 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysAlign: Physics-Coherent Image-to-Video Generation through Feature and 3D Representation Alignment
Mar 14, 2026Video Diffusion Models (VDMs) offer a promising approach for simulating dynamic scenes and environments, with broad applications in robotics and media generation. However, existing models often generate temporally incoherent content that violates basic physical intuition, significantly limiting their practical applicability. We propose PhysAlign, an efficient framework for physics-coherent image-to-video (I2V) generation that explicitly addresses this limitation. To overcome the critical scarcity of physics-annotated videos, we first construct a fully controllable synthetic data generation pipeline based on rigid-body simulation, yielding a highly-curated dataset with accurate, fine-grained physics and 3D annotations. Leveraging this data, PhysAlign constructs a unified physical latent space by coupling explicit 3D geometry constraints with a Gram-based spatio-temporal relational alignment that extracts kinematic priors from video foundation models. Extensive experiments demonstrate that PhysAlign significantly outperforms existing VDMs on tasks requiring complex physical reasoning and temporal stability, without compromising zero-shot visual quality. PhysAlign shows the potential to bridge the gap between raw visual synthesis and rigid-body kinematics, establishing a practical paradigm for genuinely physics-grounded video generation. The project page is available at https://physalign.github.io/PhysAlign.
Simulating Human-Like Learning Dynamics with LLM-Empowered Agents
Aug 07, 2025Capturing human learning behavior based on deep learning methods has become a major research focus in both psychology and intelligent systems. Recent approaches rely on controlled experiments or rule-based models to explore cognitive processes. However, they struggle to capture learning dynamics, track progress over time, or provide explainability. To address these challenges, we introduce LearnerAgent, a novel multi-agent framework based on Large Language Models (LLMs) to simulate a realistic teaching environment. To explore human-like learning dynamics, we construct learners with psychologically grounded profiles-such as Deep, Surface, and Lazy-as well as a persona-free General Learner to inspect the base LLM's default behavior. Through weekly knowledge acquisition, monthly strategic choices, periodic tests, and peer interaction, we can track the dynamic learning progress of individual learners over a full-year journey. Our findings are fourfold: 1) Longitudinal analysis reveals that only Deep Learner achieves sustained cognitive growth. Our specially designed "trap questions" effectively diagnose Surface Learner's shallow knowledge. 2) The behavioral and cognitive patterns of distinct learners align closely with their psychological profiles. 3) Learners' self-concept scores evolve realistically, with the General Learner developing surprisingly high self-efficacy despite its cognitive limitations. 4) Critically, the default profile of base LLM is a "diligent but brittle Surface Learner"-an agent that mimics the behaviors of a good student but lacks true, generalizable understanding. Extensive simulation experiments demonstrate that LearnerAgent aligns well with real scenarios, yielding more insightful findings about LLMs' behavior.
iHDR: Iterative HDR Imaging with Arbitrary Number of Exposures
May 29, 2025High dynamic range (HDR) imaging aims to obtain a high-quality HDR image by fusing information from multiple low dynamic range (LDR) images. Numerous learning-based HDR imaging methods have been proposed to achieve this for static and dynamic scenes. However, their architectures are mostly tailored for a fixed number (e.g., three) of inputs and, therefore, cannot apply directly to situations beyond the pre-defined limited scope. To address this issue, we propose a novel framework, iHDR, for iterative fusion, which comprises a ghost-free Dual-input HDR fusion network (DiHDR) and a physics-based domain mapping network (ToneNet). DiHDR leverages a pair of inputs to estimate an intermediate HDR image, while ToneNet maps it back to the nonlinear domain and serves as the reference input for the next pairwise fusion. This process is iteratively executed until all input frames are utilized. Qualitative and quantitative experiments demonstrate the effectiveness of the proposed method as compared to existing state-of-the-art HDR deghosting approaches given flexible numbers of input frames.
GeoGramBench: Benchmarking the Geometric Program Reasoning in Modern LLMs
May 23, 2025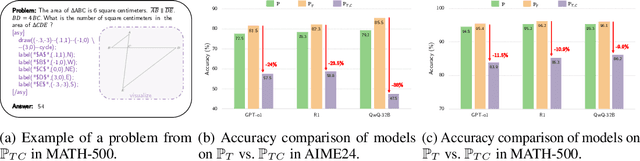
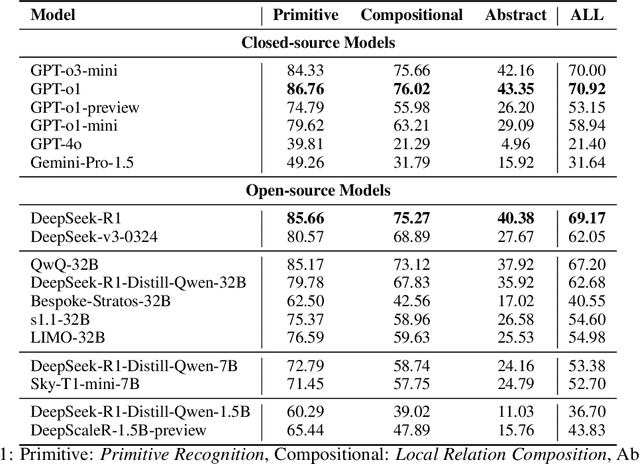
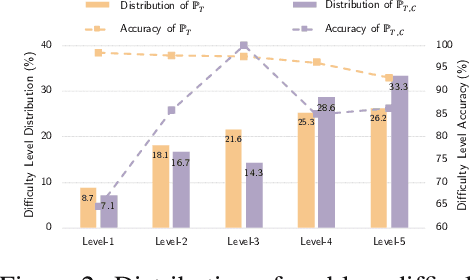
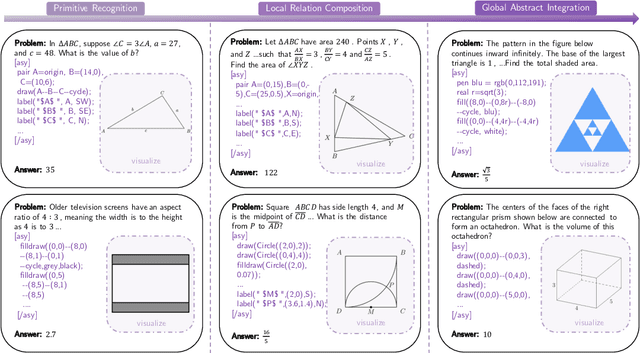
Geometric spatial reasoning forms the foundation of many applications in artificial intelligence, yet the ability of large language models (LLMs) to operate over geometric spatial information expressed in procedural code remains underexplored. In this paper, we address this gap by formalizing the Program-to-Geometry task, which challenges models to translate programmatic drawing code into accurate and abstract geometric reasoning. To evaluate this capability, we present GeoGramBench, a benchmark of 500 carefully refined problems organized by a tailored three-level taxonomy that considers geometric complexity rather than traditional mathematical reasoning complexity. Our comprehensive evaluation of 17 frontier LLMs reveals consistent and pronounced deficiencies: even the most advanced models achieve less than 50% accuracy at the highest abstraction level. These results highlight the unique challenges posed by program-driven spatial reasoning and establish GeoGramBench as a valuable resource for advancing research in symbolic-to-spatial geometric reasoning. Project page: https://github.com/LiAuto-DSR/GeoGramBench.
Learning Phase Distortion with Selective State Space Models for Video Turbulence Mitigation
Apr 03, 2025Atmospheric turbulence is a major source of image degradation in long-range imaging systems. Although numerous deep learning-based turbulence mitigation (TM) methods have been proposed, many are slow, memory-hungry, and do not generalize well. In the spatial domain, methods based on convolutional operators have a limited receptive field, so they cannot handle a large spatial dependency required by turbulence. In the temporal domain, methods relying on self-attention can, in theory, leverage the lucky effects of turbulence, but their quadratic complexity makes it difficult to scale to many frames. Traditional recurrent aggregation methods face parallelization challenges. In this paper, we present a new TM method based on two concepts: (1) A turbulence mitigation network based on the Selective State Space Model (MambaTM). MambaTM provides a global receptive field in each layer across spatial and temporal dimensions while maintaining linear computational complexity. (2) Learned Latent Phase Distortion (LPD). LPD guides the state space model. Unlike classical Zernike-based representations of phase distortion, the new LPD map uniquely captures the actual effects of turbulence, significantly improving the model's capability to estimate degradation by reducing the ill-posedness. Our proposed method exceeds current state-of-the-art networks on various synthetic and real-world TM benchmarks with significantly faster inference speed. The code is available at http://github.com/xg416/MambaTM.
Cognitive Memory in Large Language Models
Apr 03, 2025This paper examines memory mechanisms in Large Language Models (LLMs), emphasizing their importance for context-rich responses, reduced hallucinations, and improved efficiency. It categorizes memory into sensory, short-term, and long-term, with sensory memory corresponding to input prompts, short-term memory processing immediate context, and long-term memory implemented via external databases or structures. The text-based memory section covers acquisition (selection and summarization), management (updating, accessing, storing, and resolving conflicts), and utilization (full-text search, SQL queries, semantic search). The KV cache-based memory section discusses selection methods (regularity-based summarization, score-based approaches, special token embeddings) and compression techniques (low-rank compression, KV merging, multimodal compression), along with management strategies like offloading and shared attention mechanisms. Parameter-based memory methods (LoRA, TTT, MoE) transform memories into model parameters to enhance efficiency, while hidden-state-based memory approaches (chunk mechanisms, recurrent transformers, Mamba model) improve long-text processing by combining RNN hidden states with current methods. Overall, the paper offers a comprehensive analysis of LLM memory mechanisms, highlighting their significance and future research directions.
S3R-GS: Streamlining the Pipeline for Large-Scale Street Scene Reconstruction
Mar 11, 2025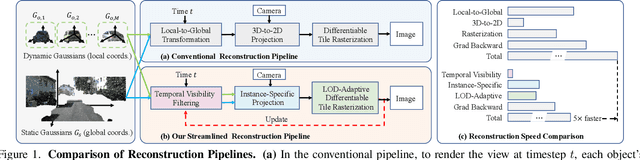



Recently, 3D Gaussian Splatting (3DGS) has reshaped the field of photorealistic 3D reconstruction, achieving impressive rendering quality and speed. However, when applied to large-scale street scenes, existing methods suffer from rapidly escalating per-viewpoint reconstruction costs as scene size increases, leading to significant computational overhead. After revisiting the conventional pipeline, we identify three key factors accounting for this issue: unnecessary local-to-global transformations, excessive 3D-to-2D projections, and inefficient rendering of distant content. To address these challenges, we propose S3R-GS, a 3DGS framework that Streamlines the pipeline for large-scale Street Scene Reconstruction, effectively mitigating these limitations. Moreover, most existing street 3DGS methods rely on ground-truth 3D bounding boxes to separate dynamic and static components, but 3D bounding boxes are difficult to obtain, limiting real-world applicability. To address this, we propose an alternative solution with 2D boxes, which are easier to annotate or can be predicted by off-the-shelf vision foundation models. Such designs together make S3R-GS readily adapt to large, in-the-wild scenarios. Extensive experiments demonstrate that S3R-GS enhances rendering quality and significantly accelerates reconstruction. Remarkably, when applied to videos from the challenging Argoverse2 dataset, it achieves state-of-the-art PSNR and SSIM, reducing reconstruction time to below 50%--and even 20%--of competing methods.
CAD-Editor: A Locate-then-Infill Framework with Automated Training Data Synthesis for Text-Based CAD Editing
Feb 06, 2025



Computer Aided Design (CAD) is indispensable across various industries. \emph{Text-based CAD editing}, which automates the modification of CAD models based on textual instructions, holds great potential but remains underexplored. Existing methods primarily focus on design variation generation or text-based CAD generation, either lacking support for text-based control or neglecting existing CAD models as constraints. We introduce \emph{CAD-Editor}, the first framework for text-based CAD editing. To address the challenge of demanding triplet data with accurate correspondence for training, we propose an automated data synthesis pipeline. This pipeline utilizes design variation models to generate pairs of original and edited CAD models and employs Large Vision-Language Models (LVLMs) to summarize their differences into editing instructions. To tackle the composite nature of text-based CAD editing, we propose a locate-then-infill framework that decomposes the task into two focused sub-tasks: locating regions requiring modification and infilling these regions with appropriate edits. Large Language Models (LLMs) serve as the backbone for both sub-tasks, leveraging their capabilities in natural language understanding and CAD knowledge. Experiments show that CAD-Editor achieves superior performance both quantitatively and qualitatively.
Text-to-CAD Generation Through Infusing Visual Feedback in Large Language Models
Jan 31, 2025



Creating Computer-Aided Design (CAD) models requires significant expertise and effort. Text-to-CAD, which converts textual descriptions into CAD parametric sequences, is crucial in streamlining this process. Recent studies have utilized ground-truth parametric sequences, known as sequential signals, as supervision to achieve this goal. However, CAD models are inherently multimodal, comprising parametric sequences and corresponding rendered visual objects. Besides,the rendering process from parametric sequences to visual objects is many-to-one. Therefore, both sequential and visual signals are critical for effective training. In this work, we introduce CADFusion, a framework that uses Large Language Models (LLMs) as the backbone and alternates between two training stages: the sequential learning (SL) stage and the visual feedback (VF) stage. In the SL stage, we train LLMs using ground-truth parametric sequences, enabling the generation of logically coherent parametric sequences. In the VF stage, we reward parametric sequences that render into visually preferred objects and penalize those that do not, allowing LLMs to learn how rendered visual objects are perceived and evaluated. These two stages alternate throughout the training, ensuring balanced learning and preserving benefits of both signals. Experiments demonstrate that CADFusion significantly improves performance, both qualitatively and quantitatively.
Personalized Generative Low-light Image Denoising and Enhancement
Dec 18, 2024While smartphone cameras today can produce astonishingly good photos, their performance in low light is still not completely satisfactory because of the fundamental limits in photon shot noise and sensor read noise. Generative image restoration methods have demonstrated promising results compared to traditional methods, but they suffer from hallucinatory content generation when the signal-to-noise ratio (SNR) is low. Recognizing the availability of personalized photo galleries on users' smartphones, we propose Personalized Generative Denoising (PGD) by building a diffusion model customized for different users. Our core innovation is an identity-consistent physical buffer that extracts the physical attributes of the person from the gallery. This ID-consistent physical buffer provides a strong prior that can be integrated with the diffusion model to restore the degraded images, without the need of fine-tuning. Over a wide range of low-light testing scenarios, we show that PGD achieves superior image denoising and enhancement performance compared to existing diffusion-based denoising approaches.