 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Clinician-Friendly Platform for Ophthalmic Image Analysis Without Technical Barriers
Apr 22, 2025Artificial intelligence (AI) shows remarkable potential in medical imaging diagnostics, but current models typically require retraining when deployed across different clinical centers, limiting their widespread adoption. We introduce GlobeReady, a clinician-friendly AI platform that enables ocular disease diagnosis without retraining/fine-tuning or technical expertise. GlobeReady achieves high accuracy across imaging modalities: 93.9-98.5% for an 11-category fundus photo dataset and 87.2-92.7% for a 15-category OCT dataset. Through training-free local feature augmentation, it addresses domain shifts across centers and populations, reaching an average accuracy of 88.9% across five centers in China, 86.3% in Vietnam, and 90.2% in the UK. The built-in confidence-quantifiable diagnostic approach further boosted accuracy to 94.9-99.4% (fundus) and 88.2-96.2% (OCT), while identifying out-of-distribution cases at 86.3% (49 CFP categories) and 90.6% (13 OCT categories). Clinicians from multiple countries rated GlobeReady highly (average 4.6 out of 5) for its usability and clinical relevance. These results demonstrate GlobeReady's robust, scalable diagnostic capability and potential to support ophthalmic care without technical barriers.
MLLM-SUL: Multimodal Large Language Model for Semantic Scene Understanding and Localization in Traffic Scenarios
Dec 27, 2024
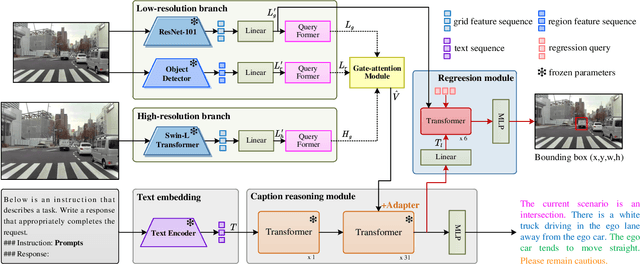
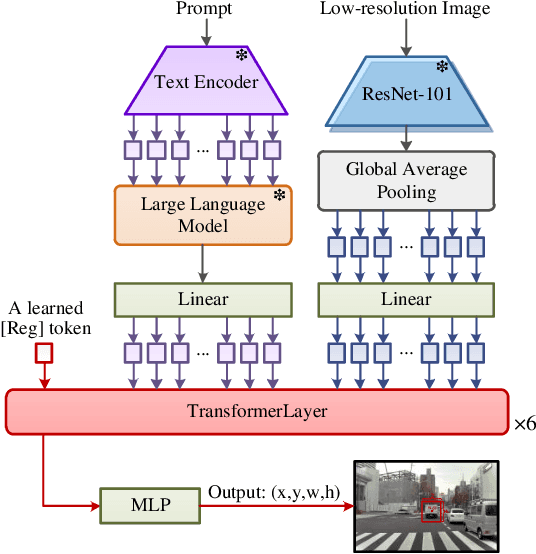

Multimodal large language models (MLLMs) have shown satisfactory effects in many autonomous driving tasks. In this paper, MLLMs are utilized to solve joint semantic scene understanding and risk localization tasks, while only relying on front-view images. In the proposed MLLM-SUL framework, a dual-branch visual encoder is first designed to extract features from two resolutions, and rich visual information is conducive to the language model describing risk objects of different sizes accurately. Then for the language generation, LLaMA model is fine-tuned to predict scene descriptions, containing the type of driving scenario, actions of risk objects, and driving intentions and suggestions of ego-vehicle. Ultimately, a transformer-based network incorporating a regression token is trained to locate the risk objects. Extensive experiments on the existing DRAMA-ROLISP dataset and the extended DRAMA-SRIS dataset demonstrate that our method is efficient, surpassing many state-of-the-art image-based and video-based methods. Specifically, our method achieves 80.1% BLEU-1 score and 298.5% CIDEr score in the scene understanding task, and 59.6% accuracy in the localization task. Codes and datasets are available at https://github.com/fjq-tongji/MLLM-SUL.
Hallucination Elimination and Semantic Enhancement Framework for Vision-Language Models in Traffic Scenarios
Dec 10, 2024



Large vision-language models (LVLMs) have demonstrated remarkable capabilities in multimodal understanding and generation tasks. However, these models occasionally generate hallucinatory texts, resulting in descriptions that seem reasonable but do not correspond to the image. This phenomenon can lead to wrong driving decisions of the autonomous driving system. To address this challenge, this paper proposes HCOENet, a plug-and-play chain-of-thought correction method designed to eliminate object hallucinations and generate enhanced descriptions for critical objects overlooked in the initial response. Specifically, HCOENet employs a cross-checking mechanism to filter entities and directly extracts critical objects from the given image, enriching the descriptive text. Experimental results on the POPE benchmark demonstrate that HCOENet improves the F1-score of the Mini-InternVL-4B and mPLUG-Owl3 models by 12.58% and 4.28%, respectively. Additionally, qualitative results using images collected in open campus scene further highlight the practical applicability of the proposed method. Compared with the GPT-4o model, HCOENet achieves comparable descriptive performance while significantly reducing costs. Finally, two novel semantic understanding datasets, CODA_desc and nuScenes_desc, are created for traffic scenarios to support future research. The codes and datasets are publicly available at https://github.com/fjq-tongji/HCOENet.
Learning Attentional Mixture of LoRAs for Language Model Continual Learning
Sep 29, 2024Fine-tuning large language models (LLMs) with Low-Rank adaption (LoRA) is widely acknowledged as an effective approach for continual learning for new tasks. However, it often suffers from catastrophic forgetting when dealing with multiple tasks sequentially. To this end, we propose Attentional Mixture of LoRAs (AM-LoRA), a continual learning approach tailored for LLMs. Specifically, AM-LoRA learns a sequence of LoRAs for a series of tasks to continually learn knowledge from different tasks. The key of our approach is that we devise an attention mechanism as a knowledge mixture module to adaptively integrate information from each LoRA. With the attention mechanism, AM-LoRA can efficiently leverage the distinctive contributions of each LoRA, while mitigating the risk of mutually negative interactions among them that may lead to catastrophic forgetting. Moreover, we further introduce $L1$ norm in the learning process to make the attention vector more sparse. The sparse constraints can enable the model to lean towards selecting a few highly relevant LoRAs, rather than aggregating and weighting all LoRAs collectively, which can further reduce the impact stemming from mutual interference. Experimental results on continual learning benchmarks indicate the superiority of our proposed method.
Shadow Datasets, New challenging datasets for Causal Representation Learning
Aug 11, 2023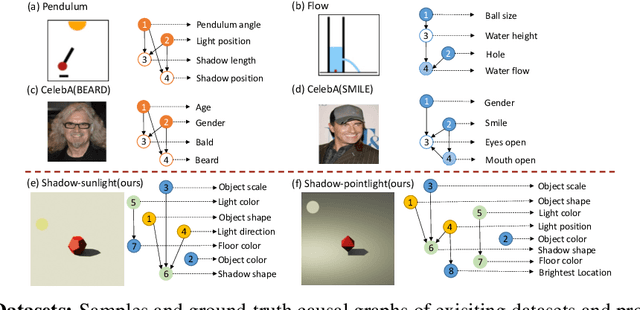
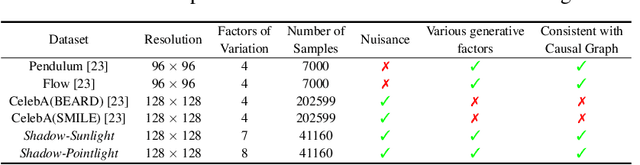

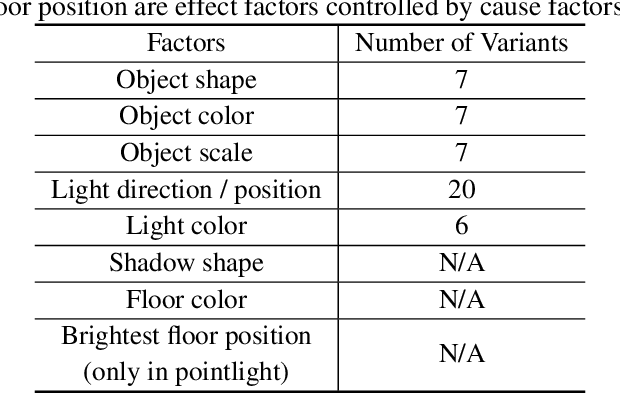
Discovering causal relations among semantic factors is an emergent topic in representation learning. Most causal representation learning (CRL) methods are fully supervised, which is impractical due to costly labeling. To resolve this restriction, weakly supervised CRL methods were introduced. To evaluate CRL performance, four existing datasets, Pendulum, Flow, CelebA(BEARD) and CelebA(SMILE), are utilized. However, existing CRL datasets are limited to simple graphs with few generative factors. Thus we propose two new datasets with a larger number of diverse generative factors and more sophisticated causal graphs. In addition, current real datasets, CelebA(BEARD) and CelebA(SMILE), the originally proposed causal graphs are not aligned with the dataset distributions. Thus, we propose modifications to them.
Patch Network for medical image Segmentation
Feb 23, 2023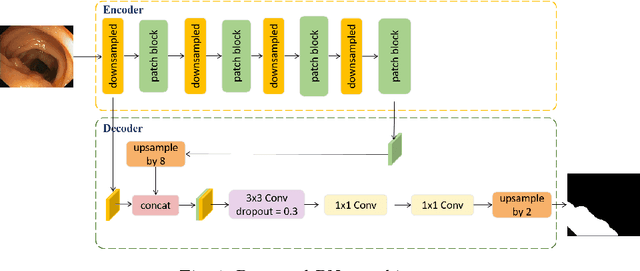



Accurate and fast segmentation of medical images is clinically essential, yet current research methods include convolutional neural networks with fast inference speed but difficulty in learning image contextual features, and transformer with good performance but high hardware requirements. In this paper, we present a Patch Network (PNet) that incorporates the Swin Transformer notion into a convolutional neural network, allowing it to gather richer contextual information while achieving the balance of speed and accuracy. We test our PNet on Polyp(CVC-ClinicDB and ETIS- LaribPolypDB), Skin(ISIC-2018 Skin lesion segmentation challenge dataset) segmentation datasets. Our PNet achieves SOTA performance in both speed and accuracy.