 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionCounterfactuals: Inferring High-dimensional Counterfactuals with Guidance of Causal Representations
Jul 30, 2024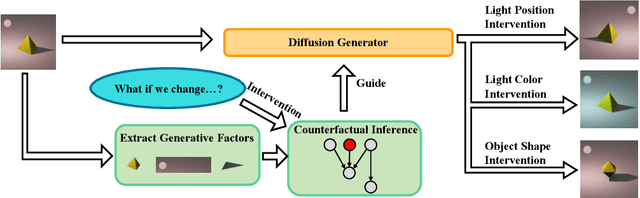
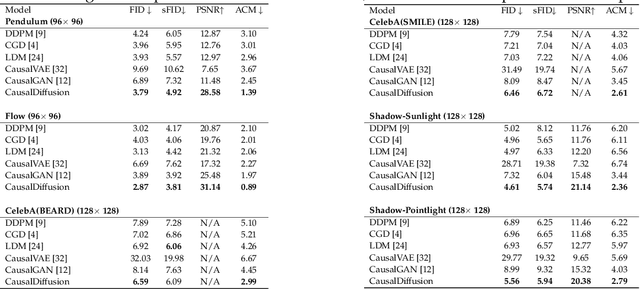
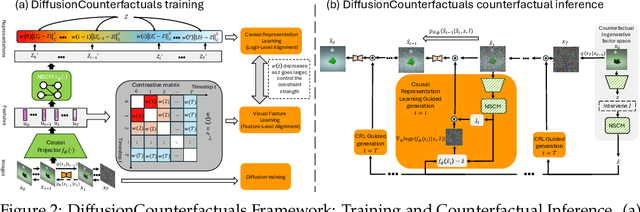
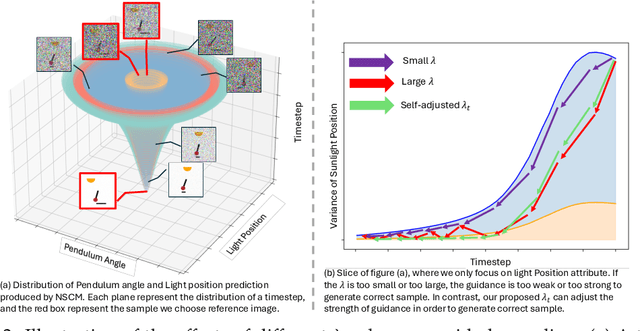
Accurate estimation of counterfactual outcomes in high-dimensional data is crucial for decision-making and understanding causal relationships and intervention outcomes in various domains, including healthcare, economics, and social sciences. However, existing methods often struggle to generate accurate and consistent counterfactuals, particularly when the causal relationships are complex. We propose a novel framework that incorporates causal mechanisms and diffusion models to generate high-quality counterfactual samples guided by causal representation. Our approach introduces a novel, theoretically grounded training and sampling process that enables the model to consistently generate accurate counterfactual high-dimensional data under multiple intervention steps. Experimental results on various synthetic and real benchmarks demonstrate the proposed approach outperforms state-of-the-art methods in generating accurate and high-quality counterfactuals, using different evaluation metrics.
TrainFors: A Large Benchmark Training Dataset for Image Manipulation Detection and Localization
Aug 10, 2023



The evaluation datasets and metrics for image manipulation detection and localization (IMDL) research have been standardized. But the training dataset for such a task is still nonstandard. Previous researchers have used unconventional and deviating datasets to train neural networks for detecting image forgeries and localizing pixel maps of manipulated regions. For a fair comparison, the training set, test set, and evaluation metrics should be persistent. Hence, comparing the existing methods may not seem fair as the results depend heavily on the training datasets as well as the model architecture. Moreover, none of the previous works release the synthetic training dataset used for the IMDL task. We propose a standardized benchmark training dataset for image splicing, copy-move forgery, removal forgery, and image enhancement forgery. Furthermore, we identify the problems with the existing IMDL datasets and propose the required modifications. We also train the state-of-the-art IMDL methods on our proposed TrainFors1 dataset for a fair evaluation and report the actual performance of these methods under similar conditions.
SW-VAE: Weakly Supervised Learn Disentangled Representation Via Latent Factor Swapping
Sep 21, 2022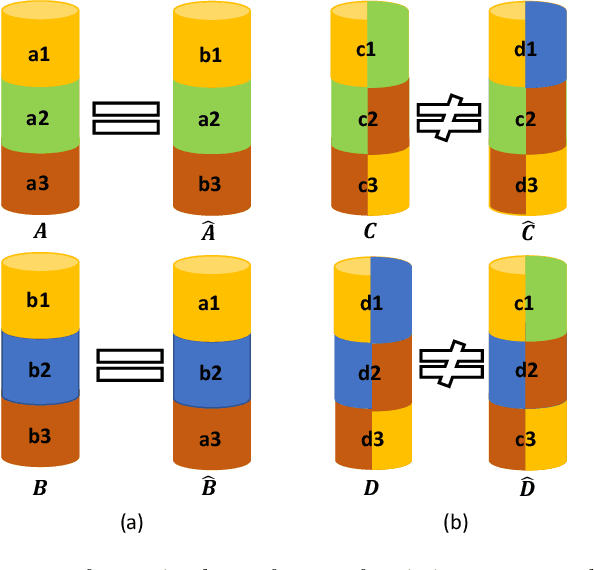
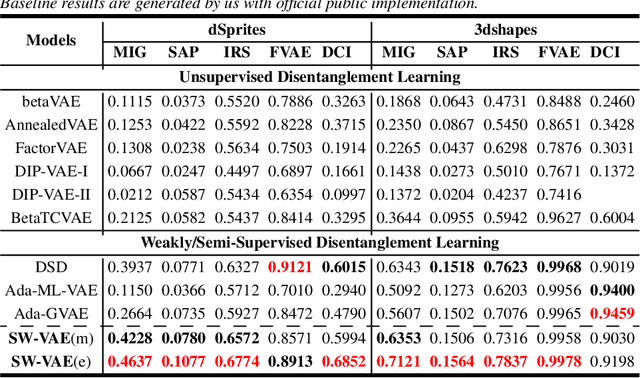
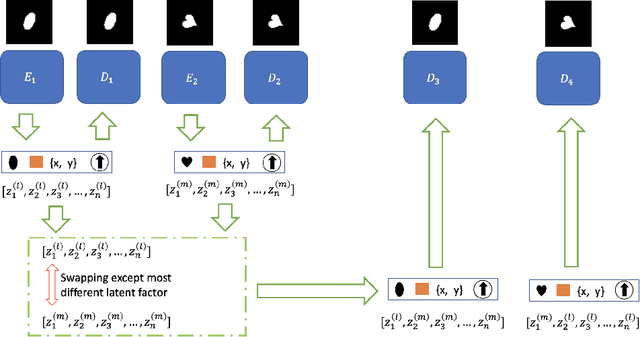
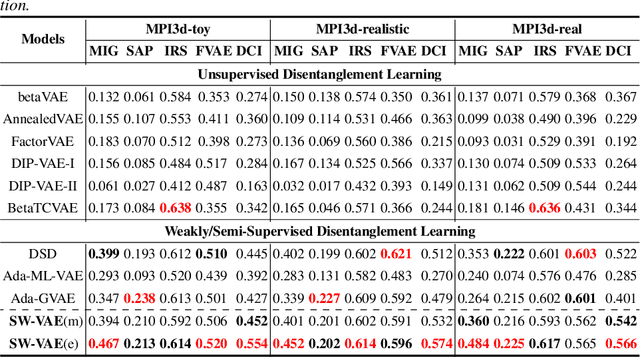
Representation disentanglement is an important goal of representation learning that benefits various downstream tasks. To achieve this goal, many unsupervised learning representation disentanglement approaches have been developed. However, the training process without utilizing any supervision signal have been proved to be inadequate for disentanglement representation learning. Therefore, we propose a novel weakly-supervised training approach, named as SW-VAE, which incorporates pairs of input observations as supervision signals by using the generative factors of datasets. Furthermore, we introduce strategies to gradually increase the learning difficulty during training to smooth the training process. As shown on several datasets, our model shows significant improvement over state-of-the-art (SOTA) methods on representation disentanglement tasks.
Weakly Supervised Invariant Representation Learning Via Disentangling Known and Unknown Nuisance Factors
Sep 15, 2022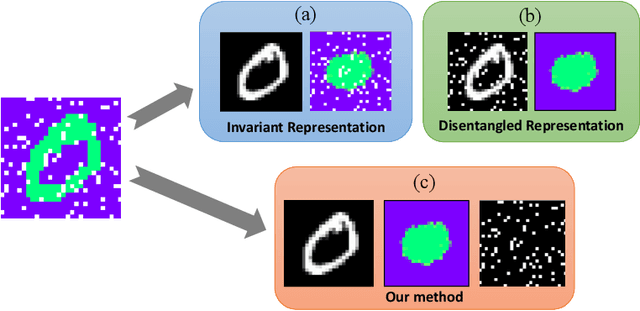
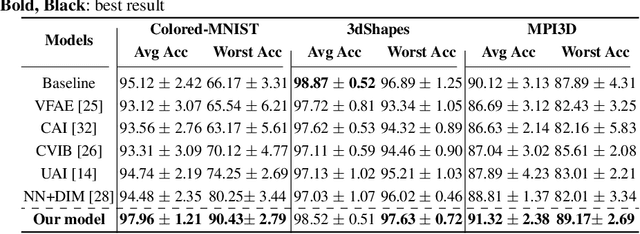
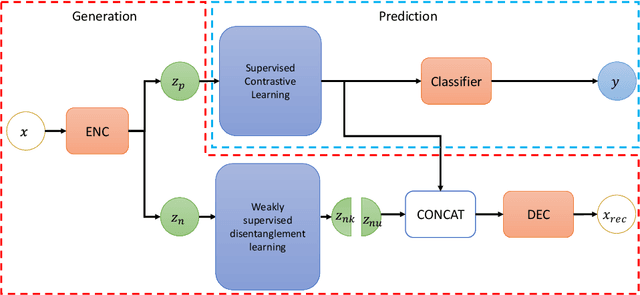
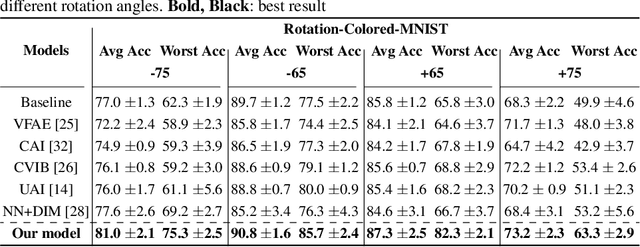
Disentangled and invariant representations are two critical goals of representation learning and many approaches have been proposed to achieve either one of them. However, those two goals are actually complementary to each other so that we propose a framework to accomplish both of them simultaneously. We introduce a weakly supervised signal to learn disentangled representation which consists of three splits containing predictive, known nuisance and unknown nuisance information respectively. Furthermore, we incorporate contrastive method to enforce representation invariance. Experiments shows that the proposed method outperforms state-of-the-art (SOTA) methods on four standard benchmarks and shows that the proposed method can have better adversarial defense ability comparing to other methods without adversarial training.
CAT: Controllable Attribute Translation for Fair Facial Attribute Classification
Sep 14, 2022
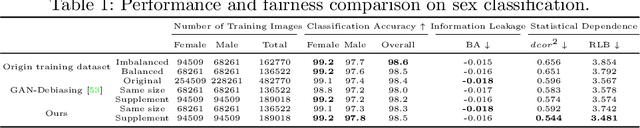

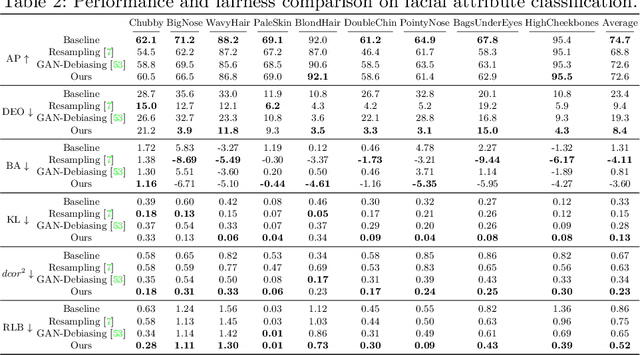
As the social impact of visual recognition has been under scrutiny, several protected-attribute balanced datasets emerged to address dataset bias in imbalanced datasets. However, in facial attribute classification, dataset bias stems from both protected attribute level and facial attribute level, which makes it challenging to construct a multi-attribute-level balanced real dataset. To bridge the gap, we propose an effective pipeline to generate high-quality and sufficient facial images with desired facial attributes and supplement the original dataset to be a balanced dataset at both levels, which theoretically satisfies several fairness criteria. The effectiveness of our method is verified on sex classification and facial attribute classification by yielding comparable task performance as the original dataset and further improving fairness in a comprehensive fairness evaluation with a wide range of metrics. Furthermore, our method outperforms both resampling and balanced dataset construction to address dataset bias, and debiasing models to address task bias.
P2M-DeTrack: Processing-in-Pixel-in-Memory for Energy-efficient and Real-Time Multi-Object Detection and Tracking
May 28, 2022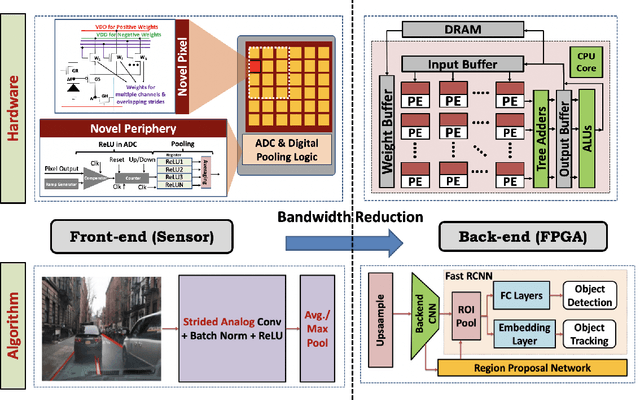
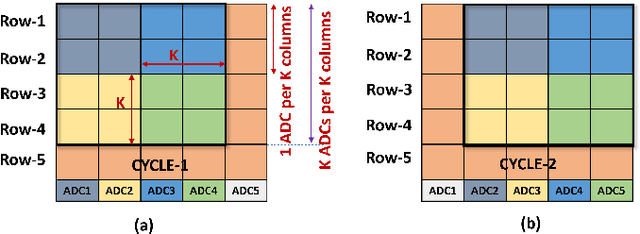
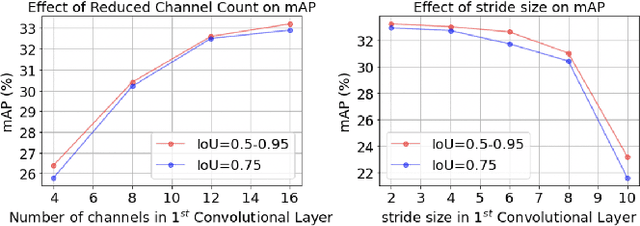
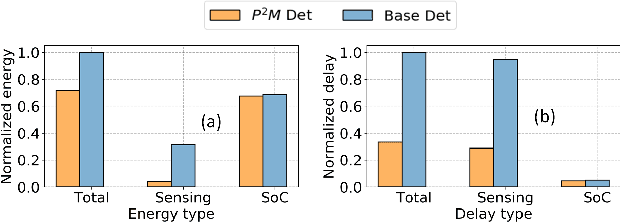
Today's high resolution, high frame rate cameras in autonomous vehicles generate a large volume of data that needs to be transferred and processed by a downstream processor or machine learning (ML) accelerator to enable intelligent computing tasks, such as multi-object detection and tracking. The massive amount of data transfer incurs significant energy, latency, and bandwidth bottlenecks, which hinders real-time processing. To mitigate this problem, we propose an algorithm-hardware co-design framework called Processing-in-Pixel-in-Memory-based object Detection and Tracking (P2M-DeTrack). P2M-DeTrack is based on a custom faster R-CNN-based model that is distributed partly inside the pixel array (front-end) and partly in a separate FPGA/ASIC (back-end). The proposed front-end in-pixel processing down-samples the input feature maps significantly with judiciously optimized strided convolution and pooling. Compared to a conventional baseline design that transfers frames of RGB pixels to the back-end, the resulting P2M-DeTrack designs reduce the data bandwidth between sensor and back-end by up to 24x. The designs also reduce the sensor and total energy (obtained from in-house circuit simulations at Globalfoundries 22nm technology node) per frame by 5.7x and 1.14x, respectively. Lastly, they reduce the sensing and total frame latency by an estimated 1.7x and 3x, respectively. We evaluate our approach on the multi-object object detection (tracking) task of the large-scale BDD100K dataset and observe only a 0.5% reduction in the mean average precision (0.8% reduction in the identification F1 score) compared to the state-of-the-art.
Information-Theoretic Bias Assessment Of Learned Representations Of Pretrained Face Recognition
Nov 09, 2021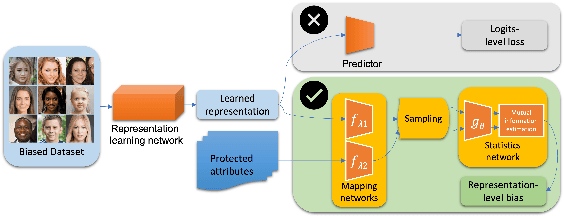
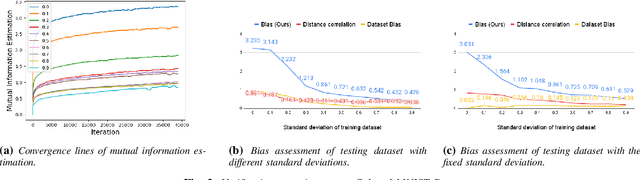
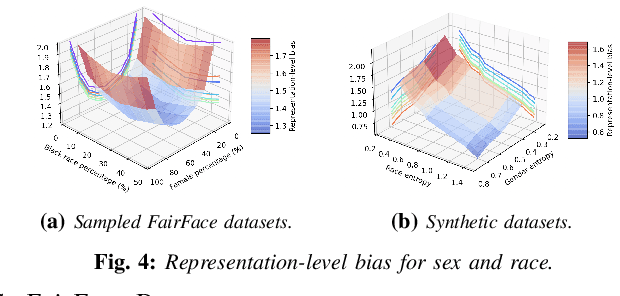

As equality issues in the use of face recognition have garnered a lot of attention lately, greater efforts have been made to debiased deep learning models to improve fairness to minorities. However, there is still no clear definition nor sufficient analysis for bias assessment metrics. We propose an information-theoretic, independent bias assessment metric to identify degree of bias against protected demographic attributes from learned representations of pretrained facial recognition systems. Our metric differs from other methods that rely on classification accuracy or examine the differences between ground truth and predicted labels of protected attributes predicted using a shallow network. Also, we argue, theoretically and experimentally, that logits-level loss is not adequate to explain bias since predictors based on neural networks will always find correlations. Further, we present a synthetic dataset that mitigates the issue of insufficient samples in certain cohorts. Lastly, we establish a benchmark metric by presenting advantages in clear discrimination and small variation comparing with other metrics, and evaluate the performance of different debiased models with the proposed metric.
Explaining Face Presentation Attack Detection Using Natural Language
Nov 08, 2021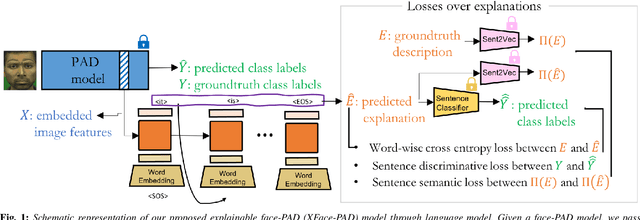
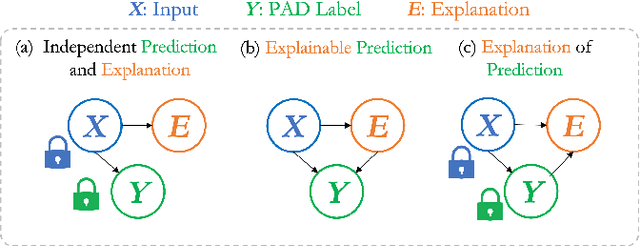
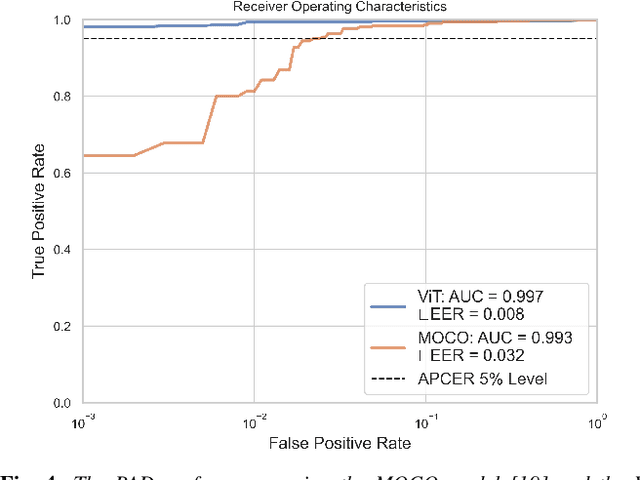
A large number of deep neural network based techniques have been developed to address the challenging problem of face presentation attack detection (PAD). Whereas such techniques' focus has been on improving PAD performance in terms of classification accuracy and robustness against unseen attacks and environmental conditions, there exists little attention on the explainability of PAD predictions. In this paper, we tackle the problem of explaining PAD predictions through natural language. Our approach passes feature representations of a deep layer of the PAD model to a language model to generate text describing the reasoning behind the PAD prediction. Due to the limited amount of annotated data in our study, we apply a light-weight LSTM network as our natural language generation model. We investigate how the quality of the generated explanations is affected by different loss functions, including the commonly used word-wise cross entropy loss, a sentence discriminative loss, and a sentence semantic loss. We perform our experiments using face images from a dataset consisting of 1,105 bona-fide and 924 presentation attack samples. Our quantitative and qualitative results show the effectiveness of our model for generating proper PAD explanations through text as well as the power of the sentence-wise losses. To the best of our knowledge, this is the first introduction of a joint biometrics-NLP task. Our dataset can be obtained through our GitHub page.
Partner-Assisted Learning for Few-Shot Image Classification
Sep 15, 2021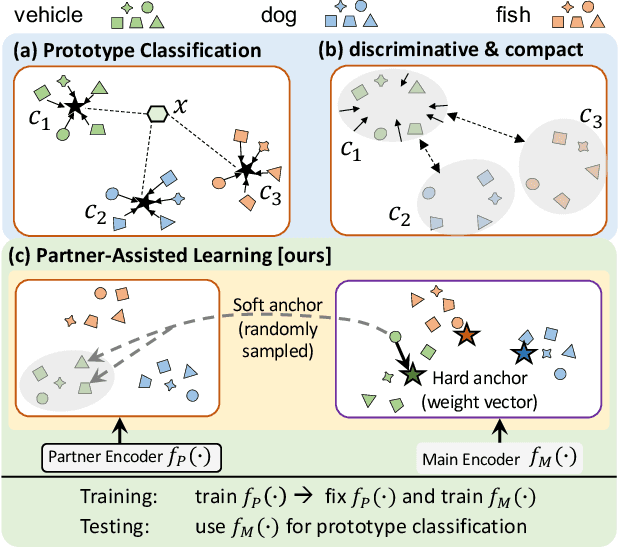
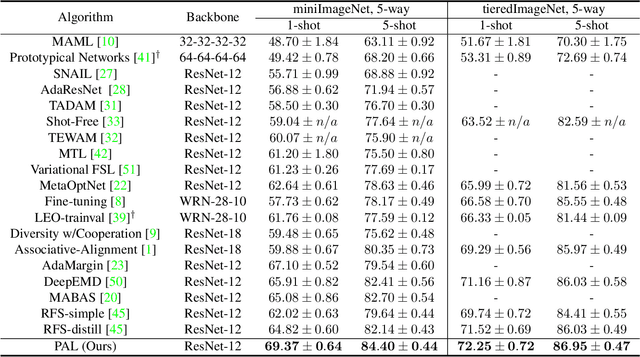
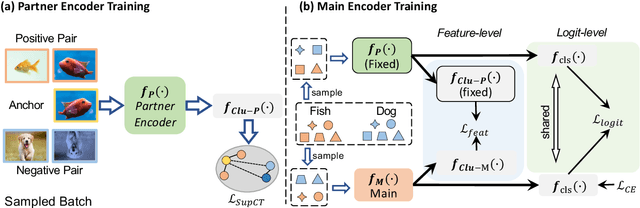
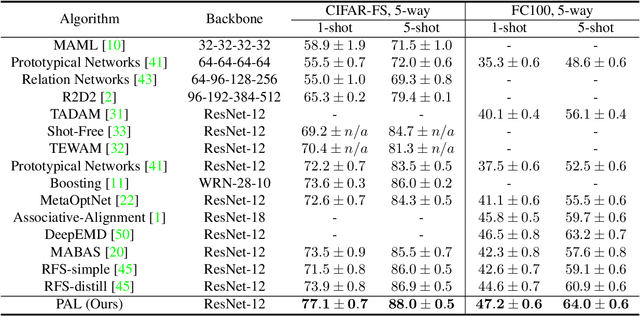
Few-shot Learning has been studied to mimic human visual capabilities and learn effective models without the need of exhaustive human annotation. Even though the idea of meta-learning for adaptation has dominated the few-shot learning methods, how to train a feature extractor is still a challenge. In this paper, we focus on the design of training strategy to obtain an elemental representation such that the prototype of each novel class can be estimated from a few labeled samples. We propose a two-stage training scheme, Partner-Assisted Learning (PAL), which first trains a partner encoder to model pair-wise similarities and extract features serving as soft-anchors, and then trains a main encoder by aligning its outputs with soft-anchors while attempting to maximize classification performance. Two alignment constraints from logit-level and feature-level are designed individually. For each few-shot task, we perform prototype classification. Our method consistently outperforms the state-of-the-art method on four benchmarks. Detailed ablation studies of PAL are provided to justify the selection of each component involved in training.
SIGN: Spatial-information Incorporated Generative Network for Generalized Zero-shot Semantic Segmentation
Aug 27, 2021
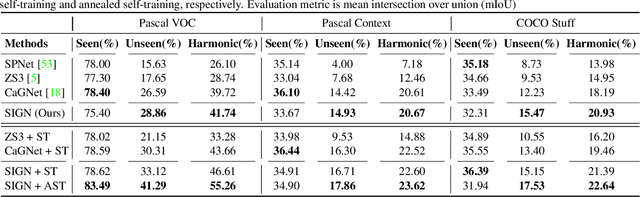
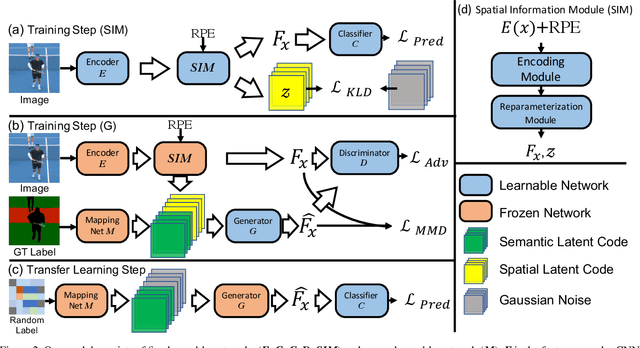
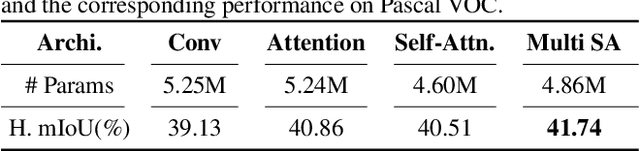
Unlike conventional zero-shot classification, zero-shot semantic segmentation predicts a class label at the pixel level instead of the image level. When solving zero-shot semantic segmentation problems, the need for pixel-level prediction with surrounding context motivates us to incorporate spatial information using positional encoding. We improve standard positional encoding by introducing the concept of Relative Positional Encoding, which integrates spatial information at the feature level and can handle arbitrary image sizes. Furthermore, while self-training is widely used in zero-shot semantic segmentation to generate pseudo-labels, we propose a new knowledge-distillation-inspired self-training strategy, namely Annealed Self-Training, which can automatically assign different importance to pseudo-labels to improve performance. We systematically study the proposed Relative Positional Encoding and Annealed Self-Training in a comprehensive experimental evaluation, and our empirical results confirm the effectiveness of our method on three benchmark datasets.