 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing the DOME Activation Functions
Paper and Code
Sep 30, 2021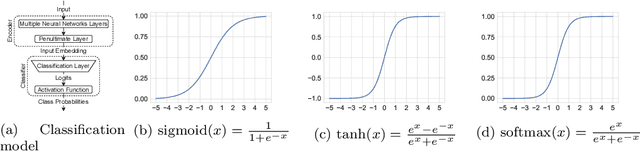
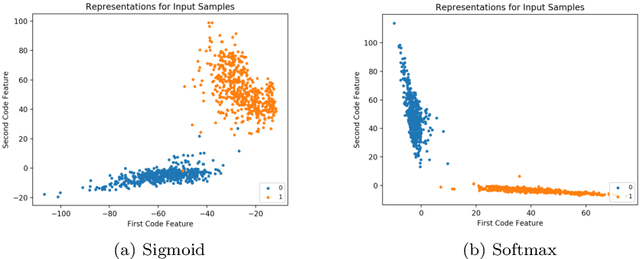
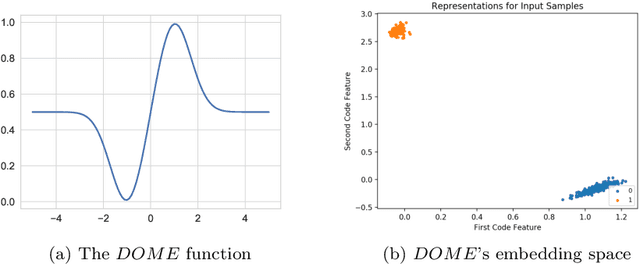
In this paper, we introduce a novel non-linear activation function that spontaneously induces class-compactness and regularization in the embedding space of neural networks. The function is dubbed DOME for Difference Of Mirrored Exponential terms. The basic form of the function can replace the sigmoid or the hyperbolic tangent functions as an output activation function for binary classification problems. The function can also be extended to the case of multi-class classification, and used as an alternative to the standard softmax function. It can also be further generalized to take more flexible shapes suitable for intermediate layers of a network. In this version of the paper, we only introduce the concept. In a subsequent version, experimental evaluation will be added.