 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltrafast High-Flux Single-Photon LiDAR Simulator via Neural Mapping
May 29, 2025Efficient simulation of photon registrations in single-photon LiDAR (SPL) is essential for applications such as depth estimation under high-flux conditions, where hardware dead time significantly distorts photon measurements. However, the conventional wisdom is computationally intensive due to their inherently sequential, photon-by-photon processing. In this paper, we propose a learning-based framework that accelerates the simulation process by modeling the photon count and directly predicting the photon registration probability density function (PDF) using an autoencoder (AE). Our method achieves high accuracy in estimating both the total number of registered photons and their temporal distribution, while substantially reducing simulation time. Extensive experiments validate the effectiveness and efficiency of our approach, highlighting its potential to enable fast and accurate SPL simulations for data-intensive imaging tasks in the high-flux regime.
iHDR: Iterative HDR Imaging with Arbitrary Number of Exposures
May 29, 2025High dynamic range (HDR) imaging aims to obtain a high-quality HDR image by fusing information from multiple low dynamic range (LDR) images. Numerous learning-based HDR imaging methods have been proposed to achieve this for static and dynamic scenes. However, their architectures are mostly tailored for a fixed number (e.g., three) of inputs and, therefore, cannot apply directly to situations beyond the pre-defined limited scope. To address this issue, we propose a novel framework, iHDR, for iterative fusion, which comprises a ghost-free Dual-input HDR fusion network (DiHDR) and a physics-based domain mapping network (ToneNet). DiHDR leverages a pair of inputs to estimate an intermediate HDR image, while ToneNet maps it back to the nonlinear domain and serves as the reference input for the next pairwise fusion. This process is iteratively executed until all input frames are utilized. Qualitative and quantitative experiments demonstrate the effectiveness of the proposed method as compared to existing state-of-the-art HDR deghosting approaches given flexible numbers of input frames.
Personalized Generative Low-light Image Denoising and Enhancement
Dec 18, 2024While smartphone cameras today can produce astonishingly good photos, their performance in low light is still not completely satisfactory because of the fundamental limits in photon shot noise and sensor read noise. Generative image restoration methods have demonstrated promising results compared to traditional methods, but they suffer from hallucinatory content generation when the signal-to-noise ratio (SNR) is low. Recognizing the availability of personalized photo galleries on users' smartphones, we propose Personalized Generative Denoising (PGD) by building a diffusion model customized for different users. Our core innovation is an identity-consistent physical buffer that extracts the physical attributes of the person from the gallery. This ID-consistent physical buffer provides a strong prior that can be integrated with the diffusion model to restore the degraded images, without the need of fine-tuning. Over a wide range of low-light testing scenarios, we show that PGD achieves superior image denoising and enhancement performance compared to existing diffusion-based denoising approaches.
Generative Photography: Scene-Consistent Camera Control for Realistic Text-to-Image Synthesis
Dec 03, 2024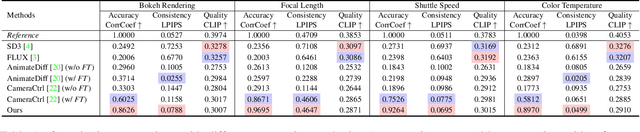



Image generation today can produce somewhat realistic images from text prompts. However, if one asks the generator to synthesize a particular camera setting such as creating different fields of view using a 24mm lens versus a 70mm lens, the generator will not be able to interpret and generate scene-consistent images. This limitation not only hinders the adoption of generative tools in photography applications but also exemplifies a broader issue of bridging the gap between the data-driven models and the physical world. In this paper, we introduce the concept of Generative Photography, a framework designed to control camera intrinsic settings during content generation. The core innovation of this work are the concepts of Dimensionality Lifting and Contrastive Camera Learning, which achieve continuous and consistent transitions for different camera settings. Experimental results show that our method produces significantly more scene-consistent photorealistic images than state-of-the-art models such as Stable Diffusion 3 and FLUX.
Space-Time Attention with Shifted Non-Local Search
Sep 28, 2023Efficiently computing attention maps for videos is challenging due to the motion of objects between frames. While a standard non-local search is high-quality for a window surrounding each query point, the window's small size cannot accommodate motion. Methods for long-range motion use an auxiliary network to predict the most similar key coordinates as offsets from each query location. However, accurately predicting this flow field of offsets remains challenging, even for large-scale networks. Small spatial inaccuracies significantly impact the attention module's quality. This paper proposes a search strategy that combines the quality of a non-local search with the range of predicted offsets. The method, named Shifted Non-Local Search, executes a small grid search surrounding the predicted offsets to correct small spatial errors. Our method's in-place computation consumes 10 times less memory and is over 3 times faster than previous work. Experimentally, correcting the small spatial errors improves the video frame alignment quality by over 3 dB PSNR. Our search upgrades existing space-time attention modules, which improves video denoising results by 0.30 dB PSNR for a 7.5% increase in overall runtime. We integrate our space-time attention module into a UNet-like architecture to achieve state-of-the-art results on video denoising.
FarSight: A Physics-Driven Whole-Body Biometric System at Large Distance and Altitude
Jun 29, 2023



Whole-body biometric recognition is an important area of research due to its vast applications in law enforcement, border security, and surveillance. This paper presents the end-to-end design, development and evaluation of FarSight, an innovative software system designed for whole-body (fusion of face, gait and body shape) biometric recognition. FarSight accepts videos from elevated platforms and drones as input and outputs a candidate list of identities from a gallery. The system is designed to address several challenges, including (i) low-quality imagery, (ii) large yaw and pitch angles, (iii) robust feature extraction to accommodate large intra-person variabilities and large inter-person similarities, and (iv) the large domain gap between training and test sets. FarSight combines the physics of imaging and deep learning models to enhance image restoration and biometric feature encoding. We test FarSight's effectiveness using the newly acquired IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) dataset. Notably, FarSight demonstrated a substantial performance increase on the BRIAR dataset, with gains of +11.82% Rank-20 identification and +11.3% TAR@1% FAR.
Image Reconstruction of Static and Dynamic Scenes through Anisoplanatic Turbulence
Aug 31, 2020

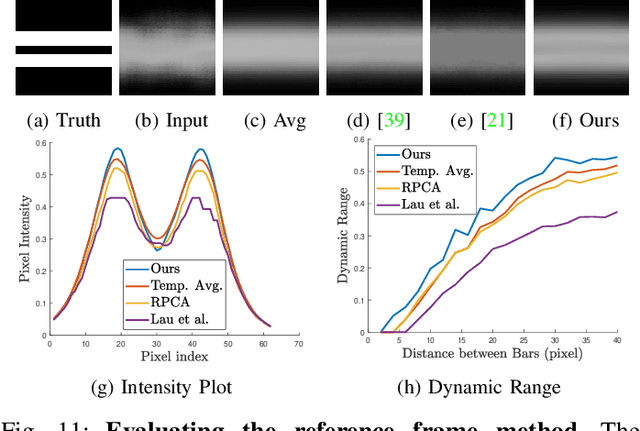

Ground based long-range passive imaging systems often suffer from degraded image quality due to a turbulent atmosphere. While methods exist for removing such turbulent distortions, many are limited to static sequences which cannot be extended to dynamic scenes. In addition, the physics of the turbulence is often not integrated into the image reconstruction algorithms, making the physics foundations of the methods weak. In this paper, we present a unified method for atmospheric turbulence mitigation in both static and dynamic sequences. We are able to achieve better results compared to existing methods by utilizing (i) a novel space-time non-local averaging method to construct a reliable reference frame, (ii) a geometric consistency and a sharpness metric to generate the lucky frame, (iii) a physics-constrained prior model of the point spread function for blind deconvolution. Experimental results based on synthetic and real long-range turbulence sequences validate the performance of the proposed method.
Plug and play methods for magnetic resonance imaging
Mar 20, 2019
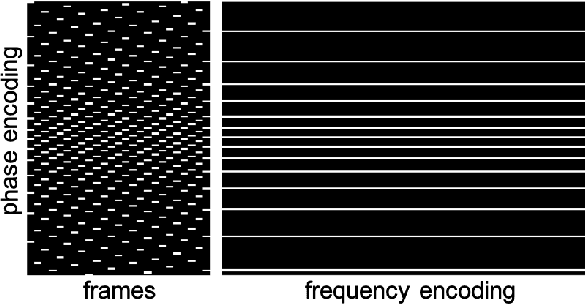
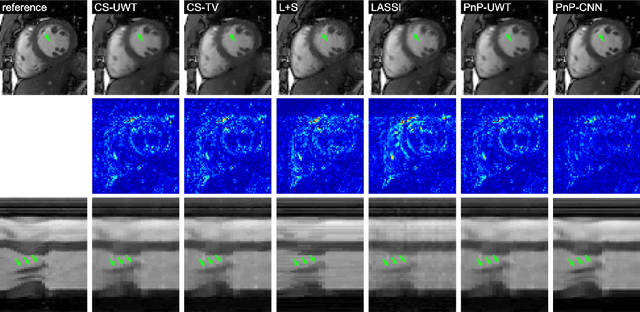
Magnetic Resonance Imaging (MRI) is a non-invasive diagnostic tool that provides excellent soft-tissue contrast without the use of ionizing radiation. But, compared to other clinical imaging modalities (e.g., CT or ultrasound), the data acquisition process for MRI is inherently slow. Furthermore, dynamic applications demand collecting a series of images in quick succession. As a result, reducing acquisition time and improving imaging quality for undersampled datasets have been active areas of research for the last two decades. The combination of parallel imaging and compressive sensing (CS) has been shown to benefit a wide range of MRI applications. More recently, deep learning techniques have been shown to outperform CS methods. Some of these techniques pose the MRI reconstruction as a direct inversion problem and tackle it by training a deep neural network (DNN) to map from the measured Fourier samples and the final image. Considering that the forward model in MRI changes from one dataset to the next, such methods have to be either trained over a large and diverse corpus of data or limited to a specific application, and even then they cannot ensure data consistency. An alternative is to use "plug-and-play" (PnP) algorithms, which iterate image denoising with forward-model based signal recovery. PnP algorithms are an excellent fit for compressive MRI because they decouple image modeling from the forward model, which can change significantly among different scans due to variations in the coil sensitivity maps, sampling patterns, and image resolution. Consequently, with PnP, state-of-the-art image-denoising techniques, such as those based on DNNs, can be directly exploited for compressive MRI image reconstruction. The objective of this article is two-fold: i) to review recent advances in plug-and-play methods, and ii) to discuss their application to compressive MRI image reconstruction.