 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook, Learn and Leverage (L$^3$): Mitigating Visual-Domain Shift and Discovering Intrinsic Relations via Symbolic Alignment
Aug 30, 2024Modern deep learning models have demonstrated outstanding performance on discovering the underlying mechanisms when both visual appearance and intrinsic relations (e.g., causal structure) data are sufficient, such as Disentangled Representation Learning (DRL), Causal Representation Learning (CRL) and Visual Question Answering (VQA) methods. However, generalization ability of these models is challenged when the visual domain shifts and the relations data is absent during finetuning. To address this challenge, we propose a novel learning framework, Look, Learn and Leverage (L$^3$), which decomposes the learning process into three distinct phases and systematically utilize the class-agnostic segmentation masks as the common symbolic space to align visual domains. Thus, a relations discovery model can be trained on the source domain, and when the visual domain shifts and the intrinsic relations are absent, the pretrained relations discovery model can be directly reused and maintain a satisfactory performance. Extensive performance evaluations are conducted on three different tasks: DRL, CRL and VQA, and show outstanding results on all three tasks, which reveals the advantages of L$^3$.
An Investigation on The Position Encoding in Vision-Based Dynamics Prediction
Aug 27, 2024Despite the success of vision-based dynamics prediction models, which predict object states by utilizing RGB images and simple object descriptions, they were challenged by environment misalignments. Although the literature has demonstrated that unifying visual domains with both environment context and object abstract, such as semantic segmentation and bounding boxes, can effectively mitigate the visual domain misalignment challenge, discussions were focused on the abstract of environment context, and the insight of using bounding box as the object abstract is under-explored. Furthermore, we notice that, as empirical results shown in the literature, even when the visual appearance of objects is removed, object bounding boxes alone, instead of being directly fed into the network, can indirectly provide sufficient position information via the Region of Interest Pooling operation for dynamics prediction. However, previous literature overlooked discussions regarding how such position information is implicitly encoded in the dynamics prediction model. Thus, in this paper, we provide detailed studies to investigate the process and necessary conditions for encoding position information via using the bounding box as the object abstract into output features. Furthermore, we study the limitation of solely using object abstracts, such that the dynamics prediction performance will be jeopardized when the environment context varies.
DiffusionCounterfactuals: Inferring High-dimensional Counterfactuals with Guidance of Causal Representations
Jul 30, 2024Accurate estimation of counterfactual outcomes in high-dimensional data is crucial for decision-making and understanding causal relationships and intervention outcomes in various domains, including healthcare, economics, and social sciences. However, existing methods often struggle to generate accurate and consistent counterfactuals, particularly when the causal relationships are complex. We propose a novel framework that incorporates causal mechanisms and diffusion models to generate high-quality counterfactual samples guided by causal representation. Our approach introduces a novel, theoretically grounded training and sampling process that enables the model to consistently generate accurate counterfactual high-dimensional data under multiple intervention steps. Experimental results on various synthetic and real benchmarks demonstrate the proposed approach outperforms state-of-the-art methods in generating accurate and high-quality counterfactuals, using different evaluation metrics.
SABAF: Removing Strong Attribute Bias from Neural Networks with Adversarial Filtering
Nov 16, 2023Ensuring a neural network is not relying on protected attributes (e.g., race, sex, age) for prediction is crucial in advancing fair and trustworthy AI. While several promising methods for removing attribute bias in neural networks have been proposed, their limitations remain under-explored. To that end, in this work, we mathematically and empirically reveal the limitation of existing attribute bias removal methods in presence of strong bias and propose a new method that can mitigate this limitation. Specifically, we first derive a general non-vacuous information-theoretical upper bound on the performance of any attribute bias removal method in terms of the bias strength, revealing that they are effective only when the inherent bias in the dataset is relatively weak. Next, we derive a necessary condition for the existence of any method that can remove attribute bias regardless of the bias strength. Inspired by this condition, we then propose a new method using an adversarial objective that directly filters out protected attributes in the input space while maximally preserving all other attributes, without requiring any specific target label. The proposed method achieves state-of-the-art performance in both strong and moderate bias settings. We provide extensive experiments on synthetic, image, and census datasets, to verify the derived theoretical bound and its consequences in practice, and evaluate the effectiveness of the proposed method in removing strong attribute bias.
Information-Theoretic Bounds on The Removal of Attribute-Specific Bias From Neural Networks
Oct 08, 2023Ensuring a neural network is not relying on protected attributes (e.g., race, sex, age) for predictions is crucial in advancing fair and trustworthy AI. While several promising methods for removing attribute bias in neural networks have been proposed, their limitations remain under-explored. In this work, we mathematically and empirically reveal an important limitation of attribute bias removal methods in presence of strong bias. Specifically, we derive a general non-vacuous information-theoretical upper bound on the performance of any attribute bias removal method in terms of the bias strength. We provide extensive experiments on synthetic, image, and census datasets to verify the theoretical bound and its consequences in practice. Our findings show that existing attribute bias removal methods are effective only when the inherent bias in the dataset is relatively weak, thus cautioning against the use of these methods in smaller datasets where strong attribute bias can occur, and advocating the need for methods that can overcome this limitation.
Shadow Datasets, New challenging datasets for Causal Representation Learning
Aug 11, 2023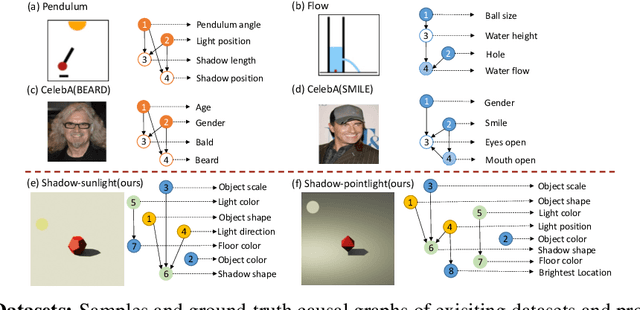
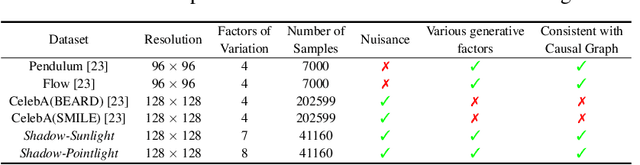

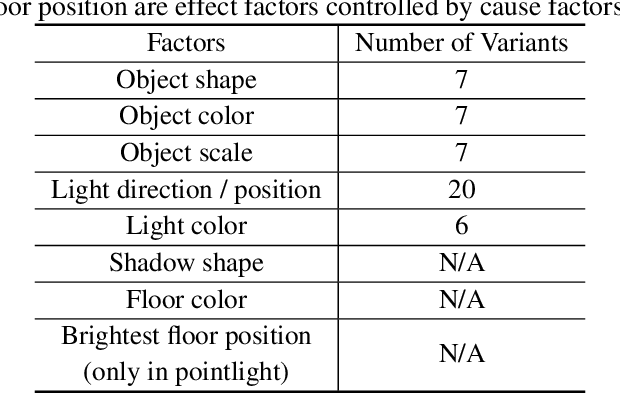
Discovering causal relations among semantic factors is an emergent topic in representation learning. Most causal representation learning (CRL) methods are fully supervised, which is impractical due to costly labeling. To resolve this restriction, weakly supervised CRL methods were introduced. To evaluate CRL performance, four existing datasets, Pendulum, Flow, CelebA(BEARD) and CelebA(SMILE), are utilized. However, existing CRL datasets are limited to simple graphs with few generative factors. Thus we propose two new datasets with a larger number of diverse generative factors and more sophisticated causal graphs. In addition, current real datasets, CelebA(BEARD) and CelebA(SMILE), the originally proposed causal graphs are not aligned with the dataset distributions. Thus, we propose modifications to them.
A Critical View Of Vision-Based Long-Term Dynamics Prediction Under Environment Misalignment
May 12, 2023



Dynamics prediction, which is the problem of predicting future states of scene objects based on current and prior states, is drawing increasing attention as an instance of learning physics. To solve this problem, Region Proposal Convolutional Interaction Network (RPCIN), a vision-based model, was proposed and achieved state-of-the-art performance in long-term prediction. RPCIN only takes raw images and simple object descriptions, such as the bounding box and segmentation mask of each object, as input. However, despite its success, the model's capability can be compromised under conditions of environment misalignment. In this paper, we investigate two challenging conditions for environment misalignment: Cross-Domain and Cross-Context by proposing four datasets that are designed for these challenges: SimB-Border, SimB-Split, BlenB-Border, and BlenB-Split. The datasets cover two domains and two contexts. Using RPCIN as a probe, experiments conducted on the combinations of the proposed datasets reveal potential weaknesses of the vision-based long-term dynamics prediction model. Furthermore, we propose a promising direction to mitigate the Cross-Domain challenge and provide concrete evidence supporting such a direction, which provides dramatic alleviation of the challenge on the proposed datasets.
SW-VAE: Weakly Supervised Learn Disentangled Representation Via Latent Factor Swapping
Sep 21, 2022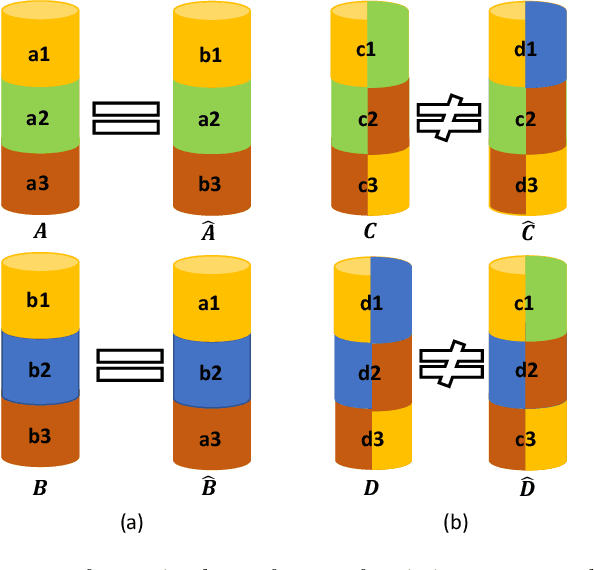
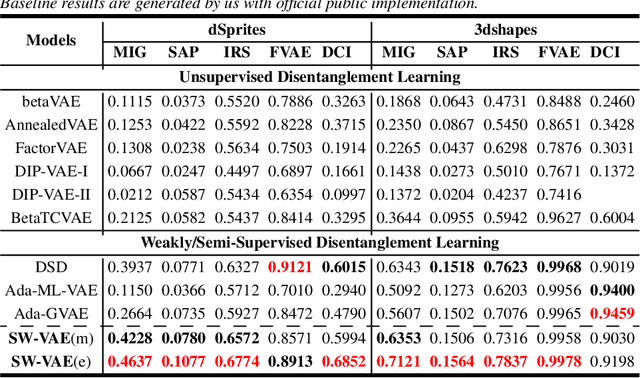
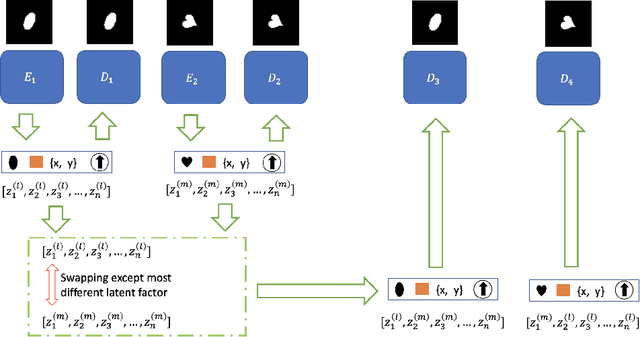
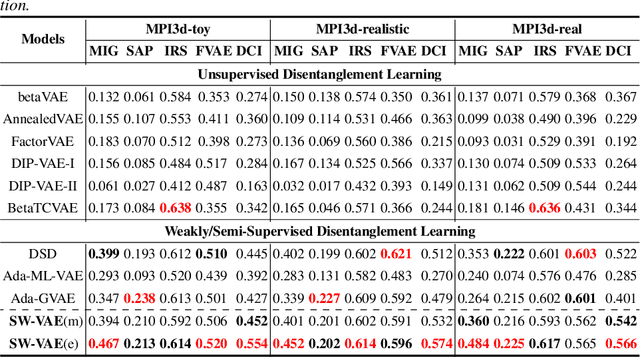
Representation disentanglement is an important goal of representation learning that benefits various downstream tasks. To achieve this goal, many unsupervised learning representation disentanglement approaches have been developed. However, the training process without utilizing any supervision signal have been proved to be inadequate for disentanglement representation learning. Therefore, we propose a novel weakly-supervised training approach, named as SW-VAE, which incorporates pairs of input observations as supervision signals by using the generative factors of datasets. Furthermore, we introduce strategies to gradually increase the learning difficulty during training to smooth the training process. As shown on several datasets, our model shows significant improvement over state-of-the-art (SOTA) methods on representation disentanglement tasks.
Weakly Supervised Invariant Representation Learning Via Disentangling Known and Unknown Nuisance Factors
Sep 15, 2022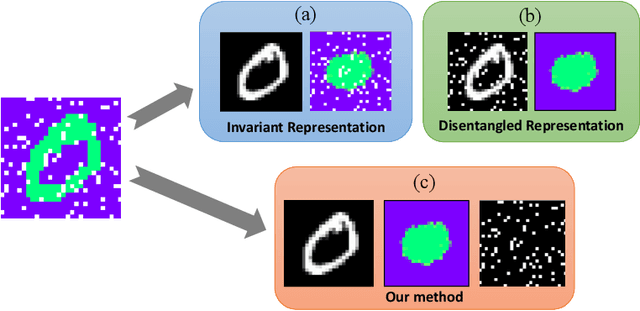
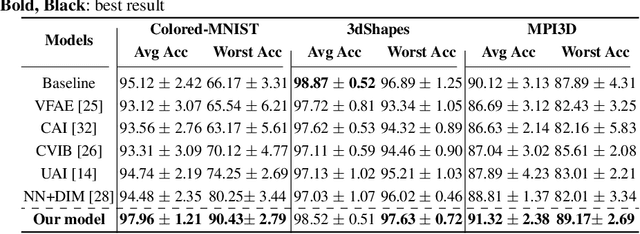
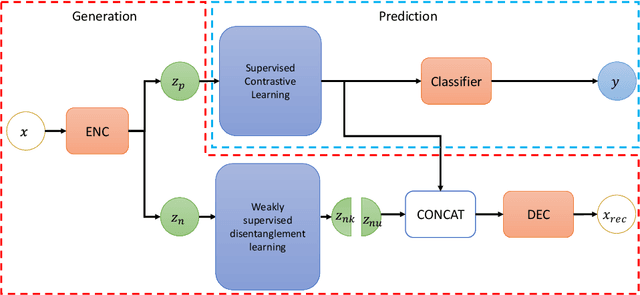
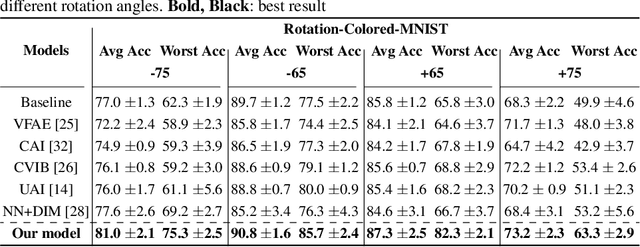
Disentangled and invariant representations are two critical goals of representation learning and many approaches have been proposed to achieve either one of them. However, those two goals are actually complementary to each other so that we propose a framework to accomplish both of them simultaneously. We introduce a weakly supervised signal to learn disentangled representation which consists of three splits containing predictive, known nuisance and unknown nuisance information respectively. Furthermore, we incorporate contrastive method to enforce representation invariance. Experiments shows that the proposed method outperforms state-of-the-art (SOTA) methods on four standard benchmarks and shows that the proposed method can have better adversarial defense ability comparing to other methods without adversarial training.
Do-Operation Guided Causal Representation Learning with Reduced Supervision Strength
Jun 03, 2022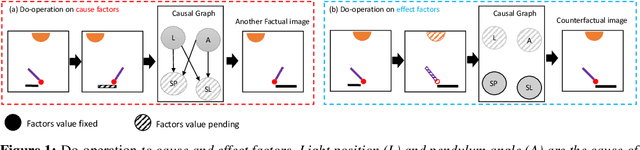
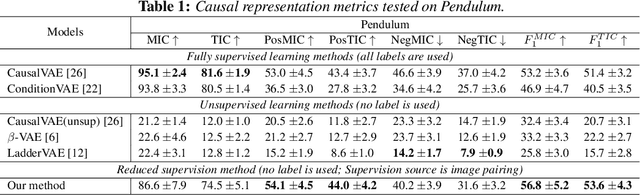
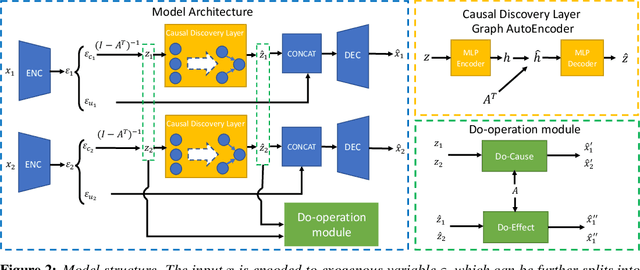
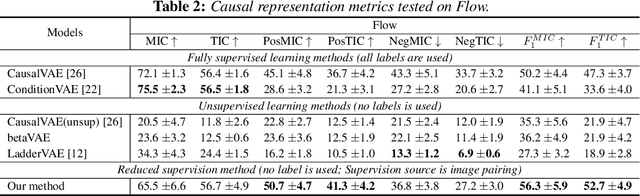
Causal representation learning has been proposed to encode relationships between factors presented in the high dimensional data. However, existing methods suffer from merely using a large amount of labeled data and ignore the fact that samples generated by the same causal mechanism follow the same causal relationships. In this paper, we seek to explore such information by leveraging do-operation for reducing supervision strength. We propose a framework which implements do-operation by swapping latent cause and effect factors encoded from a pair of inputs. Moreover, we also identify the inadequacy of existing causal representation metrics empirically and theoretically, and introduce new metrics for better evaluation. Experiments conducted on both synthetic and real datasets demonstrate the superiorities of our method compared with state-of-the-art methods.