 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Plug-and-Play Algorithm for 3D Video Super-Resolution of Single-Photon LiDAR data
Dec 12, 2024



Single-photon avalanche diodes (SPADs) are advanced sensors capable of detecting individual photons and recording their arrival times with picosecond resolution using time-correlated Single-Photon Counting detection techniques. They are used in various applications, such as LiDAR, and can capture high-speed sequences of binary single-photon images, offering great potential for reconstructing 3D environments with high motion dynamics. To complement single-photon data, they are often paired with conventional passive cameras, which capture high-resolution (HR) intensity images at a lower frame rate. However, 3D reconstruction from SPAD data faces challenges. Aggregating multiple binary measurements improves precision and reduces noise but can cause motion blur in dynamic scenes. Additionally, SPAD arrays often have lower resolution than passive cameras. To address these issues, we propose a novel computational imaging algorithm to improve the 3D reconstruction of moving scenes from SPAD data by addressing the motion blur and increasing the native spatial resolution. We adopt a plug-and-play approach within an optimization scheme alternating between guided video super-resolution of the 3D scene, and precise image realignment using optical flow. Experiments on synthetic data show significantly improved image resolutions across various signal-to-noise ratios and photon levels. We validate our method using real-world SPAD measurements on three practical situations with dynamic objects. First on fast-moving scenes in laboratory conditions at short range; second very low resolution imaging of people with a consumer-grade SPAD sensor from STMicroelectronics; and finally, HR imaging of people walking outdoors in daylight at a range of 325 meters under eye-safe illumination conditions using a short-wave infrared SPAD camera. These results demonstrate the robustness and versatility of our approach.
3D Target Detection and Spectral Classification for Single-photon LiDAR Data
Feb 20, 2023



3D single-photon LiDAR imaging has an important role in many applications. However, full deployment of this modality will require the analysis of low signal to noise ratio target returns and a very high volume of data. This is particularly evident when imaging through obscurants or in high ambient background light conditions. This paper proposes a multiscale approach for 3D surface detection from the photon timing histogram to permit a significant reduction in data volume. The resulting surfaces are background-free and can be used to infer depth and reflectivity information about the target. We demonstrate this by proposing a hierarchical Bayesian model for 3D reconstruction and spectral classification of multispectral single-photon LiDAR data. The reconstruction method promotes spatial correlation between point-cloud estimates and uses a coordinate gradient descent algorithm for parameter estimation. Results on simulated and real data show the benefits of the proposed target detection and reconstruction approaches when compared to state-of-the-art processing algorithms
Video super-resolution for single-photon LIDAR
Oct 19, 2022
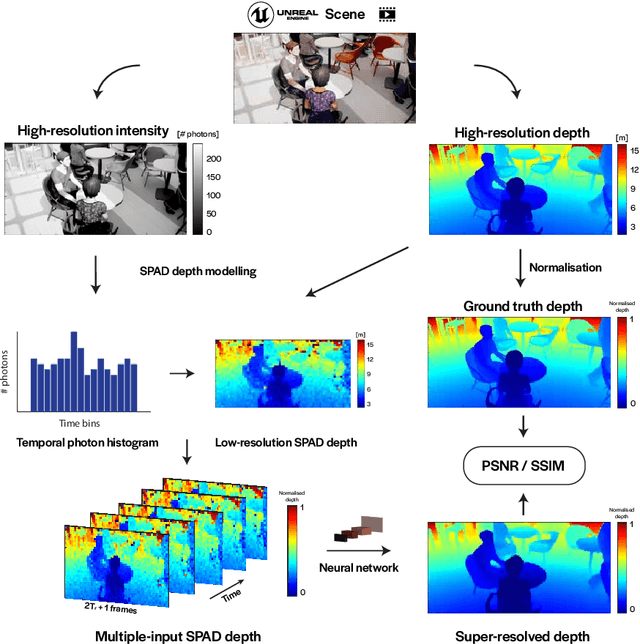
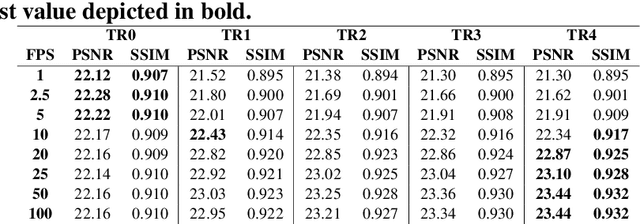
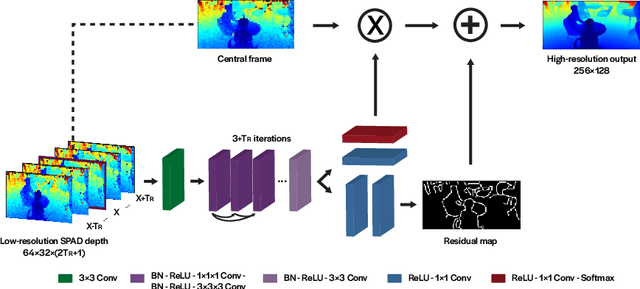
3D Time-of-Flight (ToF) image sensors are used widely in applications such as self-driving cars, Augmented Reality (AR) and robotics. When implemented with Single-Photon Avalanche Diodes (SPADs), compact, array format sensors can be made that offer accurate depth maps over long distances, without the need for mechanical scanning. However, array sizes tend to be small, leading to low lateral resolution, which combined with low Signal-to-Noise Ratio (SNR) levels under high ambient illumination, may lead to difficulties in scene interpretation. In this paper, we use synthetic depth sequences to train a 3D Convolutional Neural Network (CNN) for denoising and upscaling (x4) depth data. Experimental results, based on synthetic as well as real ToF data, are used to demonstrate the effectiveness of the scheme. With GPU acceleration, frames are processed at >30 frames per second, making the approach suitable for low-latency imaging, as required for obstacle avoidance.
Simulating single-photon detector array sensors for depth imaging
Oct 07, 2022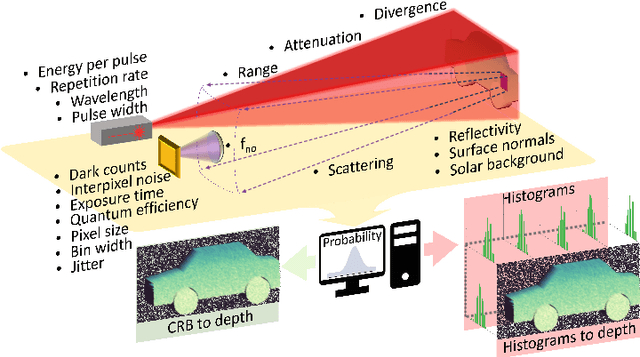
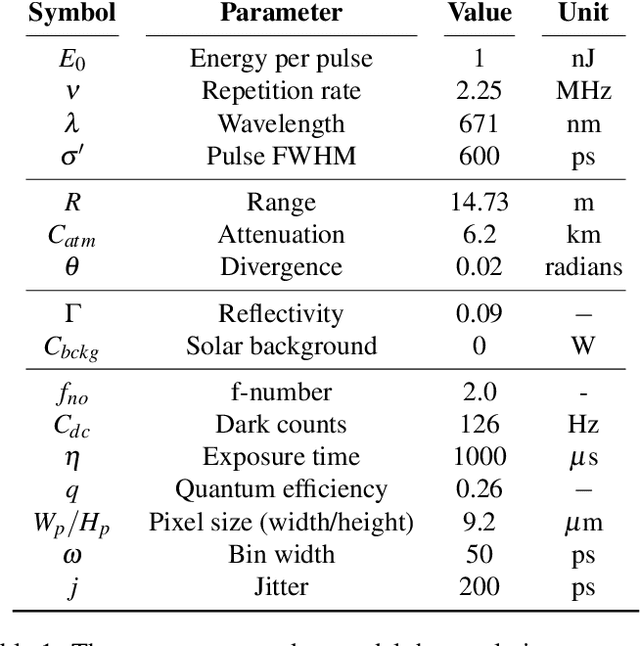
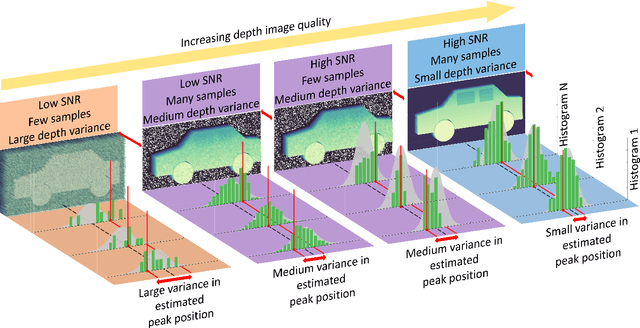
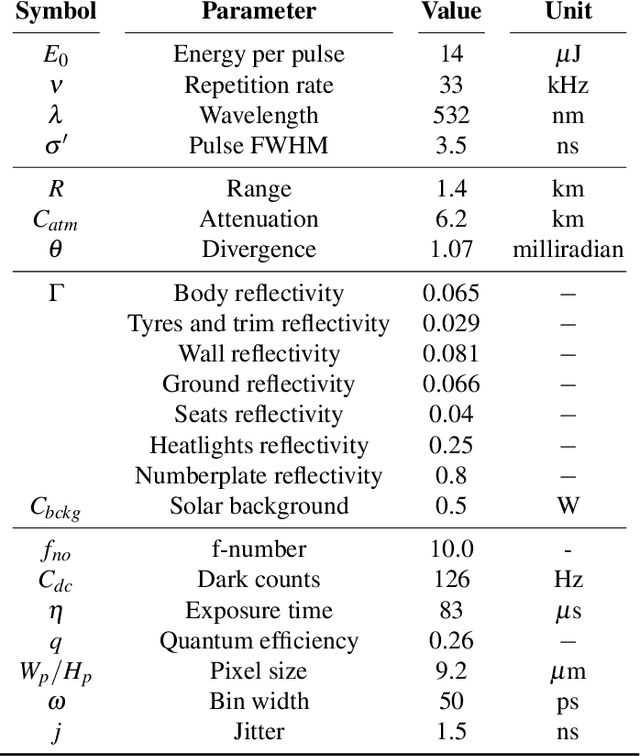
Single-Photon Avalanche Detector (SPAD) arrays are a rapidly emerging technology. These multi-pixel sensors have single-photon sensitivities and pico-second temporal resolutions thus they can rapidly generate depth images with millimeter precision. Such sensors are a key enabling technology for future autonomous systems as they provide guidance and situational awareness. However, to fully exploit the capabilities of SPAD array sensors, it is crucial to establish the quality of depth images they are able to generate in a wide range of scenarios. Given a particular optical system and a finite image acquisition time, what is the best-case depth resolution and what are realistic images generated by SPAD arrays? In this work, we establish a robust yet simple numerical procedure that rapidly establishes the fundamental limits to depth imaging with SPAD arrays under real world conditions. Our approach accurately generates realistic depth images in a wide range of scenarios, allowing the performance of an optical depth imaging system to be established without the need for costly and laborious field testing. This procedure has applications in object detection and tracking for autonomous systems and could be easily extended to systems for underwater imaging or for imaging around corners.
DronePose: The identification, segmentation, and orientation detection of drones via neural networks
Dec 10, 2021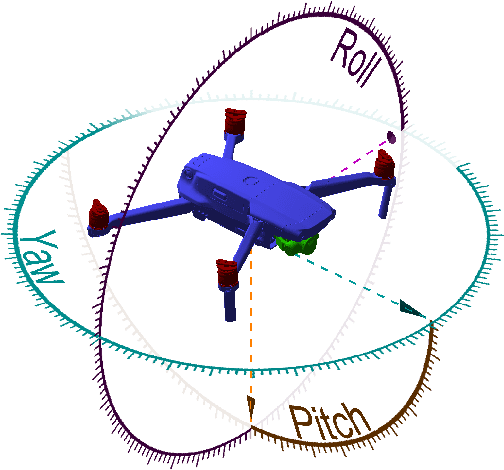
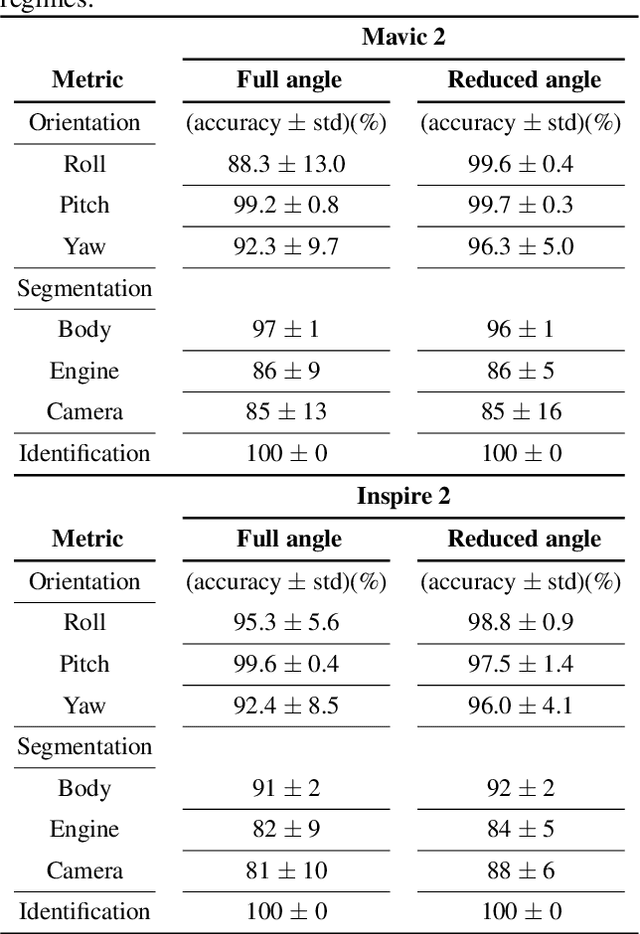
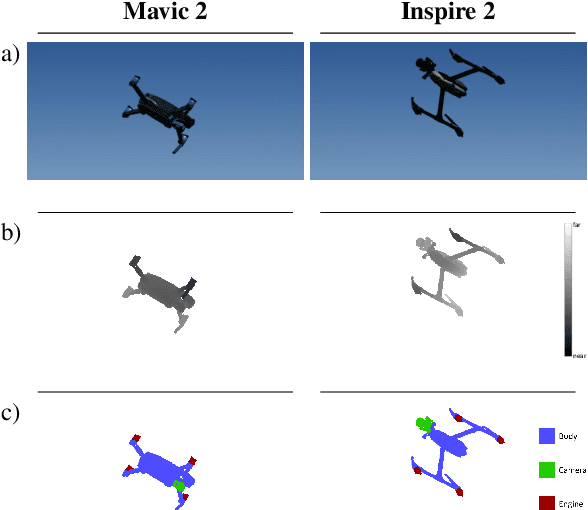

The growing ubiquity of drones has raised concerns over the ability of traditional air-space monitoring technologies to accurately characterise such vehicles. Here, we present a CNN using a decision tree and ensemble structure to fully characterise drones in flight. Our system determines the drone type, orientation (in terms of pitch, roll, and yaw), and performs segmentation to classify different body parts (engines, body, and camera). We also provide a computer model for the rapid generation of large quantities of accurately labelled photo-realistic training data and demonstrate that this data is of sufficient fidelity to allow the system to accurately characterise real drones in flight. Our network will provide a valuable tool in the image processing chain where it may build upon existing drone detection technologies to provide complete drone characterisation over wide areas.
Real-time, low-cost multi-person 3D pose estimation
Oct 11, 2021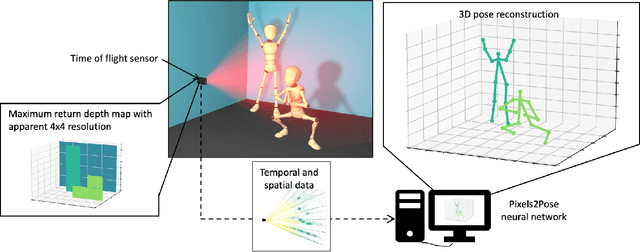
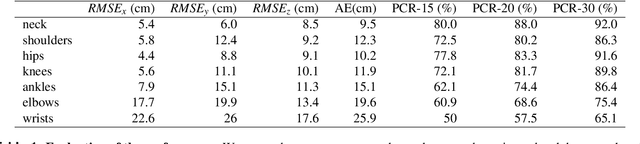
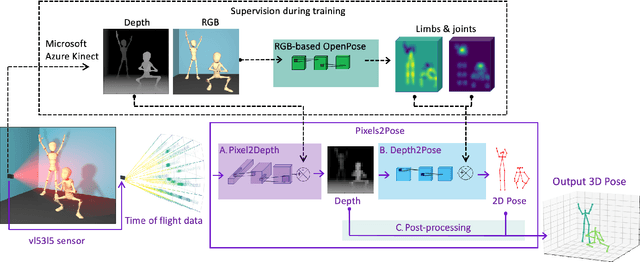
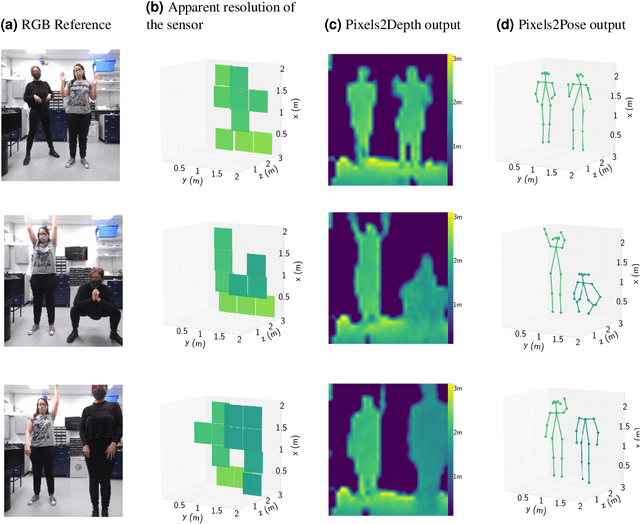
The process of tracking human anatomy in computer vision is referred to pose estimation, and it is used in fields ranging from gaming to surveillance. Three-dimensional pose estimation traditionally requires advanced equipment, such as multiple linked intensity cameras or high-resolution time-of-flight cameras to produce depth images. However, there are applications, e.g.~consumer electronics, where significant constraints are placed on the size, power consumption, weight and cost of the usable technology. Here, we demonstrate that computational imaging methods can achieve accurate pose estimation and overcome the apparent limitations of time-of-flight sensors designed for much simpler tasks. The sensor we use is already widely integrated in consumer-grade mobile devices, and despite its low spatial resolution, only 4$\times$4 pixels, our proposed Pixels2Pose system transforms its data into accurate depth maps and 3D pose data of multiple people up to a distance of 3 m from the sensor. We are able to generate depth maps at a resolution of 32$\times$32 and 3D localization of a body parts with an error of only $\approx$10 cm at a frame rate of 7 fps. This work opens up promising real-life applications in scenarios that were previously restricted by the advanced hardware requirements and cost of time-of-flight technology.
High-speed object detection with a single-photon time-of-flight image sensor
Jul 28, 2021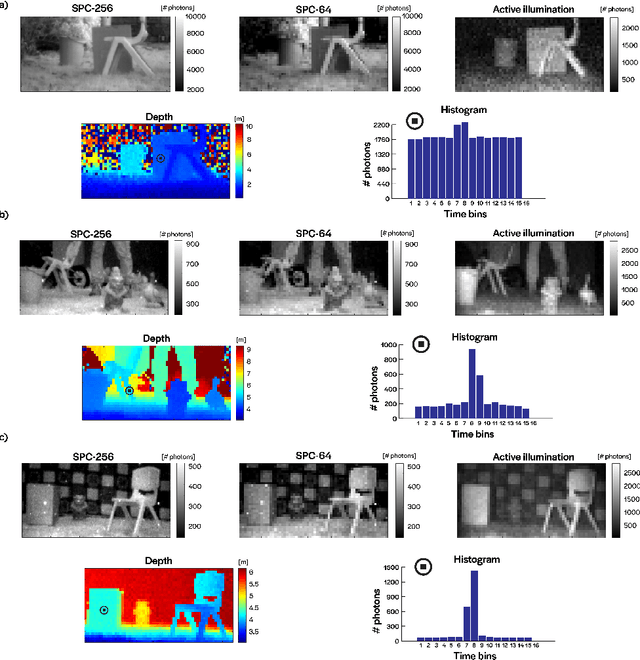



3D time-of-flight (ToF) imaging is used in a variety of applications such as augmented reality (AR), computer interfaces, robotics and autonomous systems. Single-photon avalanche diodes (SPADs) are one of the enabling technologies providing accurate depth data even over long ranges. By developing SPADs in array format with integrated processing combined with pulsed, flood-type illumination, high-speed 3D capture is possible. However, array sizes tend to be relatively small, limiting the lateral resolution of the resulting depth maps, and, consequently, the information that can be extracted from the image for applications such as object detection. In this paper, we demonstrate that these limitations can be overcome through the use of convolutional neural networks (CNNs) for high-performance object detection. We present outdoor results from a portable SPAD camera system that outputs 16-bin photon timing histograms with 64x32 spatial resolution. The results, obtained with exposure times down to 2 ms (equivalent to 500 FPS) and in signal-to-background (SBR) ratios as low as 0.05, point to the advantages of providing the CNN with full histogram data rather than point clouds alone. Alternatively, a combination of point cloud and active intensity data may be used as input, for a similar level of performance. In either case, the GPU-accelerated processing time is less than 1 ms per frame, leading to an overall latency (image acquisition plus processing) in the millisecond range, making the results relevant for safety-critical computer vision applications which would benefit from faster than human reaction times.
Robust super-resolution depth imaging via a multi-feature fusion deep network
Nov 20, 2020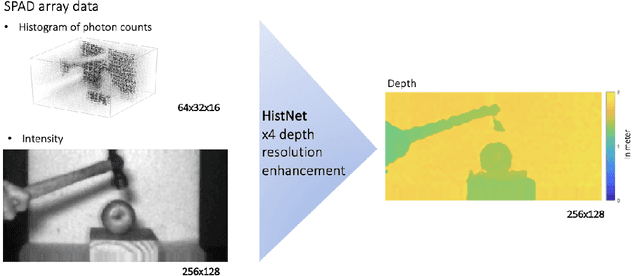
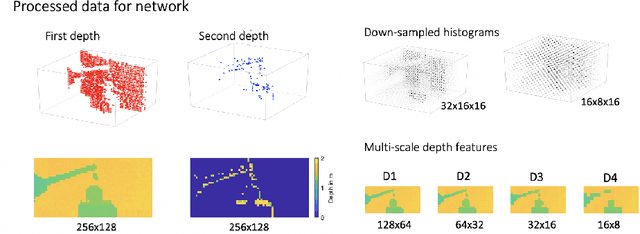
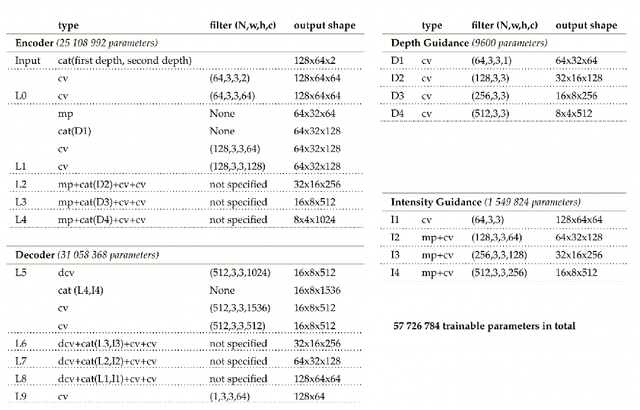
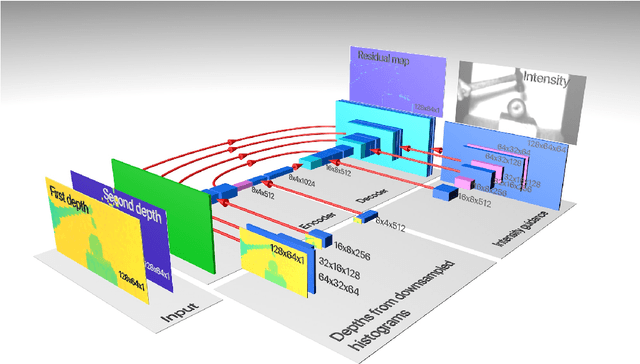
Three-dimensional imaging plays an important role in imaging applications where it is necessary to record depth. The number of applications that use depth imaging is increasing rapidly, and examples include self-driving autonomous vehicles and auto-focus assist on smartphone cameras. Light detection and ranging (LIDAR) via single-photon sensitive detector (SPAD) arrays is an emerging technology that enables the acquisition of depth images at high frame rates. However, the spatial resolution of this technology is typically low in comparison to the intensity images recorded by conventional cameras. To increase the native resolution of depth images from a SPAD camera, we develop a deep network built specifically to take advantage of the multiple features that can be extracted from a camera's histogram data. The network is designed for a SPAD camera operating in a dual-mode such that it captures alternate low resolution depth and high resolution intensity images at high frame rates, thus the system does not require any additional sensor to provide intensity images. The network then uses the intensity images and multiple features extracted from downsampled histograms to guide the upsampling of the depth. Our network provides significant image resolution enhancement and image denoising across a wide range of signal-to-noise ratios and photon levels. We apply the network to a range of 3D data, demonstrating denoising and a four-fold resolution enhancement of depth.
Non-line-of-sight tracking of people at long range
Mar 02, 2017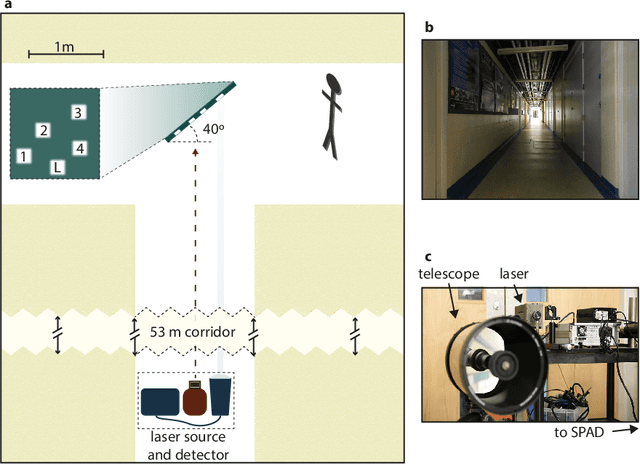
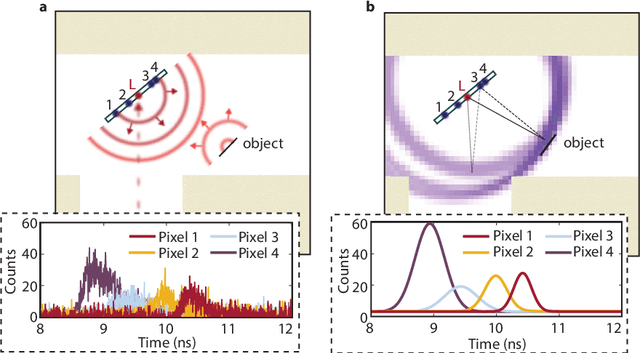
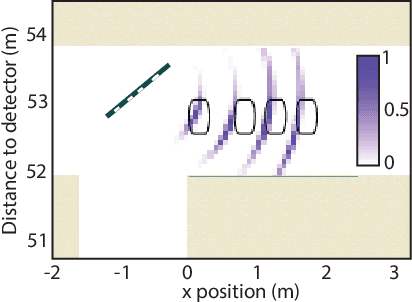
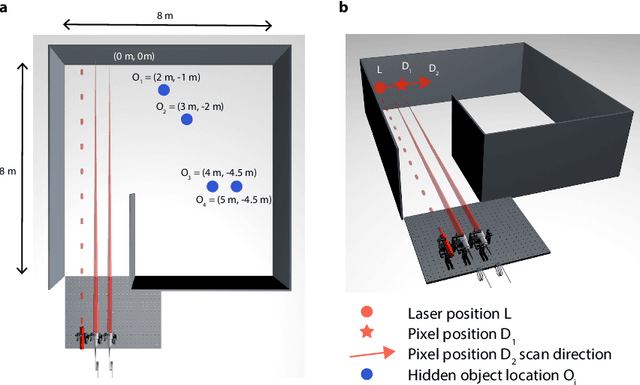
A remote-sensing system that can determine the position of hidden objects has applications in many critical real-life scenarios, such as search and rescue missions and safe autonomous driving. Previous work has shown the ability to range and image objects hidden from the direct line of sight, employing advanced optical imaging technologies aimed at small objects at short range. In this work we demonstrate a long-range tracking system based on single laser illumination and single-pixel single-photon detection. This enables us to track one or more people hidden from view at a stand-off distance of over 50~m. These results pave the way towards next generation LiDAR systems that will reconstruct not only the direct-view scene but also the main elements hidden behind walls or corners.