 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSABAF: Removing Strong Attribute Bias from Neural Networks with Adversarial Filtering
Nov 16, 2023



Ensuring a neural network is not relying on protected attributes (e.g., race, sex, age) for prediction is crucial in advancing fair and trustworthy AI. While several promising methods for removing attribute bias in neural networks have been proposed, their limitations remain under-explored. To that end, in this work, we mathematically and empirically reveal the limitation of existing attribute bias removal methods in presence of strong bias and propose a new method that can mitigate this limitation. Specifically, we first derive a general non-vacuous information-theoretical upper bound on the performance of any attribute bias removal method in terms of the bias strength, revealing that they are effective only when the inherent bias in the dataset is relatively weak. Next, we derive a necessary condition for the existence of any method that can remove attribute bias regardless of the bias strength. Inspired by this condition, we then propose a new method using an adversarial objective that directly filters out protected attributes in the input space while maximally preserving all other attributes, without requiring any specific target label. The proposed method achieves state-of-the-art performance in both strong and moderate bias settings. We provide extensive experiments on synthetic, image, and census datasets, to verify the derived theoretical bound and its consequences in practice, and evaluate the effectiveness of the proposed method in removing strong attribute bias.
Information-Theoretic Bounds on The Removal of Attribute-Specific Bias From Neural Networks
Oct 08, 2023



Ensuring a neural network is not relying on protected attributes (e.g., race, sex, age) for predictions is crucial in advancing fair and trustworthy AI. While several promising methods for removing attribute bias in neural networks have been proposed, their limitations remain under-explored. In this work, we mathematically and empirically reveal an important limitation of attribute bias removal methods in presence of strong bias. Specifically, we derive a general non-vacuous information-theoretical upper bound on the performance of any attribute bias removal method in terms of the bias strength. We provide extensive experiments on synthetic, image, and census datasets to verify the theoretical bound and its consequences in practice. Our findings show that existing attribute bias removal methods are effective only when the inherent bias in the dataset is relatively weak, thus cautioning against the use of these methods in smaller datasets where strong attribute bias can occur, and advocating the need for methods that can overcome this limitation.
Shadow Datasets, New challenging datasets for Causal Representation Learning
Aug 11, 2023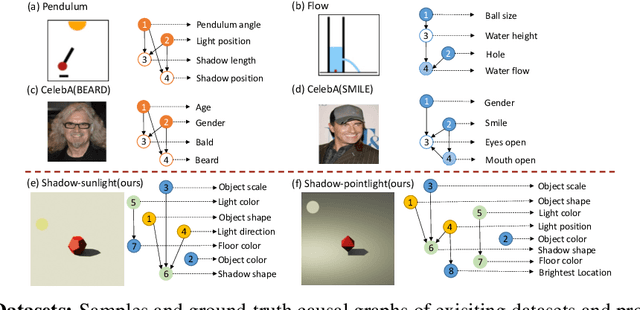
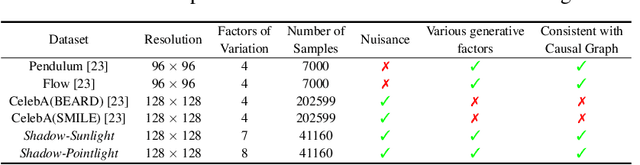

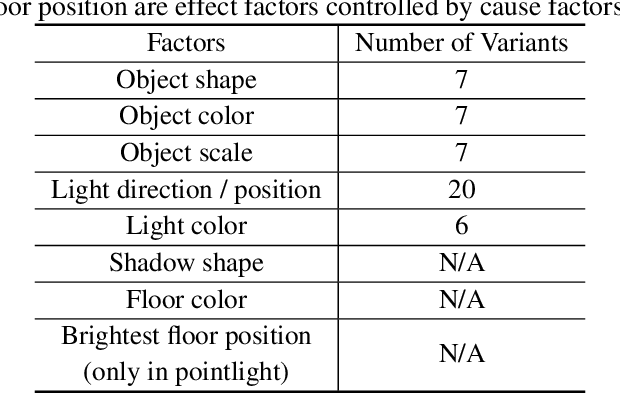
Discovering causal relations among semantic factors is an emergent topic in representation learning. Most causal representation learning (CRL) methods are fully supervised, which is impractical due to costly labeling. To resolve this restriction, weakly supervised CRL methods were introduced. To evaluate CRL performance, four existing datasets, Pendulum, Flow, CelebA(BEARD) and CelebA(SMILE), are utilized. However, existing CRL datasets are limited to simple graphs with few generative factors. Thus we propose two new datasets with a larger number of diverse generative factors and more sophisticated causal graphs. In addition, current real datasets, CelebA(BEARD) and CelebA(SMILE), the originally proposed causal graphs are not aligned with the dataset distributions. Thus, we propose modifications to them.
Trojan Model Detection Using Activation Optimization
Jun 08, 2023Due to data's unavailability or large size, and the high computational and human labor costs of training machine learning models, it is a common practice to rely on open source pre-trained models whenever possible. However, this practice is worry some from the security perspective. Pre-trained models can be infected with Trojan attacks, in which the attacker embeds a trigger in the model such that the model's behavior can be controlled by the attacker when the trigger is present in the input. In this paper, we present our preliminary work on a novel method for Trojan model detection. Our method creates a signature for a model based on activation optimization. A classifier is then trained to detect a Trojan model given its signature. Our method achieves state of the art performance on two public datasets.
A Critical View Of Vision-Based Long-Term Dynamics Prediction Under Environment Misalignment
May 12, 2023



Dynamics prediction, which is the problem of predicting future states of scene objects based on current and prior states, is drawing increasing attention as an instance of learning physics. To solve this problem, Region Proposal Convolutional Interaction Network (RPCIN), a vision-based model, was proposed and achieved state-of-the-art performance in long-term prediction. RPCIN only takes raw images and simple object descriptions, such as the bounding box and segmentation mask of each object, as input. However, despite its success, the model's capability can be compromised under conditions of environment misalignment. In this paper, we investigate two challenging conditions for environment misalignment: Cross-Domain and Cross-Context by proposing four datasets that are designed for these challenges: SimB-Border, SimB-Split, BlenB-Border, and BlenB-Split. The datasets cover two domains and two contexts. Using RPCIN as a probe, experiments conducted on the combinations of the proposed datasets reveal potential weaknesses of the vision-based long-term dynamics prediction model. Furthermore, we propose a promising direction to mitigate the Cross-Domain challenge and provide concrete evidence supporting such a direction, which provides dramatic alleviation of the challenge on the proposed datasets.
Explaining Face Presentation Attack Detection Using Natural Language
Nov 08, 2021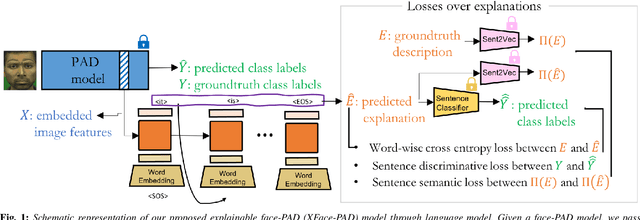
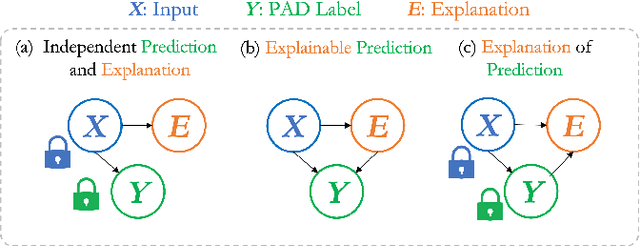
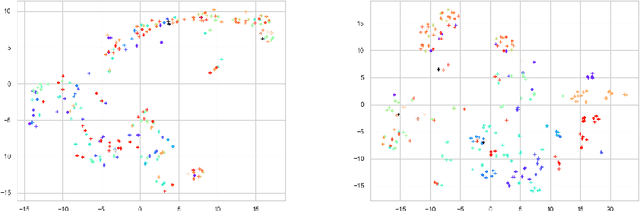
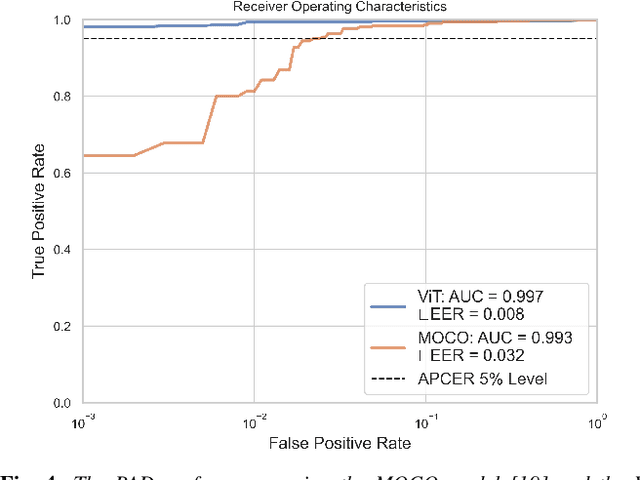
A large number of deep neural network based techniques have been developed to address the challenging problem of face presentation attack detection (PAD). Whereas such techniques' focus has been on improving PAD performance in terms of classification accuracy and robustness against unseen attacks and environmental conditions, there exists little attention on the explainability of PAD predictions. In this paper, we tackle the problem of explaining PAD predictions through natural language. Our approach passes feature representations of a deep layer of the PAD model to a language model to generate text describing the reasoning behind the PAD prediction. Due to the limited amount of annotated data in our study, we apply a light-weight LSTM network as our natural language generation model. We investigate how the quality of the generated explanations is affected by different loss functions, including the commonly used word-wise cross entropy loss, a sentence discriminative loss, and a sentence semantic loss. We perform our experiments using face images from a dataset consisting of 1,105 bona-fide and 924 presentation attack samples. Our quantitative and qualitative results show the effectiveness of our model for generating proper PAD explanations through text as well as the power of the sentence-wise losses. To the best of our knowledge, this is the first introduction of a joint biometrics-NLP task. Our dataset can be obtained through our GitHub page.
Introducing the DOME Activation Functions
Sep 30, 2021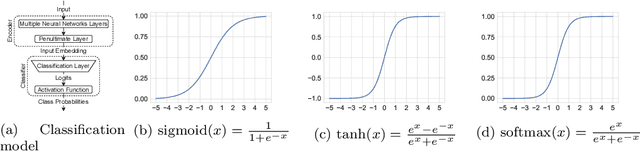
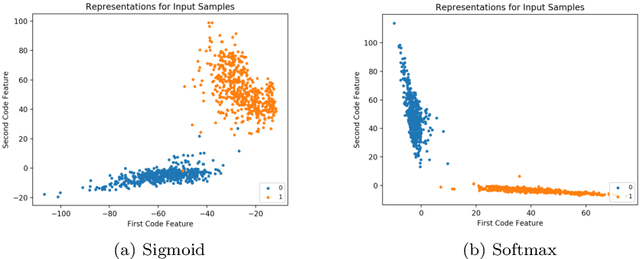
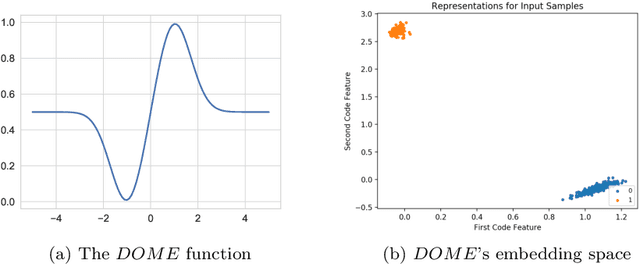
In this paper, we introduce a novel non-linear activation function that spontaneously induces class-compactness and regularization in the embedding space of neural networks. The function is dubbed DOME for Difference Of Mirrored Exponential terms. The basic form of the function can replace the sigmoid or the hyperbolic tangent functions as an output activation function for binary classification problems. The function can also be extended to the case of multi-class classification, and used as an alternative to the standard softmax function. It can also be further generalized to take more flexible shapes suitable for intermediate layers of a network. In this version of the paper, we only introduce the concept. In a subsequent version, experimental evaluation will be added.
MUSCLE: Strengthening Semi-Supervised Learning Via Concurrent Unsupervised Learning Using Mutual Information Maximization
Nov 30, 2020
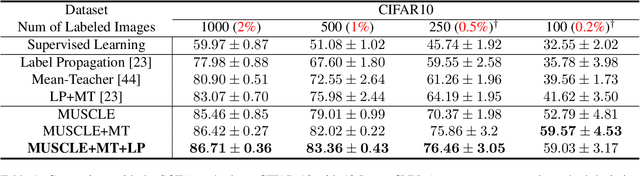


Deep neural networks are powerful, massively parameterized machine learning models that have been shown to perform well in supervised learning tasks. However, very large amounts of labeled data are usually needed to train deep neural networks. Several semi-supervised learning approaches have been proposed to train neural networks using smaller amounts of labeled data with a large amount of unlabeled data. The performance of these semi-supervised methods significantly degrades as the size of labeled data decreases. We introduce Mutual-information-based Unsupervised & Semi-supervised Concurrent LEarning (MUSCLE), a hybrid learning approach that uses mutual information to combine both unsupervised and semi-supervised learning. MUSCLE can be used as a stand-alone training scheme for neural networks, and can also be incorporated into other learning approaches. We show that the proposed hybrid model outperforms state of the art on several standard benchmarks, including CIFAR-10, CIFAR-100, and Mini-Imagenet. Furthermore, the performance gain consistently increases with the reduction in the amount of labeled data, as well as in the presence of bias. We also show that MUSCLE has the potential to boost the classification performance when used in the fine-tuning phase for a model pre-trained only on unlabeled data.
Input Fast-Forwarding for Better Deep Learning
May 23, 2017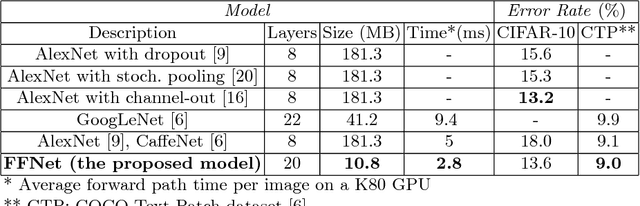
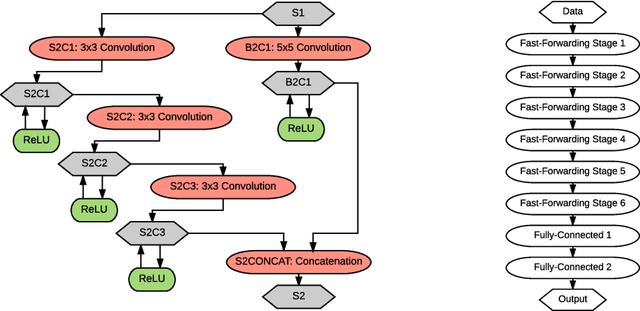

This paper introduces a new architectural framework, known as input fast-forwarding, that can enhance the performance of deep networks. The main idea is to incorporate a parallel path that sends representations of input values forward to deeper network layers. This scheme is substantially different from "deep supervision" in which the loss layer is re-introduced to earlier layers. The parallel path provided by fast-forwarding enhances the training process in two ways. First, it enables the individual layers to combine higher-level information (from the standard processing path) with lower-level information (from the fast-forward path). Second, this new architecture reduces the problem of vanishing gradients substantially because the fast-forwarding path provides a shorter route for gradient backpropagation. In order to evaluate the utility of the proposed technique, a Fast-Forward Network (FFNet), with 20 convolutional layers along with parallel fast-forward paths, has been created and tested. The paper presents empirical results that demonstrate improved learning capacity of FFNet due to fast-forwarding, as compared to GoogLeNet (with deep supervision) and CaffeNet, which are 4x and 18x larger in size, respectively. All of the source code and deep learning models described in this paper will be made available to the entire research community
An Image Dataset of Text Patches in Everyday Scenes
Oct 20, 2016
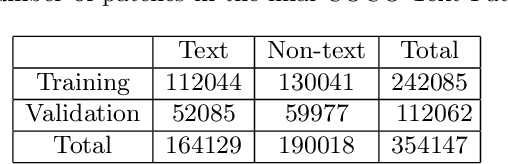

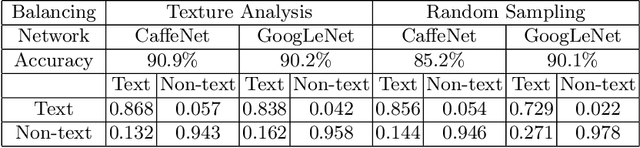
This paper describes a dataset containing small images of text from everyday scenes. The purpose of the dataset is to support the development of new automated systems that can detect and analyze text. Although much research has been devoted to text detection and recognition in scanned documents, relatively little attention has been given to text detection in other types of images, such as photographs that are posted on social-media sites. This new dataset, known as COCO-Text-Patch, contains approximately 354,000 small images that are each labeled as "text" or "non-text". This dataset particularly addresses the problem of text verification, which is an essential stage in the end-to-end text detection and recognition pipeline. In order to evaluate the utility of this dataset, it has been used to train two deep convolution neural networks to distinguish text from non-text. One network is inspired by the GoogLeNet architecture, and the second one is based on CaffeNet. Accuracy levels of 90.2% and 90.9% were obtained using the two networks, respectively. All of the images, source code, and deep-learning trained models described in this paper will be publicly available