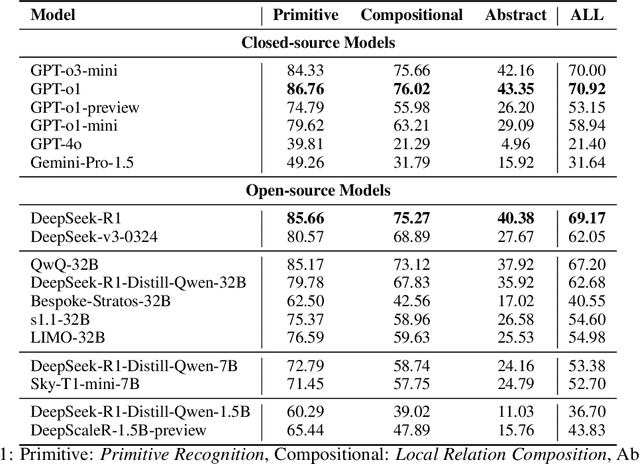
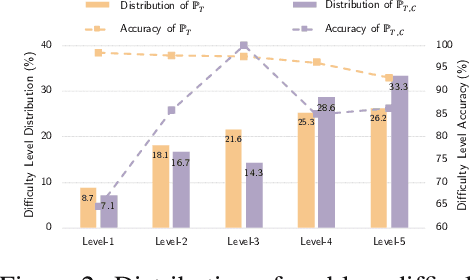
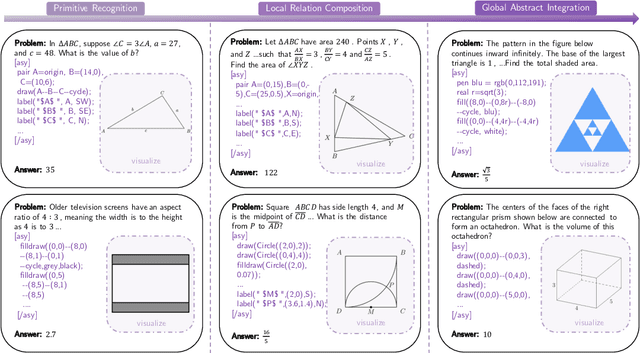
Geometric spatial reasoning forms the foundation of many applications in artificial intelligence, yet the ability of large language models (LLMs) to operate over geometric spatial information expressed in procedural code remains underexplored. In this paper, we address this gap by formalizing the Program-to-Geometry task, which challenges models to translate programmatic drawing code into accurate and abstract geometric reasoning. To evaluate this capability, we present GeoGramBench, a benchmark of 500 carefully refined problems organized by a tailored three-level taxonomy that considers geometric complexity rather than traditional mathematical reasoning complexity. Our comprehensive evaluation of 17 frontier LLMs reveals consistent and pronounced deficiencies: even the most advanced models achieve less than 50% accuracy at the highest abstraction level. These results highlight the unique challenges posed by program-driven spatial reasoning and establish GeoGramBench as a valuable resource for advancing research in symbolic-to-spatial geometric reasoning. Project page: https://github.com/LiAuto-DSR/GeoGramBench.
Cognitive Memory in Large Language Models
Apr 03, 2025This paper examines memory mechanisms in Large Language Models (LLMs), emphasizing their importance for context-rich responses, reduced hallucinations, and improved efficiency. It categorizes memory into sensory, short-term, and long-term, with sensory memory corresponding to input prompts, short-term memory processing immediate context, and long-term memory implemented via external databases or structures. The text-based memory section covers acquisition (selection and summarization), management (updating, accessing, storing, and resolving conflicts), and utilization (full-text search, SQL queries, semantic search). The KV cache-based memory section discusses selection methods (regularity-based summarization, score-based approaches, special token embeddings) and compression techniques (low-rank compression, KV merging, multimodal compression), along with management strategies like offloading and shared attention mechanisms. Parameter-based memory methods (LoRA, TTT, MoE) transform memories into model parameters to enhance efficiency, while hidden-state-based memory approaches (chunk mechanisms, recurrent transformers, Mamba model) improve long-text processing by combining RNN hidden states with current methods. Overall, the paper offers a comprehensive analysis of LLM memory mechanisms, highlighting their significance and future research directions.
Learning Low-Rank Representations for Model Compression
Nov 21, 2022



Vector Quantization (VQ) is an appealing model compression method to obtain a tiny model with less accuracy loss. While methods to obtain better codebooks and codes under fixed clustering dimensionality have been extensively studied, optimizations of the vectors in favour of clustering performance are not carefully considered, especially via the reduction of vector dimensionality. This paper reports our recent progress on the combination of dimensionality compression and vector quantization, proposing a Low-Rank Representation Vector Quantization ($\text{LR}^2\text{VQ}$) method that outperforms previous VQ algorithms in various tasks and architectures. $\text{LR}^2\text{VQ}$ joins low-rank representation with subvector clustering to construct a new kind of building block that is directly optimized through end-to-end training over the task loss. Our proposed design pattern introduces three hyper-parameters, the number of clusters $k$, the size of subvectors $m$ and the clustering dimensionality $\tilde{d}$. In our method, the compression ratio could be directly controlled by $m$, and the final accuracy is solely determined by $\tilde{d}$. We recognize $\tilde{d}$ as a trade-off between low-rank approximation error and clustering error and carry out both theoretical analysis and experimental observations that empower the estimation of the proper $\tilde{d}$ before fine-tunning. With a proper $\tilde{d}$, we evaluate $\text{LR}^2\text{VQ}$ with ResNet-18/ResNet-50 on ImageNet classification datasets, achieving 2.8\%/1.0\% top-1 accuracy improvements over the current state-of-the-art VQ-based compression algorithms with 43$\times$/31$\times$ compression factor.
Learning specialized activation functions with the Piecewise Linear Unit
Apr 08, 2021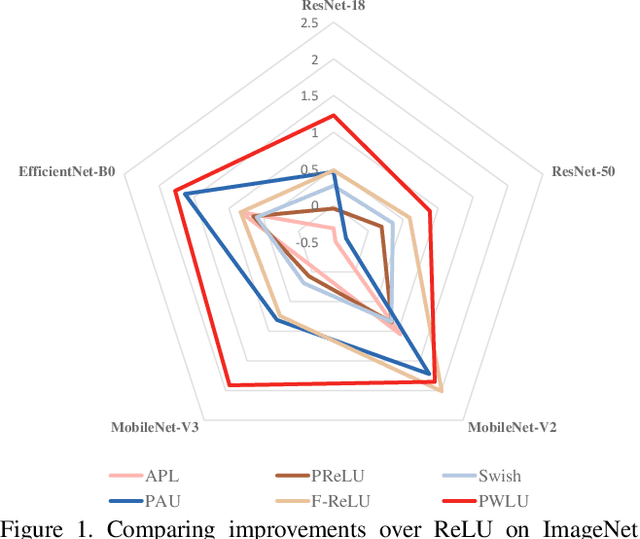
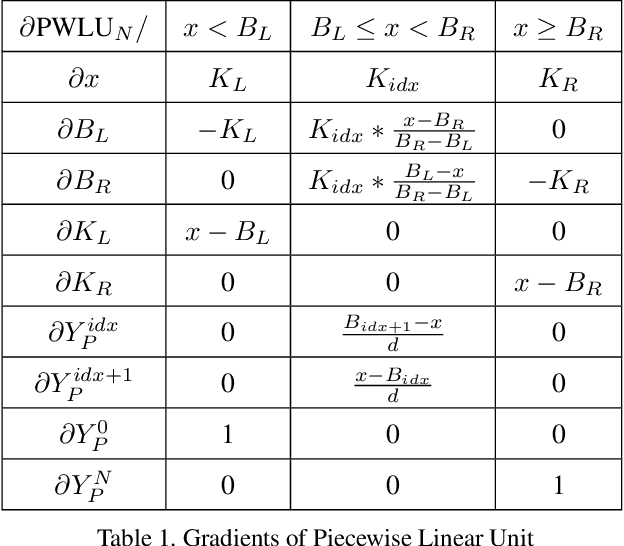
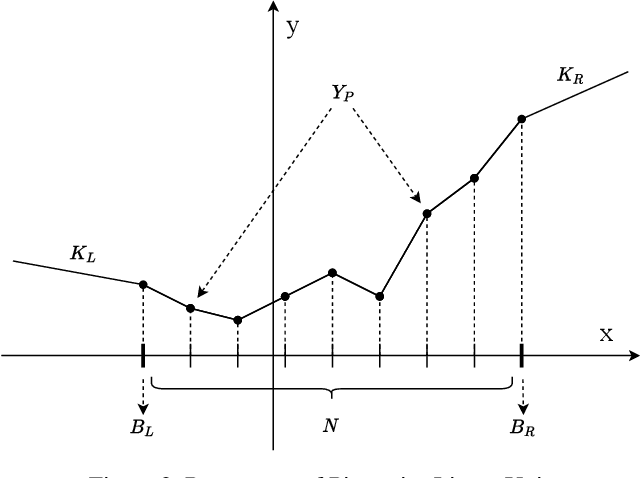
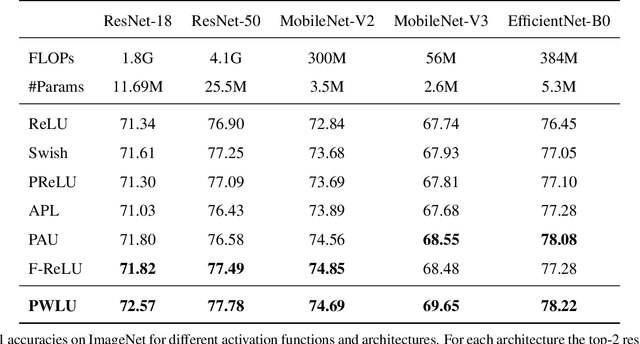
The choice of activation functions is crucial for modern deep neural networks. Popular hand-designed activation functions like Rectified Linear Unit(ReLU) and its variants show promising performance in various tasks and models. Swish, the automatically discovered activation function, has been proposed and outperforms ReLU on many challenging datasets. However, it has two main drawbacks. First, the tree-based search space is highly discrete and restricted, which is difficult for searching. Second, the sample-based searching method is inefficient, making it infeasible to find specialized activation functions for each dataset or neural architecture. To tackle these drawbacks, we propose a new activation function called Piecewise Linear Unit(PWLU), which incorporates a carefully designed formulation and learning method. It can learn specialized activation functions and achieves SOTA performance on large-scale datasets like ImageNet and COCO. For example, on ImageNet classification dataset, PWLU improves 0.9%/0.53%/1.0%/1.7%/1.0% top-1 accuracy over Swish for ResNet-18/ResNet-50/MobileNet-V2/MobileNet-V3/EfficientNet-B0. PWLU is also easy to implement and efficient at inference, which can be widely applied in real-world applications.