 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSW-VAE: Weakly Supervised Learn Disentangled Representation Via Latent Factor Swapping
Paper and Code
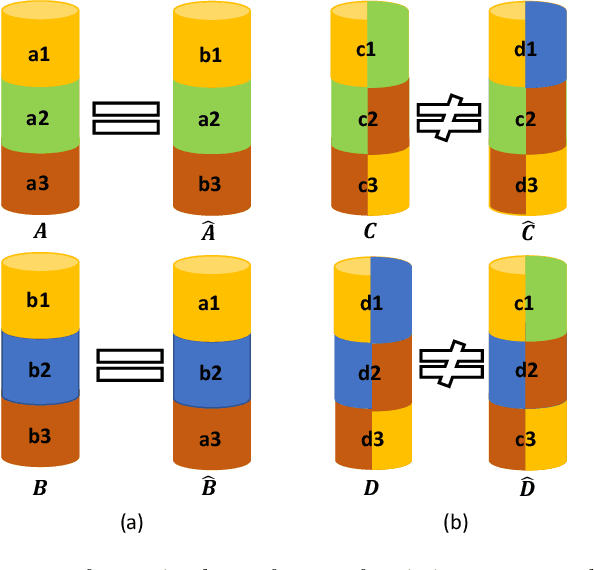
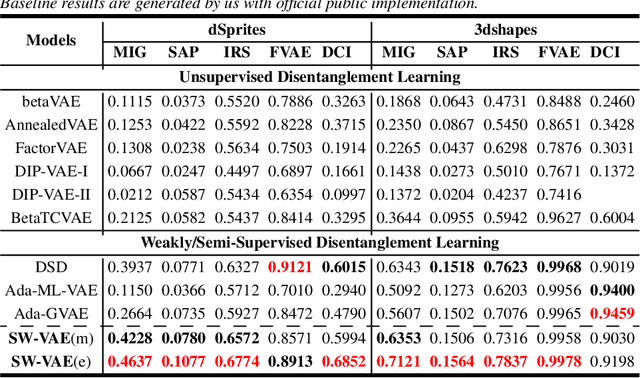
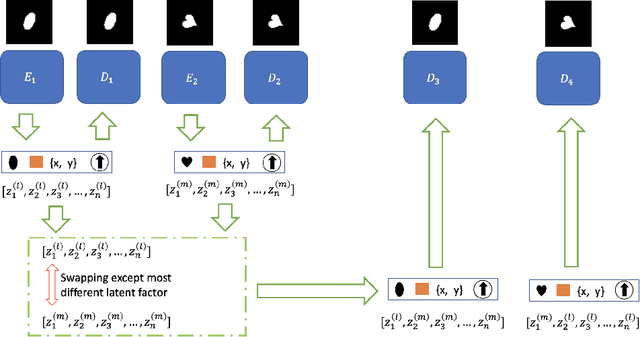
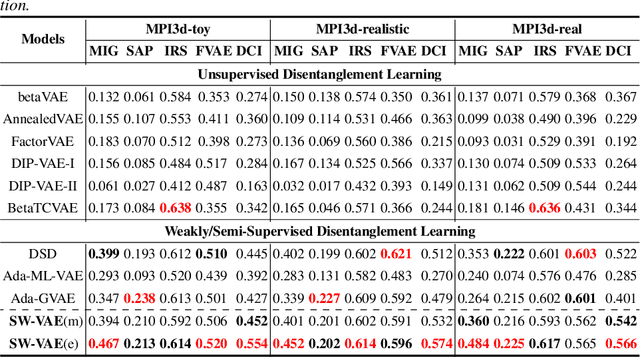
Representation disentanglement is an important goal of representation learning that benefits various downstream tasks. To achieve this goal, many unsupervised learning representation disentanglement approaches have been developed. However, the training process without utilizing any supervision signal have been proved to be inadequate for disentanglement representation learning. Therefore, we propose a novel weakly-supervised training approach, named as SW-VAE, which incorporates pairs of input observations as supervision signals by using the generative factors of datasets. Furthermore, we introduce strategies to gradually increase the learning difficulty during training to smooth the training process. As shown on several datasets, our model shows significant improvement over state-of-the-art (SOTA) methods on representation disentanglement tasks.