 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistogramless Time-Domain Sketched Fluorescence Lifetime Imaging
May 07, 2026We present a statistics-aware compression strategy that processes photon timestamps directly from time-correlated single-photon counting (TCSPC) modules for time-domain fluorescence lifetime imaging (FLIM). Rather than storing or transmitting the full histogram per pixel, timestamps are projected onto sparse, non-uniform one-dimensional spline sketches, with knot positions optimally allocated based on Fisher information. This knot allocation concentrates sketch channels where the decay signal exhibits the greatest statistical discriminability, rather than using a uniform allocation. The proposed approach is extensively validated on synthetic mono- and bi-exponential decay data and on experimental fluorescent dye data, demonstrating comparable accuracy to full-histogram non-linear least-squares fitting (NLSF) and Poisson maximum-likelihood estimation (MLE) at compression ratios of up to 256x. We further validate the feasibility of integrating the timestamp-to-sketch projection directly into firmware via fixed-point (FXP) lookup-table (LUT) simulation, targeting high-spatial-resolution single-photon avalanche diode (SPAD) arrays subject to significant data-throughput constraints.
FPGA Implementation of Sketched LiDAR for a 192 x 128 SPAD Image Sensor
Feb 11, 2026This study presents an efficient field-programmable gate array (FPGA) implementation of a polynomial spline function-based statistical compression algorithm designed to address the critical challenge of massive data transfer bandwidth in emerging high-spatial-resolution single-photon avalanche diode (SPAD) arrays, where data rates can reach tens of gigabytes per second. In our experiments, the proposed hardware implementation achieves a compression ratio of 512x compared with conventional histogram-based outputs, with the potential for further improvement. The algorithm is first optimized in software using fixed-point (FXP) arithmetic and look-up tables (LUTs) to eliminate explicit additions, multiplications, and non-linear operations. This enables a careful balance between accuracy and hardware resource utilization. Guided by this trade-off analysis, online sketch processing elements (SPEs) are implemented on an FPGA to directly process time-stamp streams from the SPAD sensor. The implementation is validated using a customized LiDAR setup with a 192 x 128-pixel SPAD array. This work demonstrates histogram-free online depth reconstruction with high fidelity, effectively alleviating the time-stamp transfer bottleneck of SPAD arrays and offering scalability as pixel counts continue to increase for future SPADs.
Joint Depth and Reflectivity Estimation using Single-Photon LiDAR
May 19, 2025Single-Photon Light Detection and Ranging (SP-LiDAR is emerging as a leading technology for long-range, high-precision 3D vision tasks. In SP-LiDAR, timestamps encode two complementary pieces of information: pulse travel time (depth) and the number of photons reflected by the object (reflectivity). Existing SP-LiDAR reconstruction methods typically recover depth and reflectivity separately or sequentially use one modality to estimate the other. Moreover, the conventional 3D histogram construction is effective mainly for slow-moving or stationary scenes. In dynamic scenes, however, it is more efficient and effective to directly process the timestamps. In this paper, we introduce an estimation method to simultaneously recover both depth and reflectivity in fast-moving scenes. We offer two contributions: (1) A theoretical analysis demonstrating the mutual correlation between depth and reflectivity and the conditions under which joint estimation becomes beneficial. (2) A novel reconstruction method, "SPLiDER", which exploits the shared information to enhance signal recovery. On both synthetic and real SP-LiDAR data, our method outperforms existing approaches, achieving superior joint reconstruction quality.
Quanta Video Restoration
Oct 19, 2024The proliferation of single-photon image sensors has opened the door to a plethora of high-speed and low-light imaging applications. However, data collected by these sensors are often 1-bit or few-bit, and corrupted by noise and strong motion. Conventional video restoration methods are not designed to handle this situation, while specialized quanta burst algorithms have limited performance when the number of input frames is low. In this paper, we introduce Quanta Video Restoration (QUIVER), an end-to-end trainable network built on the core ideas of classical quanta restoration methods, i.e., pre-filtering, flow estimation, fusion, and refinement. We also collect and publish I2-2000FPS, a high-speed video dataset with the highest temporal resolution of 2000 frames-per-second, for training and testing. On simulated and real data, QUIVER outperforms existing quanta restoration methods by a significant margin. Code and dataset available at https://github.com/chennuriprateek/Quanta_Video_Restoration-QUIVER-
Resolution Limit of Single-Photon LiDAR
Mar 31, 2024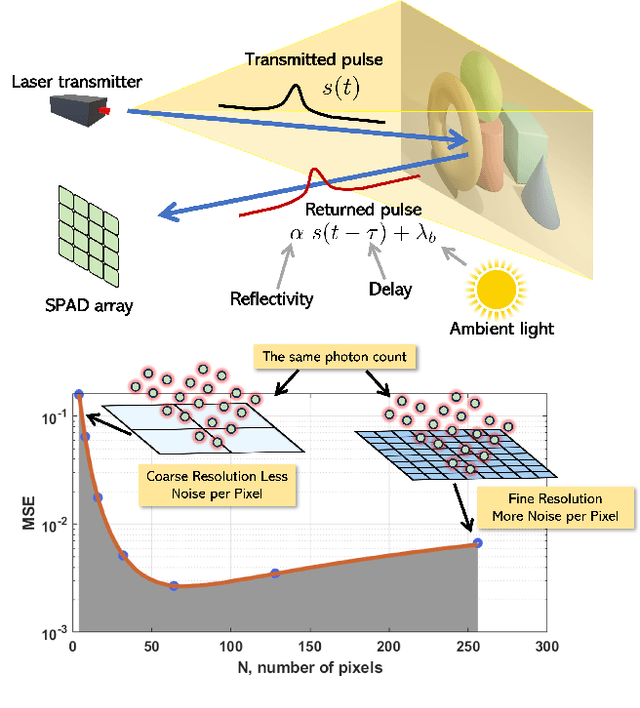

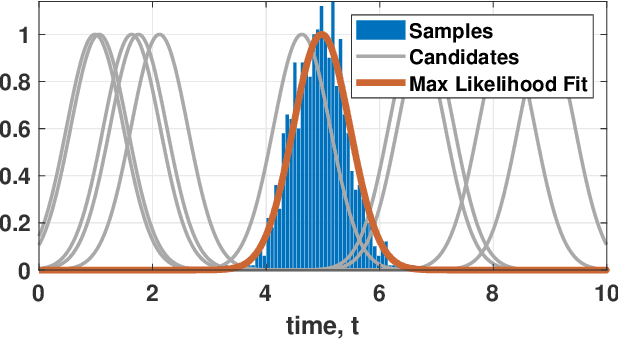
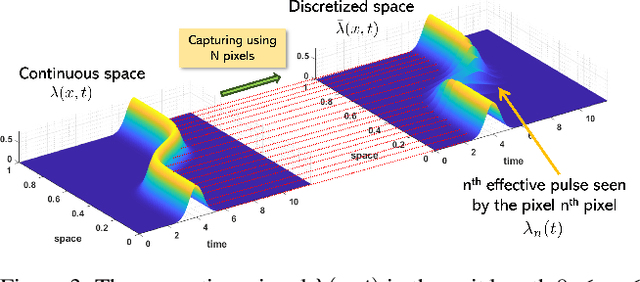
Single-photon Light Detection and Ranging (LiDAR) systems are often equipped with an array of detectors for improved spatial resolution and sensing speed. However, given a fixed amount of flux produced by the laser transmitter across the scene, the per-pixel Signal-to-Noise Ratio (SNR) will decrease when more pixels are packed in a unit space. This presents a fundamental trade-off between the spatial resolution of the sensor array and the SNR received at each pixel. Theoretical characterization of this fundamental limit is explored. By deriving the photon arrival statistics and introducing a series of new approximation techniques, the Mean Squared Error (MSE) of the maximum-likelihood estimator of the time delay is derived. The theoretical predictions align well with simulations and real data.
TDC-less Direct Time-of-Flight Imaging Using Spiking Neural Networks
Jan 19, 2024



3D depth sensors using single-photon avalanche diodes (SPADs) are becoming increasingly common in applications such as autonomous navigation and object detection. Recent designs implement on-chip histogramming time-to-digital converters (TDCs) to compress the photon timestamps and reduce the bottleneck in the read-out and processing of large volumes of photon data. However, the use of full histogramming with large SPAD arrays poses significant challenges due to the associated demands in silicon area and power consumption. We propose a TDC-less dToF sensor which uses Spiking Neural Networks (SNN) to process the SPAD events directly. The proposed SNN is trained and tested on synthetic SPAD events, and while it offers five times lower precision in depth prediction than a classic centre-of-mass (CoM) algorithm (applied to histograms of the events), it achieves similar Mean Absolute Error (MAE) with faster processing speeds and significantly lower power consumption is anticipated.
Video super-resolution for single-photon LIDAR
Oct 19, 2022
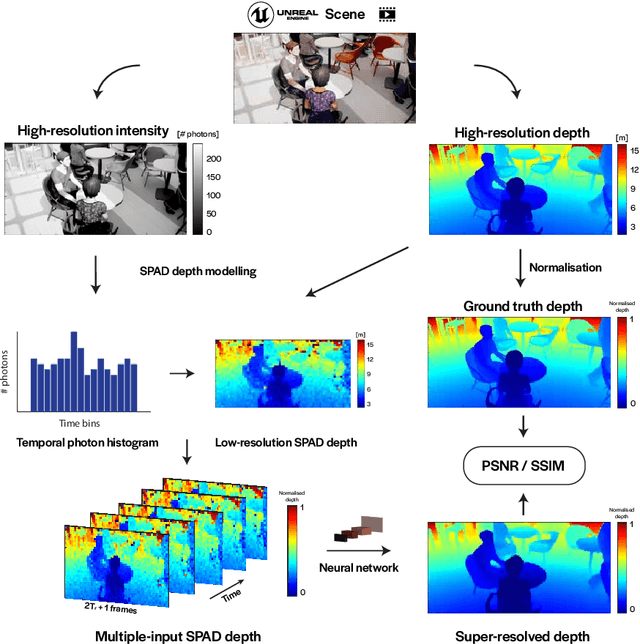
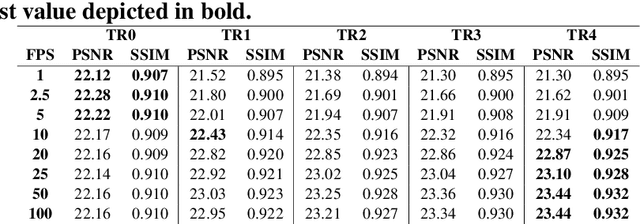
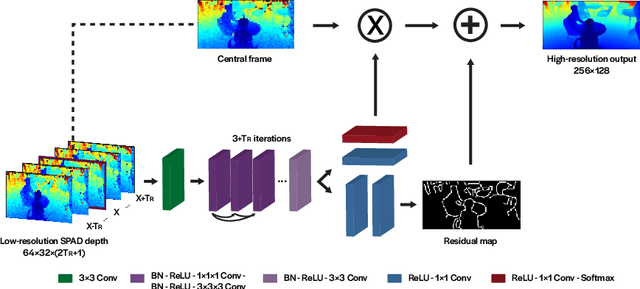
3D Time-of-Flight (ToF) image sensors are used widely in applications such as self-driving cars, Augmented Reality (AR) and robotics. When implemented with Single-Photon Avalanche Diodes (SPADs), compact, array format sensors can be made that offer accurate depth maps over long distances, without the need for mechanical scanning. However, array sizes tend to be small, leading to low lateral resolution, which combined with low Signal-to-Noise Ratio (SNR) levels under high ambient illumination, may lead to difficulties in scene interpretation. In this paper, we use synthetic depth sequences to train a 3D Convolutional Neural Network (CNN) for denoising and upscaling (x4) depth data. Experimental results, based on synthetic as well as real ToF data, are used to demonstrate the effectiveness of the scheme. With GPU acceleration, frames are processed at >30 frames per second, making the approach suitable for low-latency imaging, as required for obstacle avoidance.
Simulating single-photon detector array sensors for depth imaging
Oct 07, 2022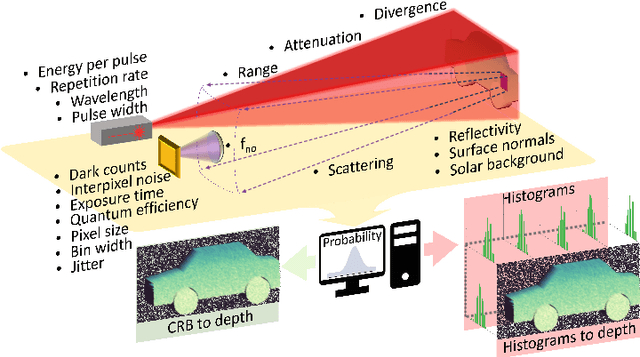
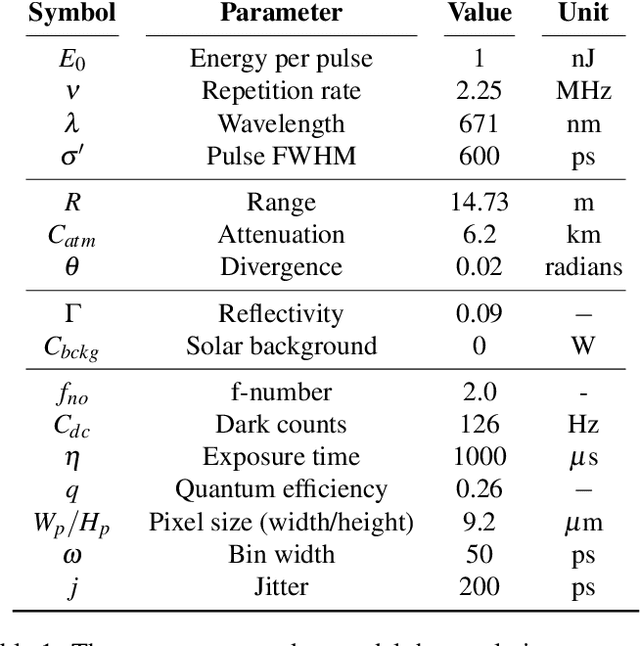
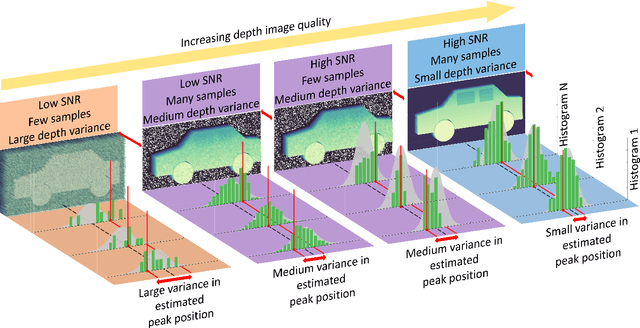
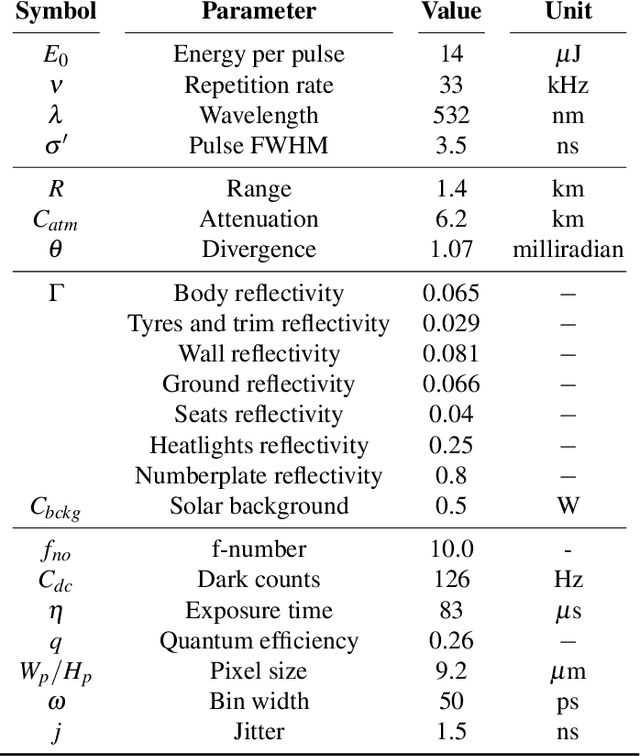
Single-Photon Avalanche Detector (SPAD) arrays are a rapidly emerging technology. These multi-pixel sensors have single-photon sensitivities and pico-second temporal resolutions thus they can rapidly generate depth images with millimeter precision. Such sensors are a key enabling technology for future autonomous systems as they provide guidance and situational awareness. However, to fully exploit the capabilities of SPAD array sensors, it is crucial to establish the quality of depth images they are able to generate in a wide range of scenarios. Given a particular optical system and a finite image acquisition time, what is the best-case depth resolution and what are realistic images generated by SPAD arrays? In this work, we establish a robust yet simple numerical procedure that rapidly establishes the fundamental limits to depth imaging with SPAD arrays under real world conditions. Our approach accurately generates realistic depth images in a wide range of scenarios, allowing the performance of an optical depth imaging system to be established without the need for costly and laborious field testing. This procedure has applications in object detection and tracking for autonomous systems and could be easily extended to systems for underwater imaging or for imaging around corners.
A direct time-of-flight image sensor with in-pixel surface detection and dynamic vision
Sep 23, 2022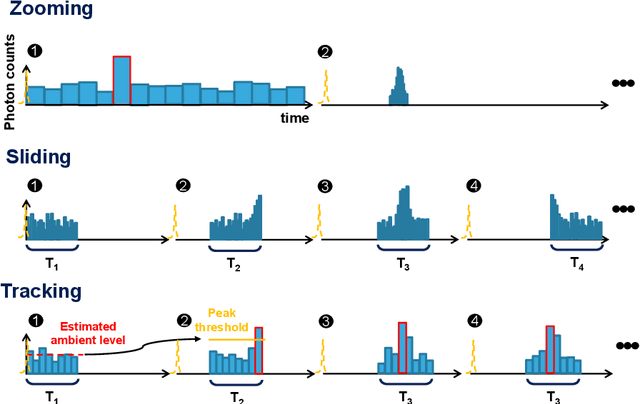
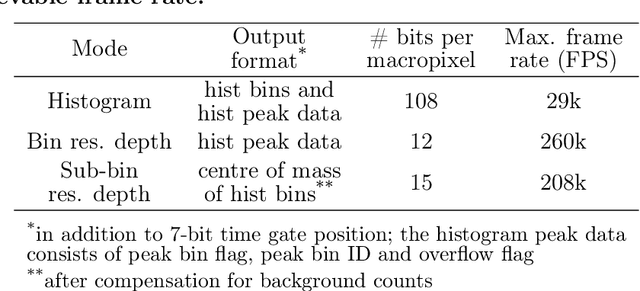
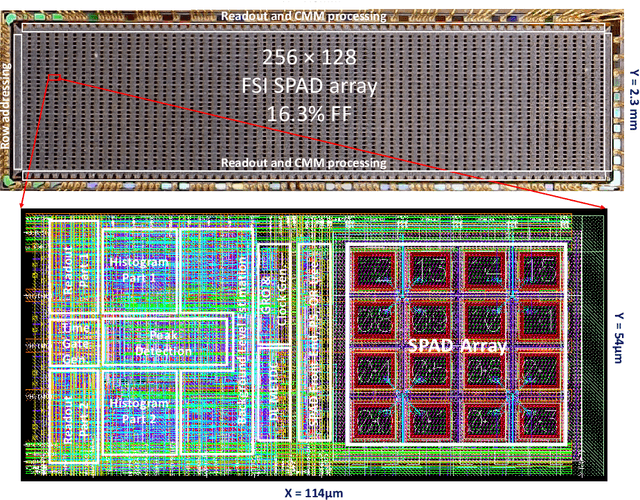
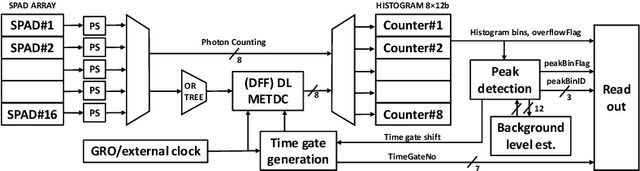
3D flash LIDAR is an alternative to the traditional scanning LIDAR systems, promising precise depth imaging in a compact form factor, and free of moving parts, for applications such as self-driving cars, robotics and augmented reality (AR). Typically implemented using single-photon, direct time-of-flight (dToF) receivers in image sensor format, the operation of the devices can be hindered by the large number of photon events needing to be processed and compressed in outdoor scenarios, limiting frame rates and scalability to larger arrays. We here present a 64x32 pixel (256x128 SPAD) dToF imager that overcomes these limitations by using pixels with embedded histogramming, which lock onto and track the return signal. This reduces the size of output data frames considerably, enabling maximum frame rates in the 10 kFPS range or 100 kFPS for direct depth readings. The sensor offers selective readout of pixels detecting surfaces, or those sensing motion, leading to reduced power consumption and off-chip processing requirements. We demonstrate the application of the sensor in mid-range LIDAR.
DronePose: The identification, segmentation, and orientation detection of drones via neural networks
Dec 10, 2021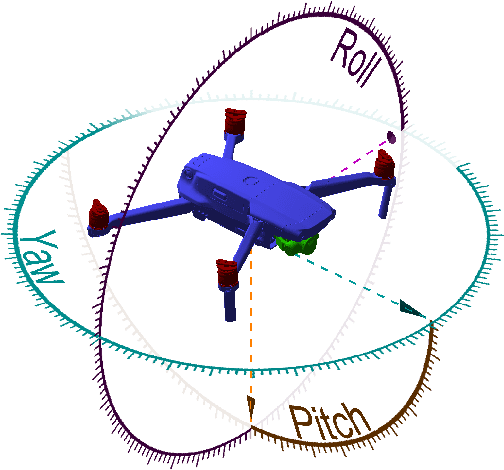
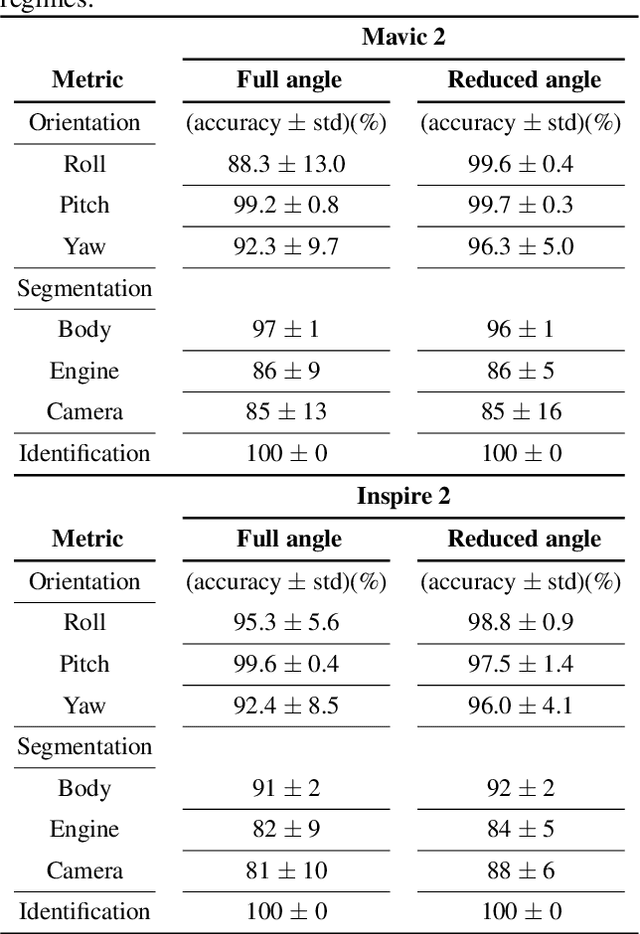
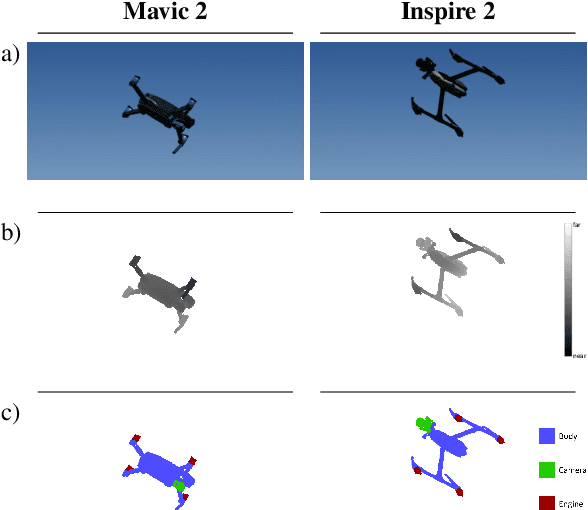

The growing ubiquity of drones has raised concerns over the ability of traditional air-space monitoring technologies to accurately characterise such vehicles. Here, we present a CNN using a decision tree and ensemble structure to fully characterise drones in flight. Our system determines the drone type, orientation (in terms of pitch, roll, and yaw), and performs segmentation to classify different body parts (engines, body, and camera). We also provide a computer model for the rapid generation of large quantities of accurately labelled photo-realistic training data and demonstrate that this data is of sufficient fidelity to allow the system to accurately characterise real drones in flight. Our network will provide a valuable tool in the image processing chain where it may build upon existing drone detection technologies to provide complete drone characterisation over wide areas.