 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Face Presentation Attack Detection Using Natural Language
Nov 08, 2021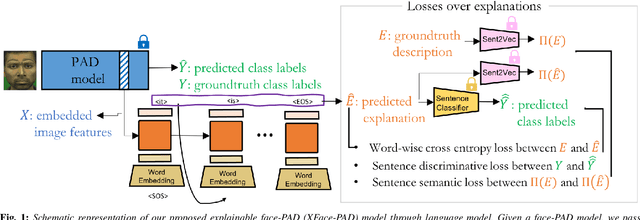
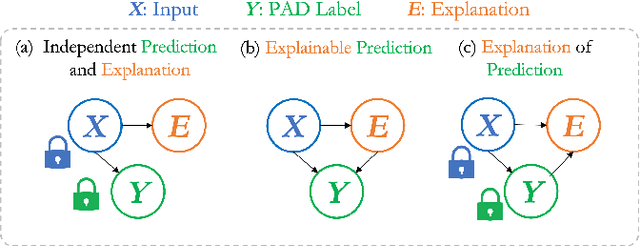
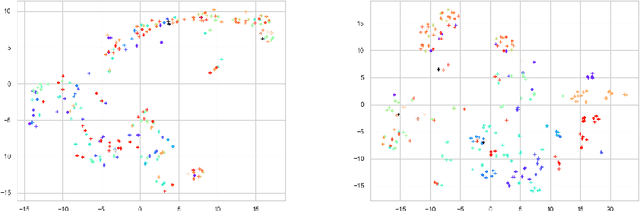
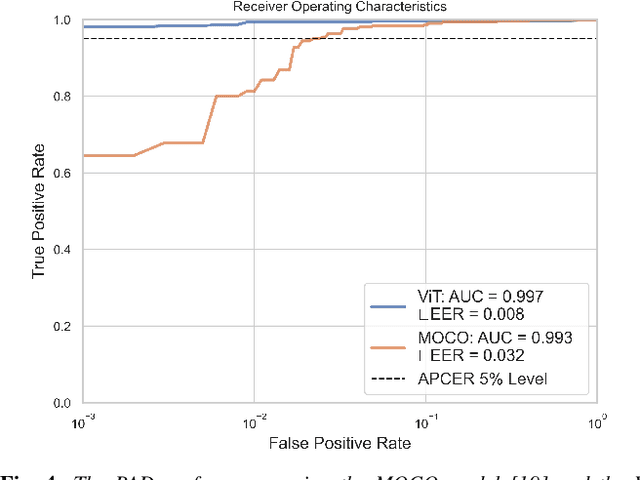
A large number of deep neural network based techniques have been developed to address the challenging problem of face presentation attack detection (PAD). Whereas such techniques' focus has been on improving PAD performance in terms of classification accuracy and robustness against unseen attacks and environmental conditions, there exists little attention on the explainability of PAD predictions. In this paper, we tackle the problem of explaining PAD predictions through natural language. Our approach passes feature representations of a deep layer of the PAD model to a language model to generate text describing the reasoning behind the PAD prediction. Due to the limited amount of annotated data in our study, we apply a light-weight LSTM network as our natural language generation model. We investigate how the quality of the generated explanations is affected by different loss functions, including the commonly used word-wise cross entropy loss, a sentence discriminative loss, and a sentence semantic loss. We perform our experiments using face images from a dataset consisting of 1,105 bona-fide and 924 presentation attack samples. Our quantitative and qualitative results show the effectiveness of our model for generating proper PAD explanations through text as well as the power of the sentence-wise losses. To the best of our knowledge, this is the first introduction of a joint biometrics-NLP task. Our dataset can be obtained through our GitHub page.
CORD19STS: COVID-19 Semantic Textual Similarity Dataset
Jul 05, 2020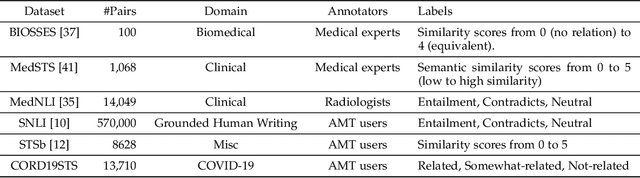


In order to combat the COVID-19 pandemic, society can benefit from various natural language processing applications, such as dialog medical diagnosis systems and information retrieval engines calibrated specifically for COVID-19. These applications rely on the ability to measure semantic textual similarity (STS), making STS a fundamental task that can benefit several downstream applications. However, existing STS datasets and models fail to translate their performance to a domain-specific environment such as COVID-19. To overcome this gap, we introduce CORD19STS dataset which includes 13,710 annotated sentence pairs collected from COVID-19 open research dataset (CORD-19) challenge. To be specific, we generated one million sentence pairs using different sampling strategies. We then used a finetuned BERT-like language model, which we call Sen-SCI-CORD19-BERT, to calculate the similarity scores between sentence pairs to provide a balanced dataset with respect to the different semantic similarity levels, which gives us a total of 32K sentence pairs. Each sentence pair was annotated by five Amazon Mechanical Turk (AMT) crowd workers, where the labels represent different semantic similarity levels between the sentence pairs (i.e. related, somewhat-related, and not-related). After employing a rigorous qualification tasks to verify collected annotations, our final CORD19STS dataset includes 13,710 sentence pairs.
Multi-Modal Fingerprint Presentation Attack Detection: Evaluation On A New Dataset
Jun 16, 2020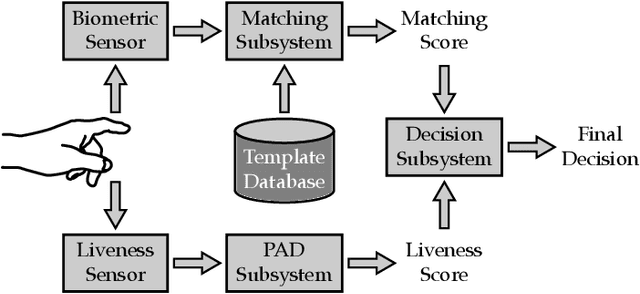

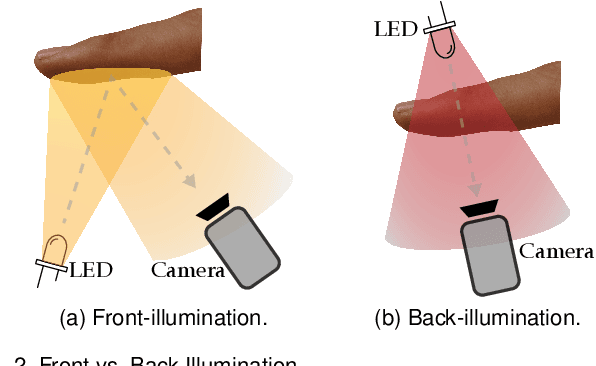
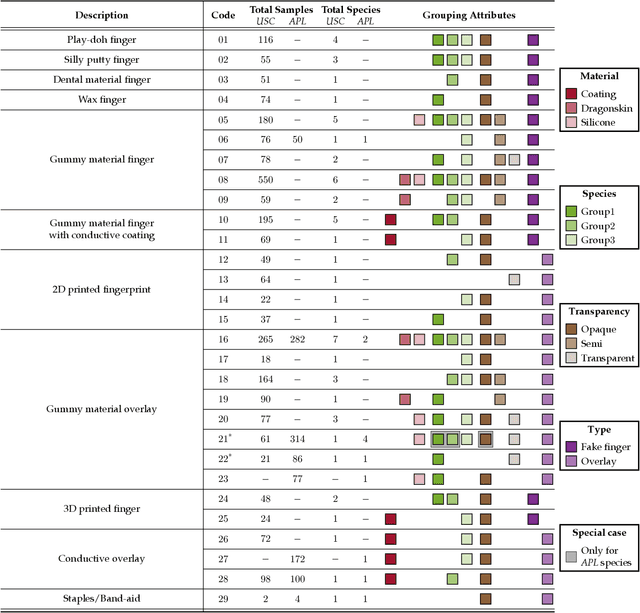
Fingerprint presentation attack detection is becoming an increasingly challenging problem due to the continuous advancement of attack preparation techniques, which generate realistic-looking fake fingerprint presentations. In this work, rather than relying on legacy fingerprint images, which are widely used in the community, we study the usefulness of multiple recently introduced sensing modalities. Our study covers front-illumination imaging using short-wave-infrared, near-infrared, and laser illumination; and back-illumination imaging using near-infrared light. Toward studying the effectiveness of each of these unconventional sensing modalities and their fusion for liveness detection, we conducted a comprehensive analysis using a fully convolutional deep neural network framework. Our evaluation compares different combination of the new sensing modalities to legacy data from one of our collections as well as the public LivDet2015 dataset, showing the superiority of the new sensing modalities in most cases. It also covers the cases of known and unknown attacks and the cases of intra-dataset and inter-dataset evaluations. Our results indicate that the power of our approach stems from the nature of the captured data rather than the employed classification framework, which justifies the extra cost for hardware-based (or hybrid) solutions. We plan to publicly release one of our dataset collections.
On the Effectiveness of Laser Speckle Contrast Imaging and Deep Neural Networks for Detecting Known and Unknown Fingerprint Presentation Attacks
Jun 06, 2019

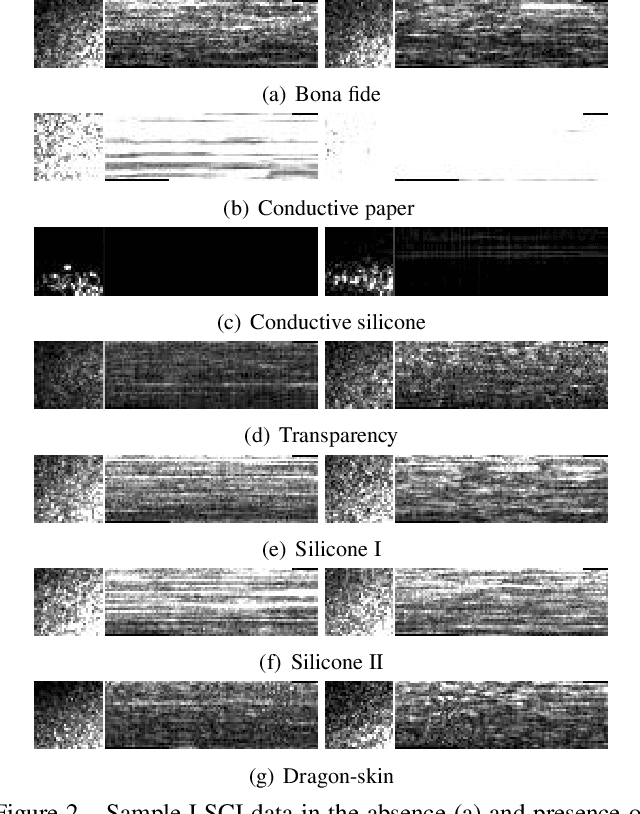

Fingerprint presentation attack detection (FPAD) is becoming an increasingly challenging problem due to the continuous advancement of attack techniques, which generate `realistic-looking' fake fingerprint presentations. Recently, laser speckle contrast imaging (LSCI) has been introduced as a new sensing modality for FPAD. LSCI has the interesting characteristic of capturing the blood flow under the skin surface. Toward studying the importance and effectiveness of LSCI for FPAD, we conduct a comprehensive study using different patch-based deep neural network architectures. Our studied architectures include 2D and 3D convolutional networks as well as a recurrent network using long short-term memory (LSTM) units. The study demonstrates that strong FPAD performance can be achieved using LSCI. We evaluate the different models over a new large dataset. The dataset consists of 3743 bona fide samples, collected from 335 unique subjects, and 218 presentation attack samples, including six different types of attacks. To examine the effect of changing the training and testing sets, we conduct a 3-fold cross validation evaluation. To examine the effect of the presence of an unseen attack, we apply a leave-one-attack out strategy. The FPAD classification results of the networks, which are separately optimized and tuned for the temporal and spatial patch-sizes, indicate that the best performance is achieved by LSTM.