 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Invariant Representation Learning Via Disentangling Known and Unknown Nuisance Factors
Paper and Code
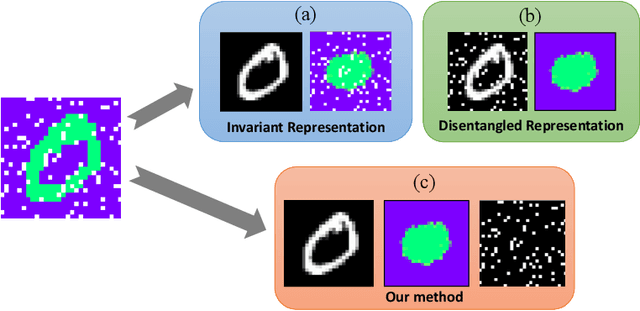
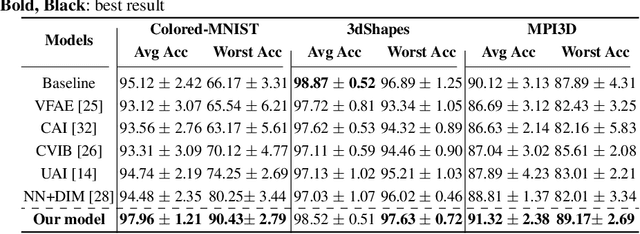
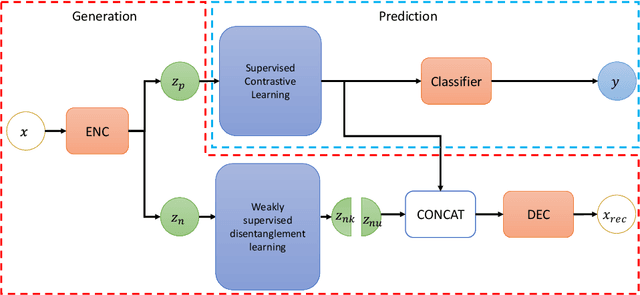
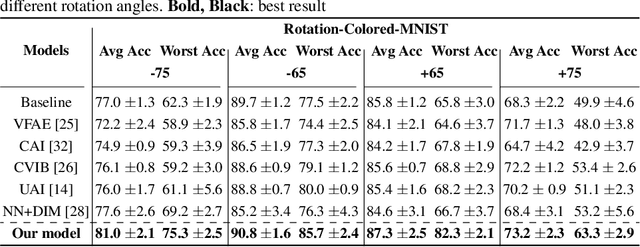
Disentangled and invariant representations are two critical goals of representation learning and many approaches have been proposed to achieve either one of them. However, those two goals are actually complementary to each other so that we propose a framework to accomplish both of them simultaneously. We introduce a weakly supervised signal to learn disentangled representation which consists of three splits containing predictive, known nuisance and unknown nuisance information respectively. Furthermore, we incorporate contrastive method to enforce representation invariance. Experiments shows that the proposed method outperforms state-of-the-art (SOTA) methods on four standard benchmarks and shows that the proposed method can have better adversarial defense ability comparing to other methods without adversarial training.