 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaTele: Compact Refractive Metasurface Computational Telephoto Camera
Apr 08, 2026Smartphone cameras face fundamental form-factor constraints that limit their optical magnification, primarily due to the difficulty of reducing a lens assembly's telephoto ratio, the ratio between total track length (TTL) and effective focal length (EFL). Currently, conventional refractive optics struggle to achieve a telephoto ratio below 0.5 without requiring multiple bulky elements to correct optical aberrations. In this paper, we introduce MetaTele, a novel optics-algorithm co-design that breaks this bottleneck. MetaTele explicitly decouples the acquisition of scene structure and color information. First, it utilizes a compact refractive-metasurface optical assembly to capture a fine-detail structure image under a narrow wavelength band, inherently avoiding severe chromatic aberrations. Second, it captures a broadband color cue using the same optics; although this cue is heavily corrupted by chromatic aberrations, it retains sufficient spectral information to guide post-processing. We then employ a custom one-step diffusion model to computationally fuse these two raw measurements, successfully colorizing the structure image while correcting for system aberrations. We demonstrate a MetaTele prototype, achieving an unprecedented telephoto ratio of 0.44 with a TTL of just 13 mm for RGB imaging, paving the way for DSLR-level telephoto capabilities within smartphone form factors.
Diffusion Algorithm for Metalens Optical Aberration Correction
Nov 16, 2025
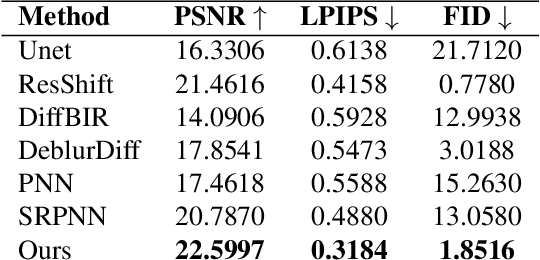


Metalenses offer a path toward creating ultra-thin optical systems, but they inherently suffer from severe, spatially varying optical aberrations, especially chromatic aberration, which makes image reconstruction a significant challenge. This paper presents a novel algorithmic solution to this problem, designed to reconstruct a sharp, full-color image from two inputs: a sharp, bandpass-filtered grayscale ``structure image'' and a heavily distorted ``color cue'' image, both captured by the metalens system. Our method utilizes a dual-branch diffusion model, built upon a pre-trained Stable Diffusion XL framework, to fuse information from the two inputs. We demonstrate through quantitative and qualitative comparisons that our approach significantly outperforms existing deblurring and pansharpening methods, effectively restoring high-frequency details while accurately colorizing the image.
Quanta Video Restoration
Oct 19, 2024The proliferation of single-photon image sensors has opened the door to a plethora of high-speed and low-light imaging applications. However, data collected by these sensors are often 1-bit or few-bit, and corrupted by noise and strong motion. Conventional video restoration methods are not designed to handle this situation, while specialized quanta burst algorithms have limited performance when the number of input frames is low. In this paper, we introduce Quanta Video Restoration (QUIVER), an end-to-end trainable network built on the core ideas of classical quanta restoration methods, i.e., pre-filtering, flow estimation, fusion, and refinement. We also collect and publish I2-2000FPS, a high-speed video dataset with the highest temporal resolution of 2000 frames-per-second, for training and testing. On simulated and real data, QUIVER outperforms existing quanta restoration methods by a significant margin. Code and dataset available at https://github.com/chennuriprateek/Quanta_Video_Restoration-QUIVER-
The Secrets of Non-Blind Poisson Deconvolution
Sep 06, 2023Non-blind image deconvolution has been studied for several decades but most of the existing work focuses on blur instead of noise. In photon-limited conditions, however, the excessive amount of shot noise makes traditional deconvolution algorithms fail. In searching for reasons why these methods fail, we present a systematic analysis of the Poisson non-blind deconvolution algorithms reported in the literature, covering both classical and deep learning methods. We compile a list of five "secrets" highlighting the do's and don'ts when designing algorithms. Based on this analysis, we build a proof-of-concept method by combining the five secrets. We find that the new method performs on par with some of the latest methods while outperforming some older ones.
Photon-Limited Blind Deconvolution using Unsupervised Iterative Kernel Estimation
Aug 02, 2022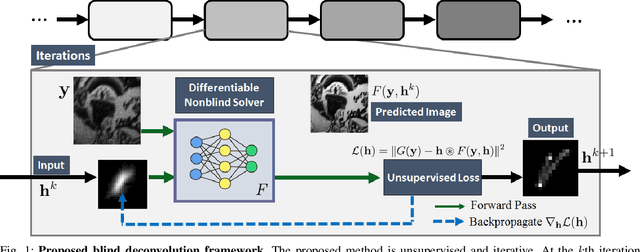
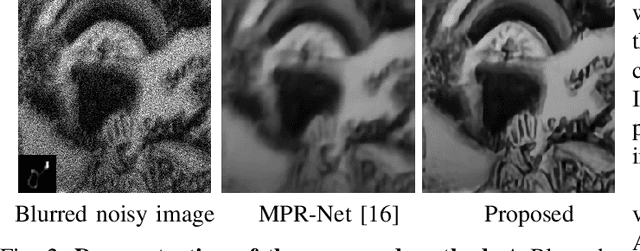
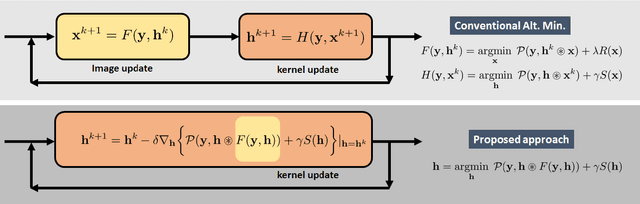
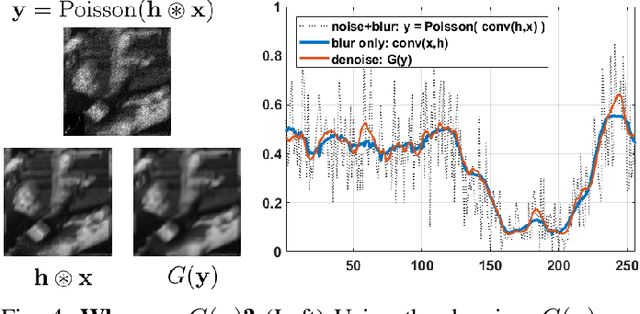
Blind deconvolution in low-light is one of the more challenging problems in image restoration because of the photon shot noise. However, existing algorithms -- both classical and deep-learning based -- are not designed for this condition. When the shot noise is strong, conventional deconvolution methods fail because (1) the presence of noise makes the estimation of the blur kernel difficult; (2) generic deep-restoration models rarely model the forward process explicitly; (3) there are currently no iterative strategies to incorporate a non-blind solver in a kernel estimation stage. This paper addresses these challenges by presenting an unsupervised blind deconvolution method. At the core of this method is a reformulation of the general blind deconvolution framework from the conventional image-kernel alternating minimization to a purely kernel-based minimization. This kernel-based minimization leads to a new iterative scheme that backpropagates an unsupervised loss through a pre-trained non-blind solver to update the blur kernel. Experimental results show that the proposed framework achieves superior results than state-of-the-art blind deconvolution algorithms in low-light conditions.
Exposure-Referred Signal-to-Noise Ratio for Digital Image Sensors
Dec 10, 2021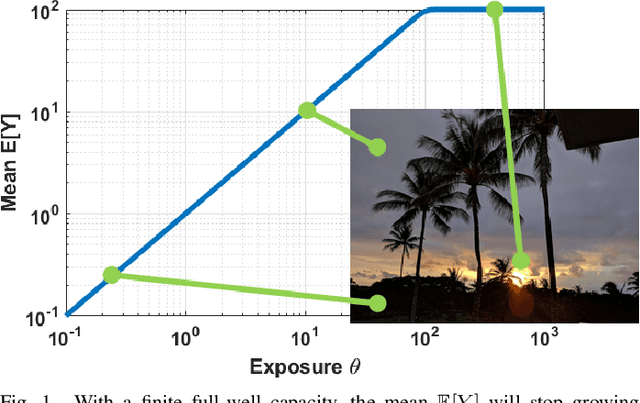
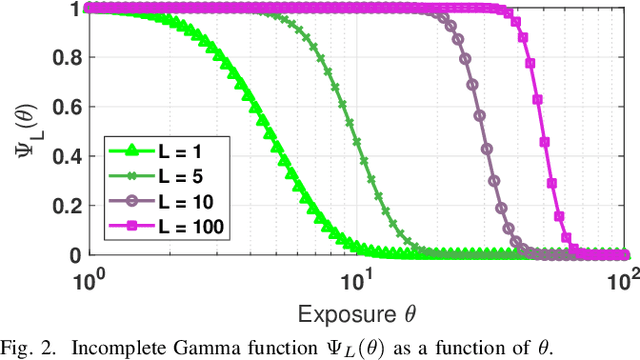
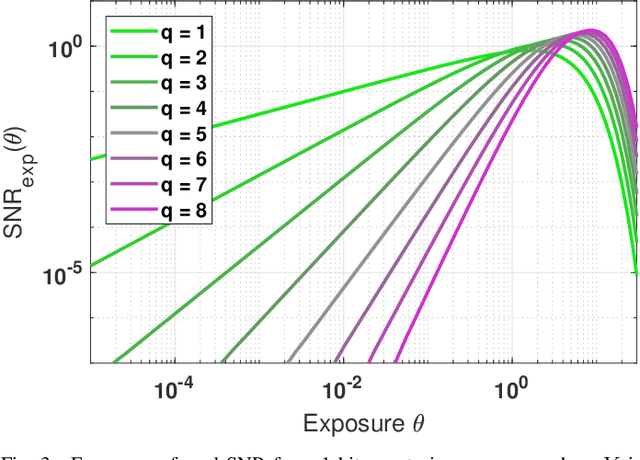
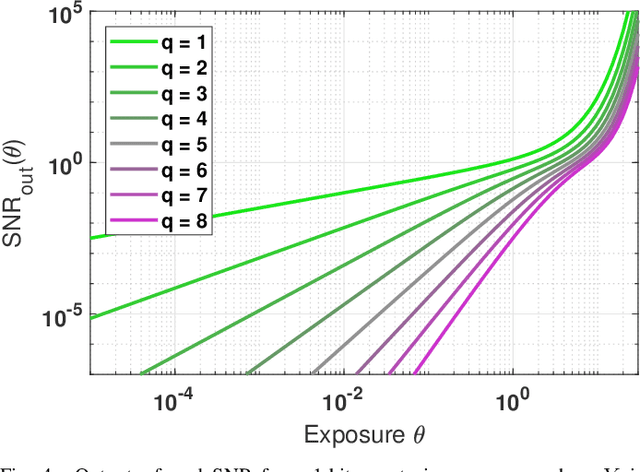
The signal-to-noise ratio (SNR) of a digital image sensor is typically defined as the ratio between the mean over the standard deviation of the sensor's output, thus known as the output-referred SNR. For sensors with a large full-well capacity, the output-referred SNR demonstrates the well-known linear response in the log-log scale. However, as the input exposure approaches the full-well capacity, the vanishing randomness of the saturated pixel will cause this output-referred SNR to artificially go to infinity. Since modern digital image sensors have a small pitch and hence a small full-well capacity, the shortcomings of the output-referred SNR motivated the development of a theoretical concept known as the exposure-referred SNR, first reported in some sensors and computer vision papers in the 1990's and more since 2010. Some intuitions of the exposure-referred SNR have been discussed in the past, but little is known how the exposure-referred SNR can be rigorously derived. Recognizing the significance of such an analysis to all present and future small pixels, this paper presents a theoretical analysis to justify the definition and answer four questions: (1) What is the correct definition of SNR? (2) How is the output-referred SNR related to the exposure-referred SNR? (3) For simple noise models, the SNRs can be analytically derived, but for complex noise models, how to numerically compute the SNR? (4) What utilities can the exposure-referred SNR bring to solving imaging tasks? New theoretical results are shown to confirm the validity of the exposure-referred SNR for image sensors of any bit-depth and full-well capacity.
Graph-Based Depth Denoising & Dequantization for Point Cloud Enhancement
Nov 09, 2021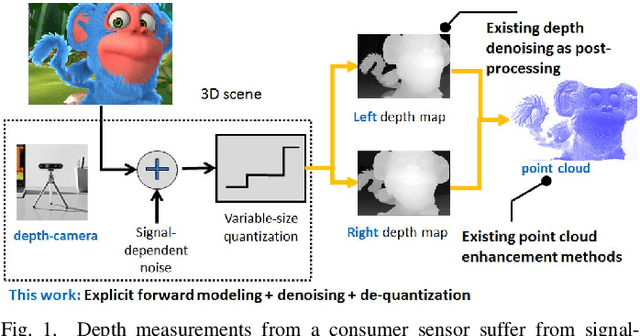
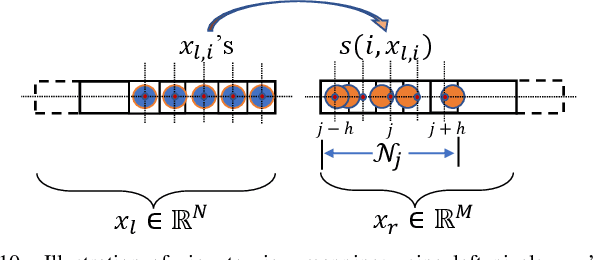
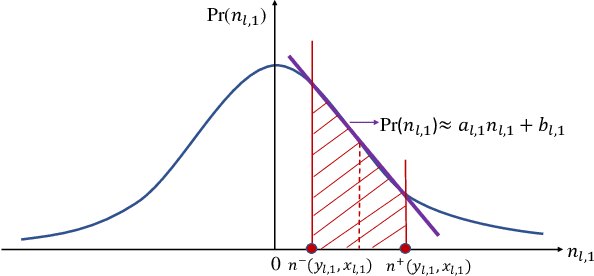
A 3D point cloud is typically constructed from depth measurements acquired by sensors at one or more viewpoints. The measurements suffer from both quantization and noise corruption. To improve quality, previous works denoise a point cloud \textit{a posteriori} after projecting the imperfect depth data onto 3D space. Instead, we enhance depth measurements directly on the sensed images \textit{a priori}, before synthesizing a 3D point cloud. By enhancing near the physical sensing process, we tailor our optimization to our depth formation model before subsequent processing steps that obscure measurement errors. Specifically, we model depth formation as a combined process of signal-dependent noise addition and non-uniform log-based quantization. The designed model is validated (with parameters fitted) using collected empirical data from an actual depth sensor. To enhance each pixel row in a depth image, we first encode intra-view similarities between available row pixels as edge weights via feature graph learning. We next establish inter-view similarities with another rectified depth image via viewpoint mapping and sparse linear interpolation. This leads to a maximum a posteriori (MAP) graph filtering objective that is convex and differentiable. We optimize the objective efficiently using accelerated gradient descent (AGD), where the optimal step size is approximated via Gershgorin circle theorem (GCT). Experiments show that our method significantly outperformed recent point cloud denoising schemes and state-of-the-art image denoising schemes, in two established point cloud quality metrics.
Photon Limited Non-Blind Deblurring Using Algorithm Unrolling
Oct 29, 2021


Image deblurring in photon-limited conditions is ubiquitous in a variety of low-light applications such as photography, microscopy and astronomy. However, the presence of photon shot noise due to low-illumination and/or short exposure makes the deblurring task substantially more challenging than the conventional deblurring problems. In this paper we present an algorithm unrolling approach for the photon-limited deblurring problem by unrolling a Plug-and-Play algorithm for a fixed number of iterations. By introducing a three-operator splitting formation of the Plug-and-Play framework, we obtain a series of differentiable steps which allows the fixed iteration unrolled network to be trained end-to-end. The proposed algorithm demonstrates significantly better image recovery compared to existing state-of-the-art deblurring approaches. We also present a new photon-limited deblurring dataset for evaluating the performance of algorithms.
Optical Adversarial Attack
Aug 16, 2021
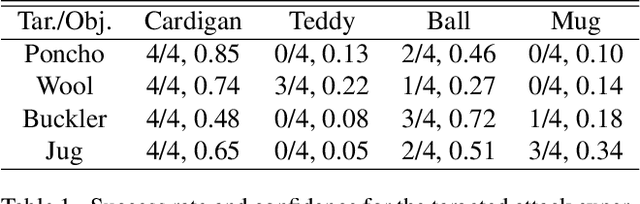


We introduce OPtical ADversarial attack (OPAD). OPAD is an adversarial attack in the physical space aiming to fool image classifiers without physically touching the objects (e.g., moving or painting the objects). The principle of OPAD is to use structured illumination to alter the appearance of the target objects. The system consists of a low-cost projector, a camera, and a computer. The challenge of the problem is the non-linearity of the radiometric response of the projector and the spatially varying spectral response of the scene. Attacks generated in a conventional approach do not work in this setting unless they are calibrated to compensate for such a projector-camera model. The proposed solution incorporates the projector-camera model into the adversarial attack optimization, where a new attack formulation is derived. Experimental results prove the validity of the solution. It is demonstrated that OPAD can optically attack a real 3D object in the presence of background lighting for white-box, black-box, targeted, and untargeted attacks. Theoretical analysis is presented to quantify the fundamental performance limit of the system.
HDR Imaging with Quanta Image Sensors: Theoretical Limits and Optimal Reconstruction
Nov 06, 2020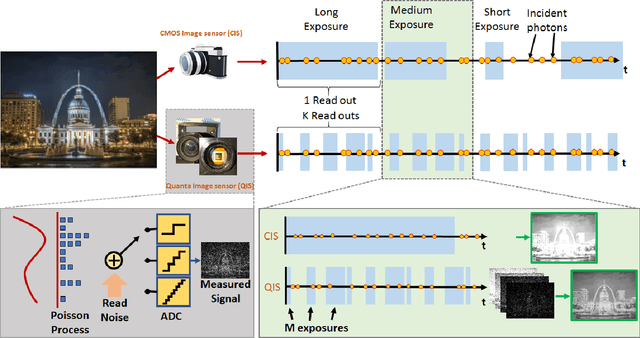
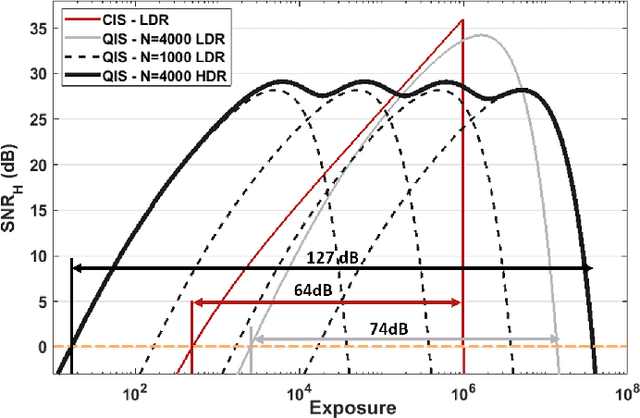

High dynamic range (HDR) imaging is one of the biggest achievements in modern photography. Traditional solutions to HDR imaging are designed for and applied to CMOS image sensors (CIS). However, the mainstream one-micron CIS cameras today generally have a high read noise and low frame-rate. These, in turn, limit the acquisition speed and quality, making the cameras slow in the HDR mode. In this paper, we propose a new computational photography technique for HDR imaging. Recognizing the limitations of CIS, we use the Quanta Image Sensor (QIS) to trade the spatial-temporal resolution with bit-depth. QIS is a single-photon image sensor that has comparable pixel pitch to CIS but substantially lower dark current and read noise. We provide a complete theoretical characterization of the sensor in the context of HDR imaging, by proving the fundamental limits in the dynamic range that QIS can offer and the trade-offs with noise and speed. In addition, we derive an optimal reconstruction algorithm for single-bit and multi-bit QIS. Our algorithm is theoretically optimal for \emph{all} linear reconstruction schemes based on exposure bracketing. Experimental results confirm the validity of the theory and algorithm, based on synthetic and real QIS data.