 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Turbulence Mitigation: A Translational Perspective
Jan 08, 2024Recovering images distorted by atmospheric turbulence is a challenging inverse problem due to the stochastic nature of turbulence. Although numerous turbulence mitigation (TM) algorithms have been proposed, their efficiency and generalization to real-world dynamic scenarios remain severely limited. Building upon the intuitions of classical TM algorithms, we present the Deep Atmospheric TUrbulence Mitigation network (DATUM). DATUM aims to overcome major challenges when transitioning from classical to deep learning approaches. By carefully integrating the merits of classical multi-frame TM methods into a deep network structure, we demonstrate that DATUM can efficiently perform long-range temporal aggregation using a recurrent fashion, while deformable attention and temporal-channel attention seamlessly facilitate pixel registration and lucky imaging. With additional supervision, tilt and blur degradation can be jointly mitigated. These inductive biases empower DATUM to significantly outperform existing methods while delivering a tenfold increase in processing speed. A large-scale training dataset, ATSyn, is presented as a co-invention to enable generalization in real turbulence. Our code and datasets will be available at \href{https://xg416.github.io/DATUM}{\textcolor{pink}{https://xg416.github.io/DATUM}}
FarSight: A Physics-Driven Whole-Body Biometric System at Large Distance and Altitude
Jun 29, 2023



Whole-body biometric recognition is an important area of research due to its vast applications in law enforcement, border security, and surveillance. This paper presents the end-to-end design, development and evaluation of FarSight, an innovative software system designed for whole-body (fusion of face, gait and body shape) biometric recognition. FarSight accepts videos from elevated platforms and drones as input and outputs a candidate list of identities from a gallery. The system is designed to address several challenges, including (i) low-quality imagery, (ii) large yaw and pitch angles, (iii) robust feature extraction to accommodate large intra-person variabilities and large inter-person similarities, and (iv) the large domain gap between training and test sets. FarSight combines the physics of imaging and deep learning models to enhance image restoration and biometric feature encoding. We test FarSight's effectiveness using the newly acquired IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) dataset. Notably, FarSight demonstrated a substantial performance increase on the BRIAR dataset, with gains of +11.82% Rank-20 identification and +11.3% TAR@1% FAR.
Structured Kernel Estimation for Photon-Limited Deconvolution
Mar 06, 2023



Images taken in a low light condition with the presence of camera shake suffer from motion blur and photon shot noise. While state-of-the-art image restoration networks show promising results, they are largely limited to well-illuminated scenes and their performance drops significantly when photon shot noise is strong. In this paper, we propose a new blur estimation technique customized for photon-limited conditions. The proposed method employs a gradient-based backpropagation method to estimate the blur kernel. By modeling the blur kernel using a low-dimensional representation with the key points on the motion trajectory, we significantly reduce the search space and improve the regularity of the kernel estimation problem. When plugged into an iterative framework, our novel low-dimensional representation provides improved kernel estimates and hence significantly better deconvolution performance when compared to end-to-end trained neural networks. The source code and pretrained models are available at \url{https://github.com/sanghviyashiitb/structured-kernel-cvpr23}
Real-Time Dense Field Phase-to-Space Simulation of Imaging through Atmospheric Turbulence
Oct 13, 2022
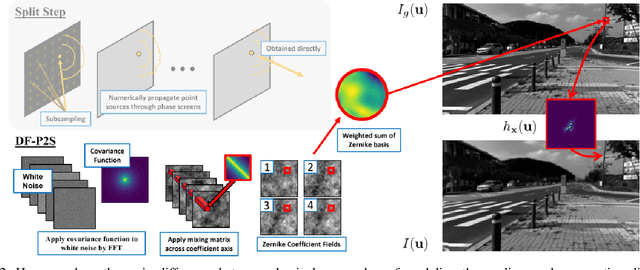


Numerical simulation of atmospheric turbulence is one of the biggest bottlenecks in developing computational techniques for solving the inverse problem in long-range imaging. The classical split-step method is based upon numerical wave propagation which splits the propagation path into many segments and propagates every pixel in each segment individually via the Fresnel integral. This repeated evaluation becomes increasingly time-consuming for larger images. As a result, the split-step simulation is often done only on a sparse grid of points followed by an interpolation to the other pixels. Even so, the computation is expensive for real-time applications. In this paper, we present a new simulation method that enables \emph{real-time} processing over a \emph{dense} grid of points. Building upon the recently developed multi-aperture model and the phase-to-space transform, we overcome the memory bottleneck in drawing random samples from the Zernike correlation tensor. We show that the cross-correlation of the Zernike modes has an insignificant contribution to the statistics of the random samples. By approximating these cross-correlation blocks in the Zernike tensor, we restore the homogeneity of the tensor which then enables Fourier-based random sampling. On a $512\times512$ image, the new simulator achieves 0.025 seconds per frame over a dense field. On a $3840 \times 2160$ image which would have taken 13 hours to simulate using the split-step method, the new simulator can run at approximately 60 seconds per frame.
Photon-Limited Blind Deconvolution using Unsupervised Iterative Kernel Estimation
Aug 02, 2022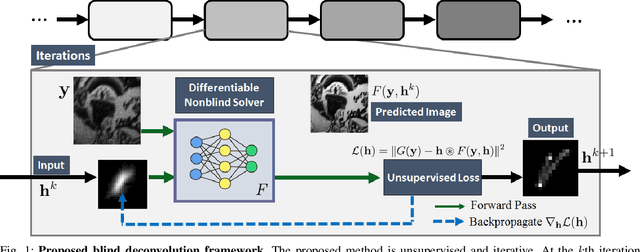
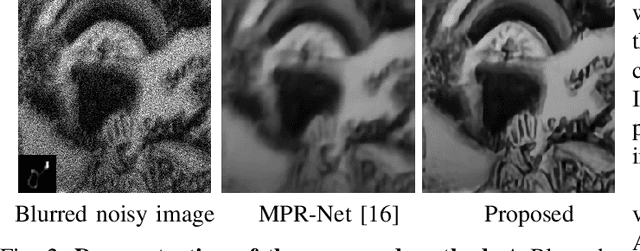
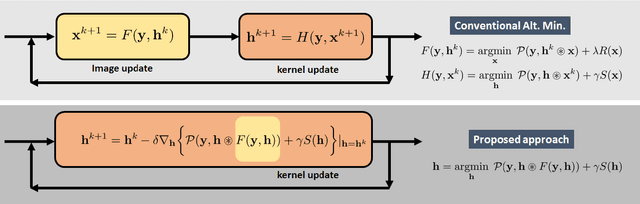
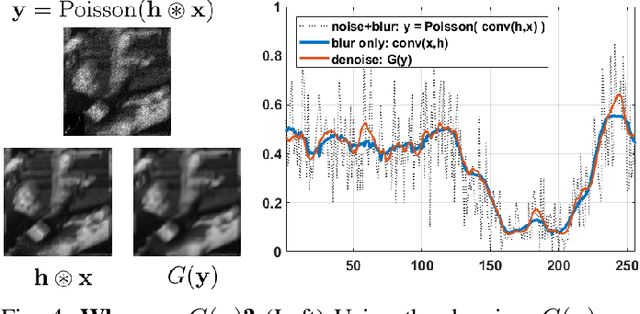
Blind deconvolution in low-light is one of the more challenging problems in image restoration because of the photon shot noise. However, existing algorithms -- both classical and deep-learning based -- are not designed for this condition. When the shot noise is strong, conventional deconvolution methods fail because (1) the presence of noise makes the estimation of the blur kernel difficult; (2) generic deep-restoration models rarely model the forward process explicitly; (3) there are currently no iterative strategies to incorporate a non-blind solver in a kernel estimation stage. This paper addresses these challenges by presenting an unsupervised blind deconvolution method. At the core of this method is a reformulation of the general blind deconvolution framework from the conventional image-kernel alternating minimization to a purely kernel-based minimization. This kernel-based minimization leads to a new iterative scheme that backpropagates an unsupervised loss through a pre-trained non-blind solver to update the blur kernel. Experimental results show that the proposed framework achieves superior results than state-of-the-art blind deconvolution algorithms in low-light conditions.
Single Frame Atmospheric Turbulence Mitigation: A Benchmark Study and A New Physics-Inspired Transformer Model
Jul 24, 2022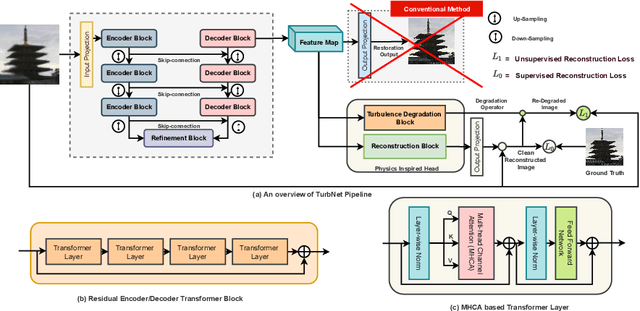


Image restoration algorithms for atmospheric turbulence are known to be much more challenging to design than traditional ones such as blur or noise because the distortion caused by the turbulence is an entanglement of spatially varying blur, geometric distortion, and sensor noise. Existing CNN-based restoration methods built upon convolutional kernels with static weights are insufficient to handle the spatially dynamical atmospheric turbulence effect. To address this problem, in this paper, we propose a physics-inspired transformer model for imaging through atmospheric turbulence. The proposed network utilizes the power of transformer blocks to jointly extract a dynamical turbulence distortion map and restore a turbulence-free image. In addition, recognizing the lack of a comprehensive dataset, we collect and present two new real-world turbulence datasets that allow for evaluation with both classical objective metrics (e.g., PSNR and SSIM) and a new task-driven metric using text recognition accuracy. Both real testing sets and all related code will be made publicly available.
Imaging through the Atmosphere using Turbulence Mitigation Transformer
Jul 13, 2022



Restoring images distorted by atmospheric turbulence is a long-standing problem due to the spatially varying nature of the distortion, nonlinearity of the image formation process, and scarcity of training and testing data. Existing methods often have strong statistical assumptions on the distortion model which in many cases will lead to a limited performance in real-world scenarios as they do not generalize. To overcome the challenge, this paper presents an end-to-end physics-driven approach that is efficient and can generalize to real-world turbulence. On the data synthesis front, we significantly increase the image resolution that can be handled by the SOTA turbulence simulator by approximating the random field via wide-sense stationarity. The new data synthesis process enables the generation of large-scale multi-level turbulence and ground truth pairs for training. On the network design front, we propose the turbulence mitigation transformer (TMT), a two stage U-Net shaped multi-frame restoration network which has a noval efficient self-attention mechanism named temporal channel joint attention (TCJA). We also introduce a new training scheme that is enabled by the new simulator, and we design new transformer units to reduce the memory consumption. Experimental results on both static and dynamic scenes are promising, including various real turbulence scenarios.
Accelerating Atmospheric Turbulence Simulation via Learned Phase-to-Space Transform
Aug 20, 2021



Fast and accurate simulation of imaging through atmospheric turbulence is essential for developing turbulence mitigation algorithms. Recognizing the limitations of previous approaches, we introduce a new concept known as the phase-to-space (P2S) transform to significantly speed up the simulation. P2S is build upon three ideas: (1) reformulating the spatially varying convolution as a set of invariant convolutions with basis functions, (2) learning the basis function via the known turbulence statistics models, (3) implementing the P2S transform via a light-weight network that directly convert the phase representation to spatial representation. The new simulator offers 300x -- 1000x speed up compared to the mainstream split-step simulators while preserving the essential turbulence statistics.
Student-Teacher Learning from Clean Inputs to Noisy Inputs
Mar 13, 2021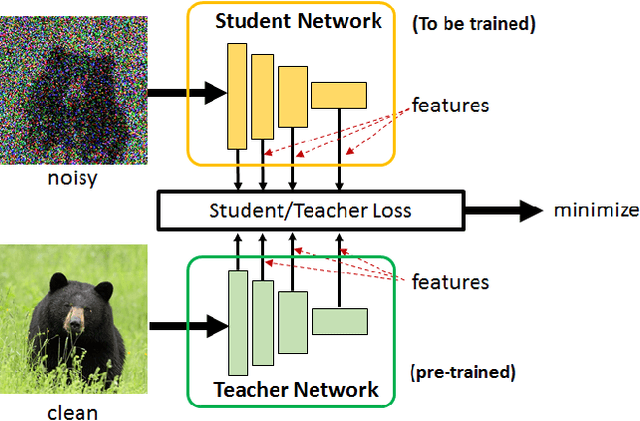

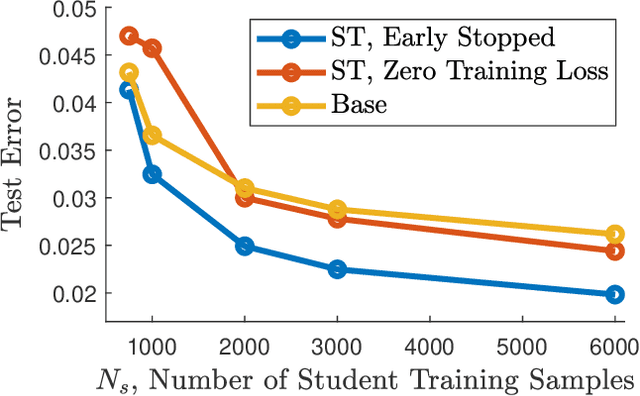
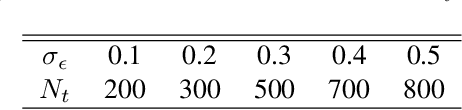
Feature-based student-teacher learning, a training method that encourages the student's hidden features to mimic those of the teacher network, is empirically successful in transferring the knowledge from a pre-trained teacher network to the student network. Furthermore, recent empirical results demonstrate that, the teacher's features can boost the student network's generalization even when the student's input sample is corrupted by noise. However, there is a lack of theoretical insights into why and when this method of transferring knowledge can be successful between such heterogeneous tasks. We analyze this method theoretically using deep linear networks, and experimentally using nonlinear networks. We identify three vital factors to the success of the method: (1) whether the student is trained to zero training loss; (2) how knowledgeable the teacher is on the clean-input problem; (3) how the teacher decomposes its knowledge in its hidden features. Lack of proper control in any of the three factors leads to failure of the student-teacher learning method.
Image Reconstruction of Static and Dynamic Scenes through Anisoplanatic Turbulence
Aug 31, 2020

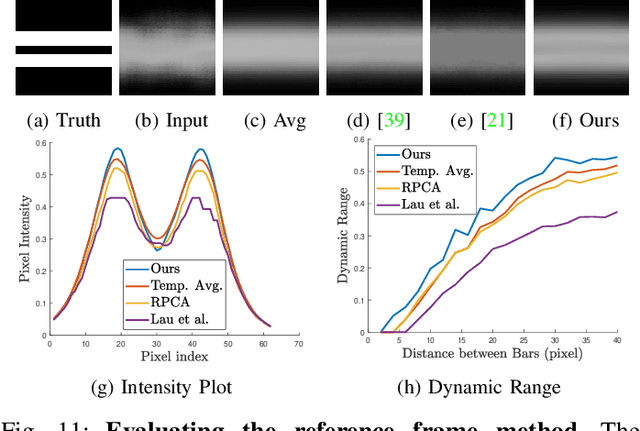

Ground based long-range passive imaging systems often suffer from degraded image quality due to a turbulent atmosphere. While methods exist for removing such turbulent distortions, many are limited to static sequences which cannot be extended to dynamic scenes. In addition, the physics of the turbulence is often not integrated into the image reconstruction algorithms, making the physics foundations of the methods weak. In this paper, we present a unified method for atmospheric turbulence mitigation in both static and dynamic sequences. We are able to achieve better results compared to existing methods by utilizing (i) a novel space-time non-local averaging method to construct a reliable reference frame, (ii) a geometric consistency and a sharpness metric to generate the lucky frame, (iii) a physics-constrained prior model of the point spread function for blind deconvolution. Experimental results based on synthetic and real long-range turbulence sequences validate the performance of the proposed method.