 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInput Fast-Forwarding for Better Deep Learning
Paper and Code
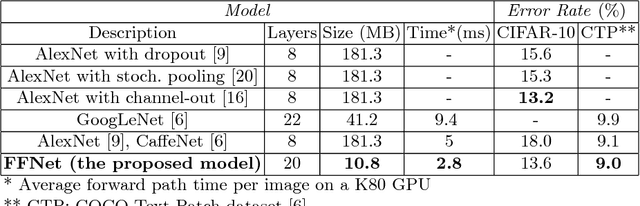
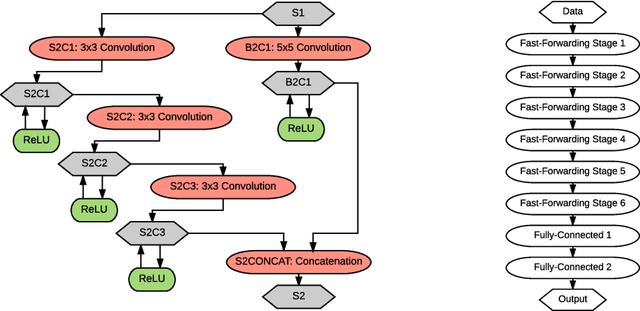

This paper introduces a new architectural framework, known as input fast-forwarding, that can enhance the performance of deep networks. The main idea is to incorporate a parallel path that sends representations of input values forward to deeper network layers. This scheme is substantially different from "deep supervision" in which the loss layer is re-introduced to earlier layers. The parallel path provided by fast-forwarding enhances the training process in two ways. First, it enables the individual layers to combine higher-level information (from the standard processing path) with lower-level information (from the fast-forward path). Second, this new architecture reduces the problem of vanishing gradients substantially because the fast-forwarding path provides a shorter route for gradient backpropagation. In order to evaluate the utility of the proposed technique, a Fast-Forward Network (FFNet), with 20 convolutional layers along with parallel fast-forward paths, has been created and tested. The paper presents empirical results that demonstrate improved learning capacity of FFNet due to fast-forwarding, as compared to GoogLeNet (with deep supervision) and CaffeNet, which are 4x and 18x larger in size, respectively. All of the source code and deep learning models described in this paper will be made available to the entire research community