 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Image Dataset of Text Patches in Everyday Scenes
Paper and Code

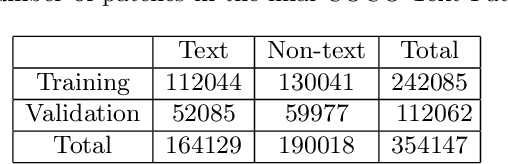

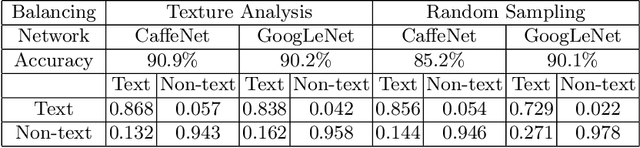
This paper describes a dataset containing small images of text from everyday scenes. The purpose of the dataset is to support the development of new automated systems that can detect and analyze text. Although much research has been devoted to text detection and recognition in scanned documents, relatively little attention has been given to text detection in other types of images, such as photographs that are posted on social-media sites. This new dataset, known as COCO-Text-Patch, contains approximately 354,000 small images that are each labeled as "text" or "non-text". This dataset particularly addresses the problem of text verification, which is an essential stage in the end-to-end text detection and recognition pipeline. In order to evaluate the utility of this dataset, it has been used to train two deep convolution neural networks to distinguish text from non-text. One network is inspired by the GoogLeNet architecture, and the second one is based on CaffeNet. Accuracy levels of 90.2% and 90.9% were obtained using the two networks, respectively. All of the images, source code, and deep-learning trained models described in this paper will be publicly available