 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDTU-Net: A Multi-Scale Dilated Transformer Network for Nonlinear Hyperspectral Unmixing
Mar 06, 2025



Transformers have shown significant success in hyperspectral unmixing (HU). However, challenges remain. While multi-scale and long-range spatial correlations are essential in unmixing tasks, current Transformer-based unmixing networks, built on Vision Transformer (ViT) or Swin-Transformer, struggle to capture them effectively. Additionally, current Transformer-based unmixing networks rely on the linear mixing model, which lacks the flexibility to accommodate scenarios where nonlinear effects are significant. To address these limitations, we propose a multi-scale Dilated Transformer-based unmixing network for nonlinear HU (DTU-Net). The encoder employs two branches. The first one performs multi-scale spatial feature extraction using Multi-Scale Dilated Attention (MSDA) in the Dilated Transformer, which varies dilation rates across attention heads to capture long-range and multi-scale spatial correlations. The second one performs spectral feature extraction utilizing 3D-CNNs with channel attention. The outputs from both branches are then fused to integrate multi-scale spatial and spectral information, which is subsequently transformed to estimate the abundances. The decoder is designed to accommodate both linear and nonlinear mixing scenarios. Its interpretability is enhanced by explicitly modeling the relationships between endmembers, abundances, and nonlinear coefficients in accordance with the polynomial post-nonlinear mixing model (PPNMM). Experiments on synthetic and real datasets validate the effectiveness of the proposed DTU-Net compared to PPNMM-derived methods and several advanced unmixing networks.
MLLM-SUL: Multimodal Large Language Model for Semantic Scene Understanding and Localization in Traffic Scenarios
Dec 27, 2024
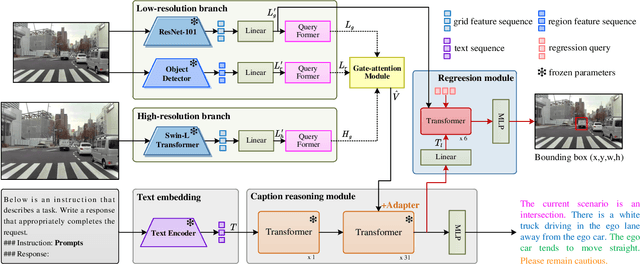
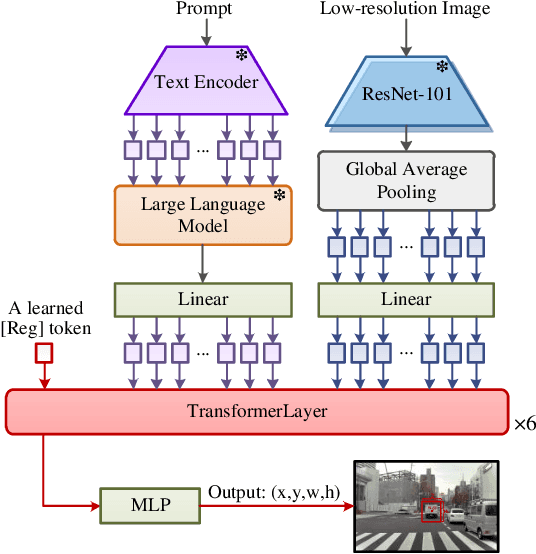

Multimodal large language models (MLLMs) have shown satisfactory effects in many autonomous driving tasks. In this paper, MLLMs are utilized to solve joint semantic scene understanding and risk localization tasks, while only relying on front-view images. In the proposed MLLM-SUL framework, a dual-branch visual encoder is first designed to extract features from two resolutions, and rich visual information is conducive to the language model describing risk objects of different sizes accurately. Then for the language generation, LLaMA model is fine-tuned to predict scene descriptions, containing the type of driving scenario, actions of risk objects, and driving intentions and suggestions of ego-vehicle. Ultimately, a transformer-based network incorporating a regression token is trained to locate the risk objects. Extensive experiments on the existing DRAMA-ROLISP dataset and the extended DRAMA-SRIS dataset demonstrate that our method is efficient, surpassing many state-of-the-art image-based and video-based methods. Specifically, our method achieves 80.1% BLEU-1 score and 298.5% CIDEr score in the scene understanding task, and 59.6% accuracy in the localization task. Codes and datasets are available at https://github.com/fjq-tongji/MLLM-SUL.