 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Attention-Driven Bayesian Deep Unrolling for Dual-Peak Single-Photon Lidar Imaging
Apr 03, 2025



Single-photon Lidar imaging offers a significant advantage in 3D imaging due to its high resolution and long-range capabilities, however it is challenging to apply in noisy environments with multiple targets per pixel. To tackle these challenges, several methods have been proposed. Statistical methods demonstrate interpretability on the inferred parameters, but they are often limited in their ability to handle complex scenes. Deep learning-based methods have shown superior performance in terms of accuracy and robustness, but they lack interpretability or they are limited to a single-peak per pixel. In this paper, we propose a deep unrolling algorithm for dual-peak single-photon Lidar imaging. We introduce a hierarchical Bayesian model for multiple targets and propose a neural network that unrolls the underlying statistical method. To support multiple targets, we adopt a dual depth maps representation and exploit geometric deep learning to extract features from the point cloud. The proposed method takes advantages of statistical methods and learning-based methods in terms of accuracy and quantifying uncertainty. The experimental results on synthetic and real data demonstrate the competitive performance when compared to existing methods, while also providing uncertainty information.
DTU-Net: A Multi-Scale Dilated Transformer Network for Nonlinear Hyperspectral Unmixing
Mar 06, 2025



Transformers have shown significant success in hyperspectral unmixing (HU). However, challenges remain. While multi-scale and long-range spatial correlations are essential in unmixing tasks, current Transformer-based unmixing networks, built on Vision Transformer (ViT) or Swin-Transformer, struggle to capture them effectively. Additionally, current Transformer-based unmixing networks rely on the linear mixing model, which lacks the flexibility to accommodate scenarios where nonlinear effects are significant. To address these limitations, we propose a multi-scale Dilated Transformer-based unmixing network for nonlinear HU (DTU-Net). The encoder employs two branches. The first one performs multi-scale spatial feature extraction using Multi-Scale Dilated Attention (MSDA) in the Dilated Transformer, which varies dilation rates across attention heads to capture long-range and multi-scale spatial correlations. The second one performs spectral feature extraction utilizing 3D-CNNs with channel attention. The outputs from both branches are then fused to integrate multi-scale spatial and spectral information, which is subsequently transformed to estimate the abundances. The decoder is designed to accommodate both linear and nonlinear mixing scenarios. Its interpretability is enhanced by explicitly modeling the relationships between endmembers, abundances, and nonlinear coefficients in accordance with the polynomial post-nonlinear mixing model (PPNMM). Experiments on synthetic and real datasets validate the effectiveness of the proposed DTU-Net compared to PPNMM-derived methods and several advanced unmixing networks.
Bayesian Multifractal Image Segmentation
Jan 15, 2025



Multifractal analysis (MFA) provides a framework for the global characterization of image textures by describing the spatial fluctuations of their local regularity based on the multifractal spectrum. Several works have shown the interest of using MFA for the description of homogeneous textures in images. Nevertheless, natural images can be composed of several textures and, in turn, multifractal properties associated with those textures. This paper introduces a Bayesian multifractal segmentation method to model and segment multifractal textures by jointly estimating the multifractal parameters and labels on images. For this, a computationally and statistically efficient multifractal parameter estimation model for wavelet leaders is firstly developed, defining different multifractality parameters to different regions of an image. Then, a multiscale Potts Markov random field is introduced as a prior to model the inherent spatial and scale correlations between the labels of the wavelet leaders. A Gibbs sampling methodology is employed to draw samples from the posterior distribution of the parameters. Numerical experiments are conducted on synthetic multifractal images to evaluate the performance of the proposed segmentation approach. The proposed method achieves superior performance compared to traditional unsupervised segmentation techniques as well as modern deep learning-based approaches, showing its effectiveness for multifractal image segmentation.
A Plug-and-Play Algorithm for 3D Video Super-Resolution of Single-Photon LiDAR data
Dec 12, 2024



Single-photon avalanche diodes (SPADs) are advanced sensors capable of detecting individual photons and recording their arrival times with picosecond resolution using time-correlated Single-Photon Counting detection techniques. They are used in various applications, such as LiDAR, and can capture high-speed sequences of binary single-photon images, offering great potential for reconstructing 3D environments with high motion dynamics. To complement single-photon data, they are often paired with conventional passive cameras, which capture high-resolution (HR) intensity images at a lower frame rate. However, 3D reconstruction from SPAD data faces challenges. Aggregating multiple binary measurements improves precision and reduces noise but can cause motion blur in dynamic scenes. Additionally, SPAD arrays often have lower resolution than passive cameras. To address these issues, we propose a novel computational imaging algorithm to improve the 3D reconstruction of moving scenes from SPAD data by addressing the motion blur and increasing the native spatial resolution. We adopt a plug-and-play approach within an optimization scheme alternating between guided video super-resolution of the 3D scene, and precise image realignment using optical flow. Experiments on synthetic data show significantly improved image resolutions across various signal-to-noise ratios and photon levels. We validate our method using real-world SPAD measurements on three practical situations with dynamic objects. First on fast-moving scenes in laboratory conditions at short range; second very low resolution imaging of people with a consumer-grade SPAD sensor from STMicroelectronics; and finally, HR imaging of people walking outdoors in daylight at a range of 325 meters under eye-safe illumination conditions using a short-wave infrared SPAD camera. These results demonstrate the robustness and versatility of our approach.
Bayesian Based Unrolling for Reconstruction and Super-resolution of Single-Photon Lidar Systems
Jul 24, 2023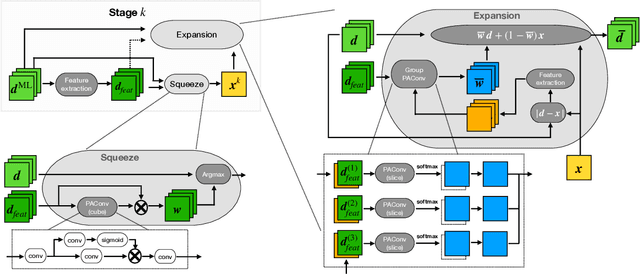
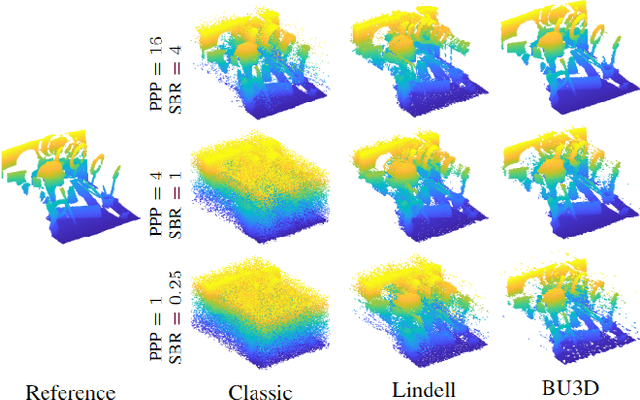
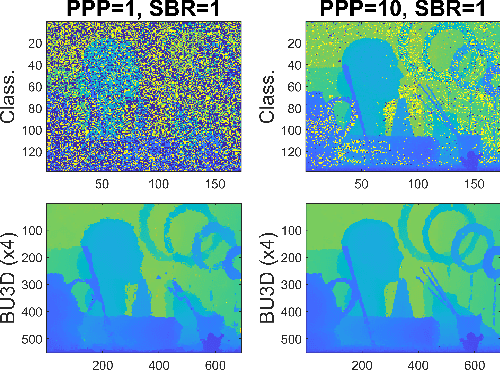
Deploying 3D single-photon Lidar imaging in real world applications faces several challenges due to imaging in high noise environments and with sensors having limited resolution. This paper presents a deep learning algorithm based on unrolling a Bayesian model for the reconstruction and super-resolution of 3D single-photon Lidar. The resulting algorithm benefits from the advantages of both statistical and learning based frameworks, providing best estimates with improved network interpretability. Compared to existing learning-based solutions, the proposed architecture requires a reduced number of trainable parameters, is more robust to noise and mismodelling of the system impulse response function, and provides richer information about the estimates including uncertainty measures. Results on synthetic and real data show competitive results regarding the quality of the inference and computational complexity when compared to state-of-the-art algorithms. This short paper is based on contributions published in [1] and [2].
3D Target Detection and Spectral Classification for Single-photon LiDAR Data
Feb 20, 2023



3D single-photon LiDAR imaging has an important role in many applications. However, full deployment of this modality will require the analysis of low signal to noise ratio target returns and a very high volume of data. This is particularly evident when imaging through obscurants or in high ambient background light conditions. This paper proposes a multiscale approach for 3D surface detection from the photon timing histogram to permit a significant reduction in data volume. The resulting surfaces are background-free and can be used to infer depth and reflectivity information about the target. We demonstrate this by proposing a hierarchical Bayesian model for 3D reconstruction and spectral classification of multispectral single-photon LiDAR data. The reconstruction method promotes spatial correlation between point-cloud estimates and uses a coordinate gradient descent algorithm for parameter estimation. Results on simulated and real data show the benefits of the proposed target detection and reconstruction approaches when compared to state-of-the-art processing algorithms
A Bayesian Based Deep Unrolling Algorithm for Single-Photon Lidar Systems
Jan 26, 2022
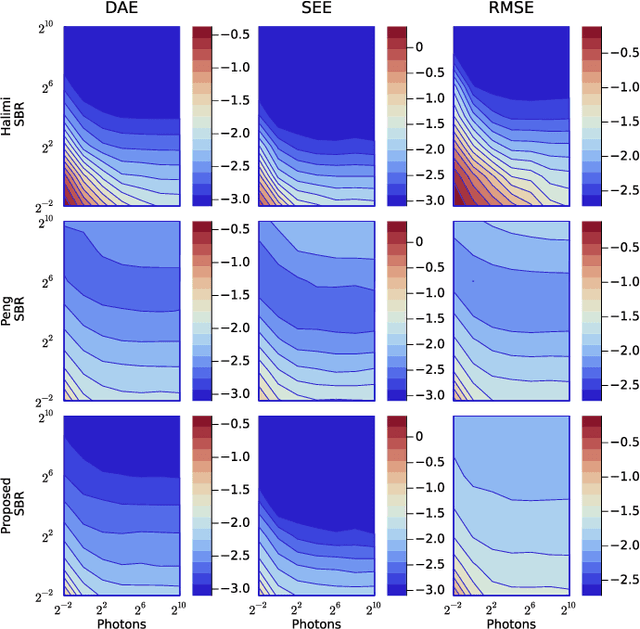
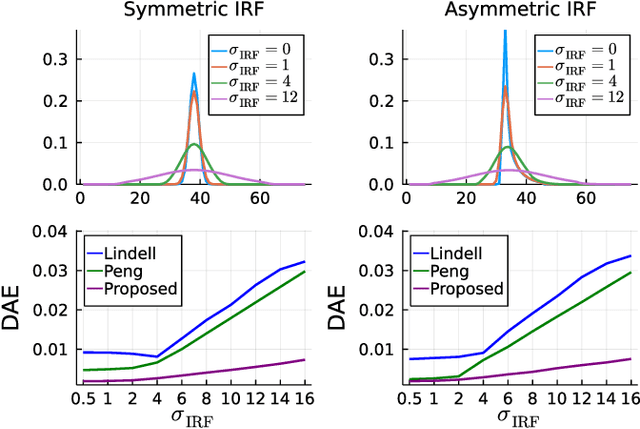
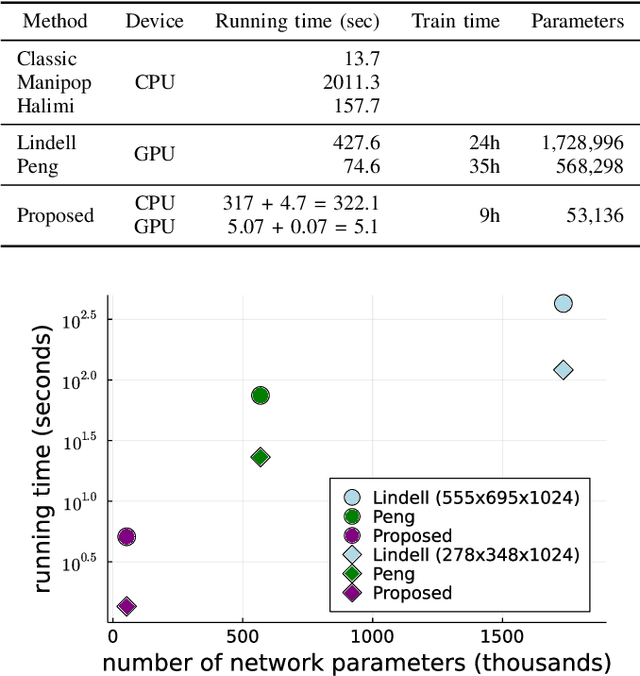
Deploying 3D single-photon Lidar imaging in real world applications faces multiple challenges including imaging in high noise environments. Several algorithms have been proposed to address these issues based on statistical or learning-based frameworks. Statistical methods provide rich information about the inferred parameters but are limited by the assumed model correlation structures, while deep learning methods show state-of-the-art performance but limited inference guarantees, preventing their extended use in critical applications. This paper unrolls a statistical Bayesian algorithm into a new deep learning architecture for robust image reconstruction from single-photon Lidar data, i.e., the algorithm's iterative steps are converted into neural network layers. The resulting algorithm benefits from the advantages of both statistical and learning based frameworks, providing best estimates with improved network interpretability. Compared to existing learning-based solutions, the proposed architecture requires a reduced number of trainable parameters, is more robust to noise and mismodelling effects, and provides richer information about the estimates including uncertainty measures. Results on synthetic and real data show competitive results regarding the quality of the inference and computational complexity when compared to state-of-the-art algorithms.
Real-time, low-cost multi-person 3D pose estimation
Oct 11, 2021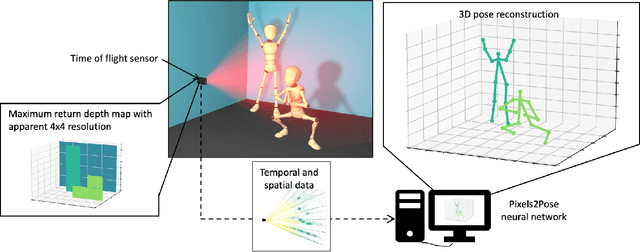
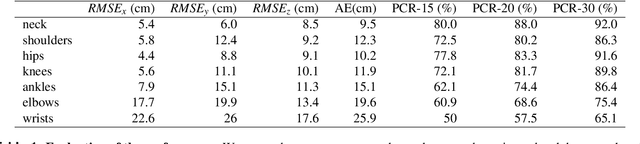
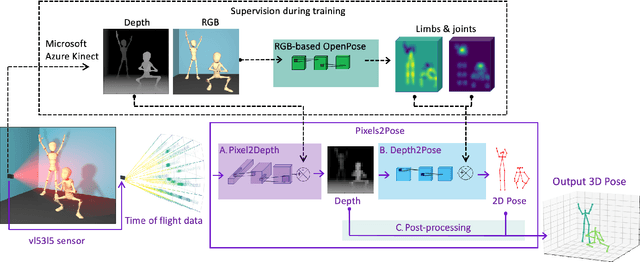
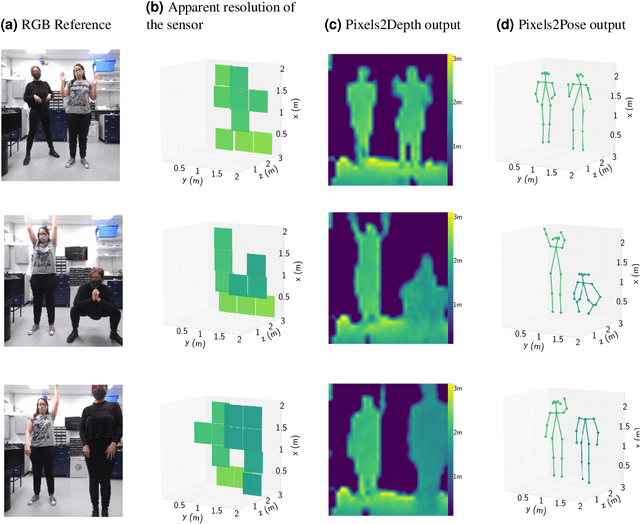
The process of tracking human anatomy in computer vision is referred to pose estimation, and it is used in fields ranging from gaming to surveillance. Three-dimensional pose estimation traditionally requires advanced equipment, such as multiple linked intensity cameras or high-resolution time-of-flight cameras to produce depth images. However, there are applications, e.g.~consumer electronics, where significant constraints are placed on the size, power consumption, weight and cost of the usable technology. Here, we demonstrate that computational imaging methods can achieve accurate pose estimation and overcome the apparent limitations of time-of-flight sensors designed for much simpler tasks. The sensor we use is already widely integrated in consumer-grade mobile devices, and despite its low spatial resolution, only 4$\times$4 pixels, our proposed Pixels2Pose system transforms its data into accurate depth maps and 3D pose data of multiple people up to a distance of 3 m from the sensor. We are able to generate depth maps at a resolution of 32$\times$32 and 3D localization of a body parts with an error of only $\approx$10 cm at a frame rate of 7 fps. This work opens up promising real-life applications in scenarios that were previously restricted by the advanced hardware requirements and cost of time-of-flight technology.
Fast Task-Based Adaptive Sampling for 3D Single-Photon Multispectral Lidar Data
Sep 03, 2021


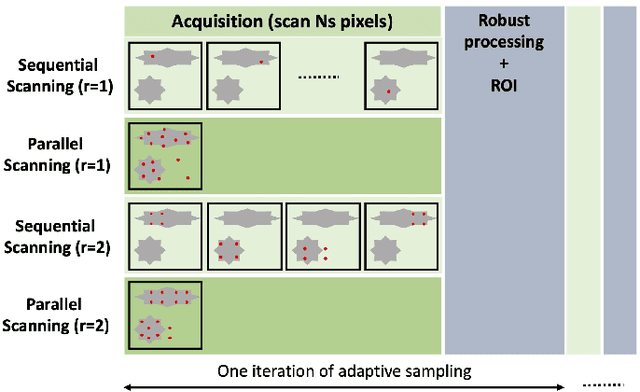
3D single-photon LiDAR imaging plays an important role in numerous applications. However, long acquisition times and significant data volumes present a challenge to LiDAR imaging. This paper proposes a task-optimized adaptive sampling framework that enables fast acquisition and processing of high-dimensional single-photon LiDAR data. Given a task of interest, the iterative sampling strategy targets the most informative regions of a scene which are defined as those minimizing parameter uncertainties. The task is performed by considering a Bayesian model that is carefully built to allow fast per-pixel computations while delivering parameter estimates with quantified uncertainties. The framework is demonstrated on multispectral 3D single-photon LiDAR imaging when considering object classification and/or target detection as tasks. It is also analysed for both sequential and parallel scanning modes for different detector array sizes. Results on simulated and real data show the benefit of the proposed optimized sampling strategy when compared to fixed sampling strategies.
High-speed object detection with a single-photon time-of-flight image sensor
Jul 28, 2021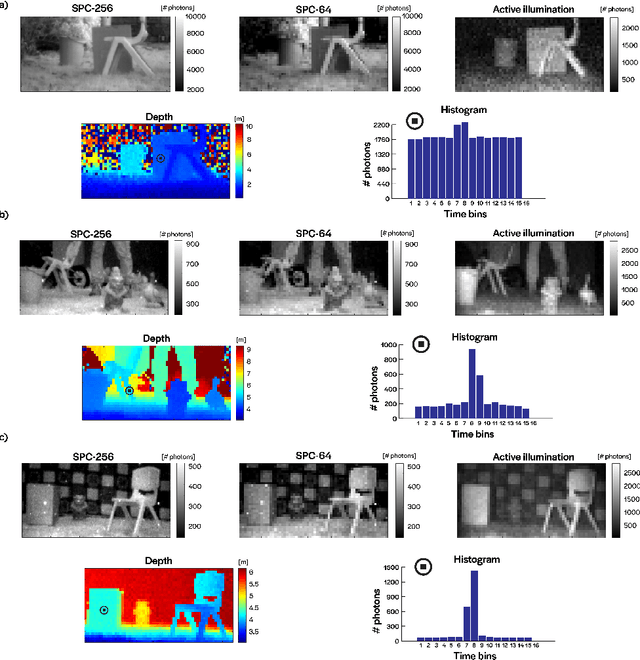



3D time-of-flight (ToF) imaging is used in a variety of applications such as augmented reality (AR), computer interfaces, robotics and autonomous systems. Single-photon avalanche diodes (SPADs) are one of the enabling technologies providing accurate depth data even over long ranges. By developing SPADs in array format with integrated processing combined with pulsed, flood-type illumination, high-speed 3D capture is possible. However, array sizes tend to be relatively small, limiting the lateral resolution of the resulting depth maps, and, consequently, the information that can be extracted from the image for applications such as object detection. In this paper, we demonstrate that these limitations can be overcome through the use of convolutional neural networks (CNNs) for high-performance object detection. We present outdoor results from a portable SPAD camera system that outputs 16-bin photon timing histograms with 64x32 spatial resolution. The results, obtained with exposure times down to 2 ms (equivalent to 500 FPS) and in signal-to-background (SBR) ratios as low as 0.05, point to the advantages of providing the CNN with full histogram data rather than point clouds alone. Alternatively, a combination of point cloud and active intensity data may be used as input, for a similar level of performance. In either case, the GPU-accelerated processing time is less than 1 ms per frame, leading to an overall latency (image acquisition plus processing) in the millisecond range, making the results relevant for safety-critical computer vision applications which would benefit from faster than human reaction times.