 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Multifractal Image Segmentation
Jan 15, 2025



Multifractal analysis (MFA) provides a framework for the global characterization of image textures by describing the spatial fluctuations of their local regularity based on the multifractal spectrum. Several works have shown the interest of using MFA for the description of homogeneous textures in images. Nevertheless, natural images can be composed of several textures and, in turn, multifractal properties associated with those textures. This paper introduces a Bayesian multifractal segmentation method to model and segment multifractal textures by jointly estimating the multifractal parameters and labels on images. For this, a computationally and statistically efficient multifractal parameter estimation model for wavelet leaders is firstly developed, defining different multifractality parameters to different regions of an image. Then, a multiscale Potts Markov random field is introduced as a prior to model the inherent spatial and scale correlations between the labels of the wavelet leaders. A Gibbs sampling methodology is employed to draw samples from the posterior distribution of the parameters. Numerical experiments are conducted on synthetic multifractal images to evaluate the performance of the proposed segmentation approach. The proposed method achieves superior performance compared to traditional unsupervised segmentation techniques as well as modern deep learning-based approaches, showing its effectiveness for multifractal image segmentation.
In-Flight Estimation of Instrument Spectral Response Functions Using Sparse Representations
Apr 08, 2024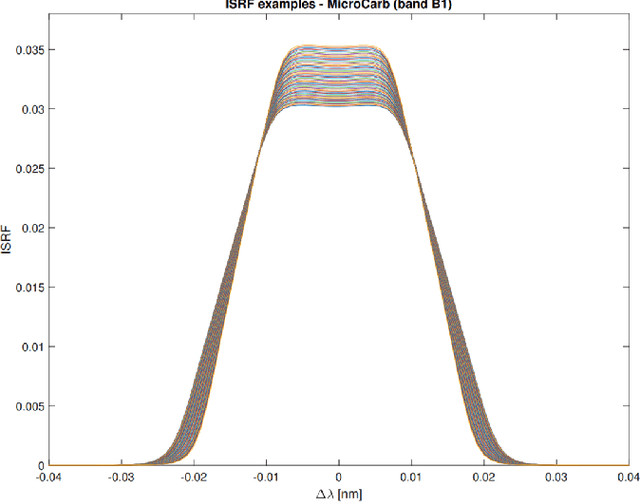

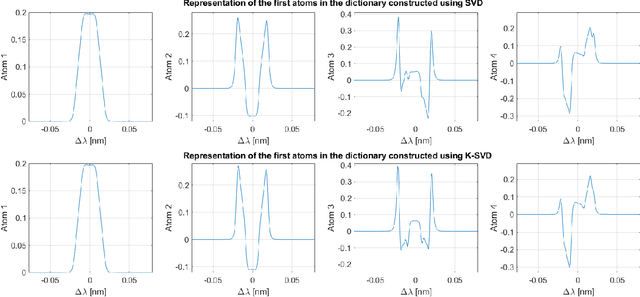
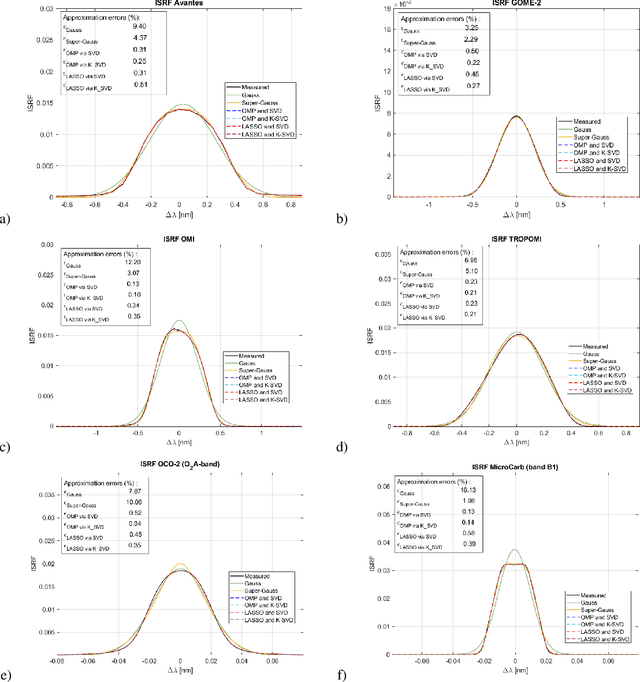
Accurate estimates of Instrument Spectral Response Functions (ISRFs) are crucial in order to have a good characterization of high resolution spectrometers. Spectrometers are composed of different optical elements that can induce errors in the measurements and therefore need to be modeled as accurately as possible. Parametric models are currently used to estimate these response functions. However, these models cannot always take into account the diversity of ISRF shapes that are encountered in practical applications. This paper studies a new ISRF estimation method based on a sparse representation of atoms belonging to a dictionary. This method is applied to different high-resolution spectrometers in order to assess its reproducibility for multiple remote sensing missions. The proposed method is shown to be very competitive when compared to the more commonly used parametric models, and yields normalized ISRF estimation errors less than 1%.
HLoOP -- Hyperbolic 2-space Local Outlier Probabilities
Dec 06, 2023
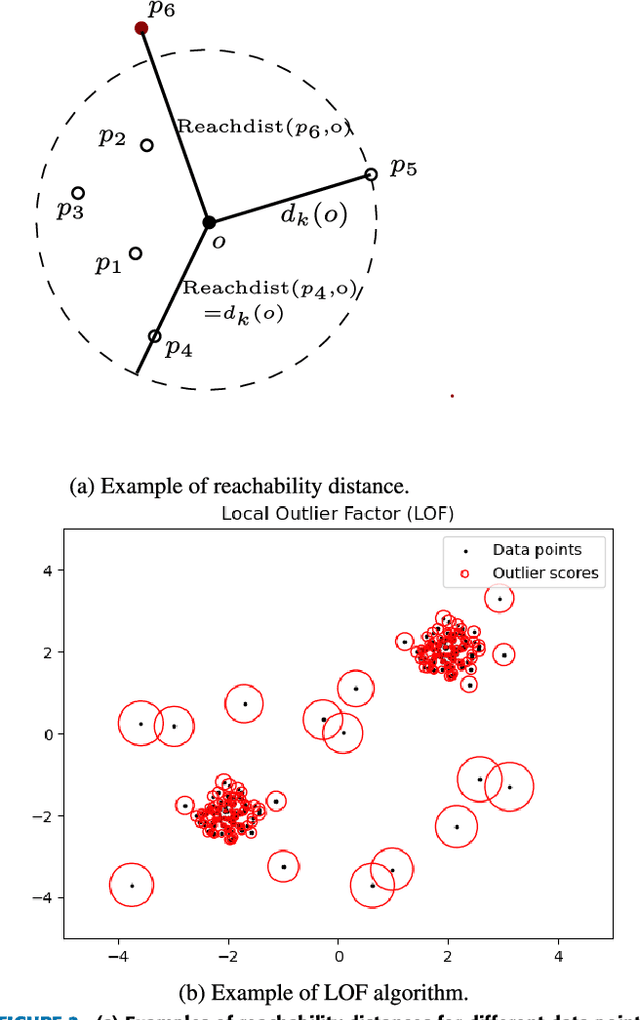


Hyperbolic geometry has recently garnered considerable attention in machine learning due to its capacity to embed hierarchical graph structures with low distortions for further downstream processing. This paper introduces a simple framework to detect local outliers for datasets grounded in hyperbolic 2-space referred to as HLoOP (Hyperbolic Local Outlier Probability). Within a Euclidean space, well-known techniques for local outlier detection are based on the Local Outlier Factor (LOF) and its variant, the LoOP (Local Outlier Probability), which incorporates probabilistic concepts to model the outlier level of a data vector. The developed HLoOP combines the idea of finding nearest neighbors, density-based outlier scoring with a probabilistic, statistically oriented approach. Therefore, the method consists in computing the Riemmanian distance of a data point to its nearest neighbors following a Gaussian probability density function expressed in a hyperbolic space. This is achieved by defining a Gaussian cumulative distribution in this space. The HLoOP algorithm is tested on the WordNet dataset yielding promising results. Code and data will be made available on request for reproductibility.
A Robust and Flexible EM Algorithm for Mixtures of Elliptical Distributions with Missing Data
Jan 28, 2022
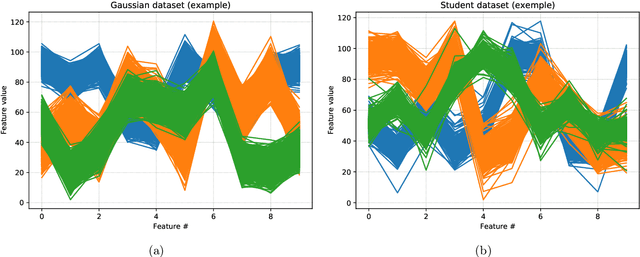
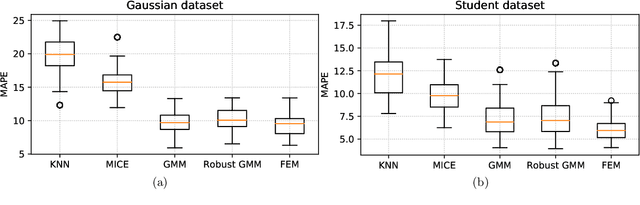
This paper tackles the problem of missing data imputation for noisy and non-Gaussian data. A classical imputation method, the Expectation Maximization (EM) algorithm for Gaussian mixture models, has shown interesting properties when compared to other popular approaches such as those based on k-nearest neighbors or on multiple imputations by chained equations. However, Gaussian mixture models are known to be not robust to heterogeneous data, which can lead to poor estimation performance when the data is contaminated by outliers or come from a non-Gaussian distributions. To overcome this issue, a new expectation maximization algorithm is investigated for mixtures of elliptical distributions with the nice property of handling potential missing data. The complete-data likelihood associated with mixtures of elliptical distributions is well adapted to the EM framework thanks to its conditional distribution, which is shown to be a Student distribution. Experimental results on synthetic data demonstrate that the proposed algorithm is robust to outliers and can be used with non-Gaussian data. Furthermore, experiments conducted on real-world datasets show that this algorithm is very competitive when compared to other classical imputation methods.
Reconstruction of Sentinel-2 Time Series Using Robust Gaussian Mixture Models -- Application to the Detection of Anomalous Crop Development in wheat and rapeseed crops
Oct 22, 2021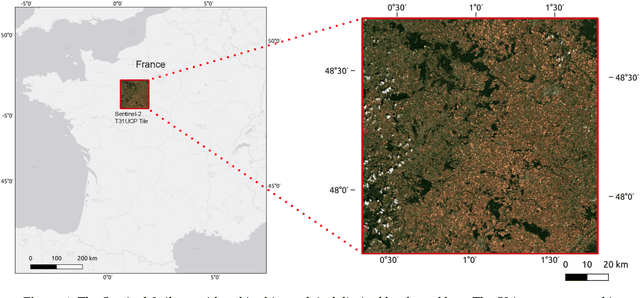
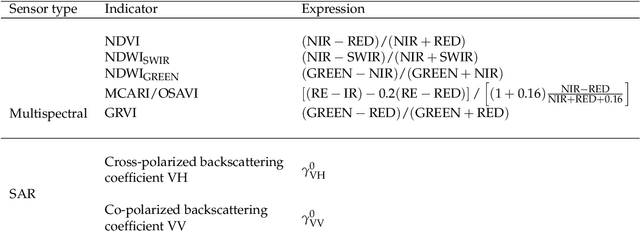
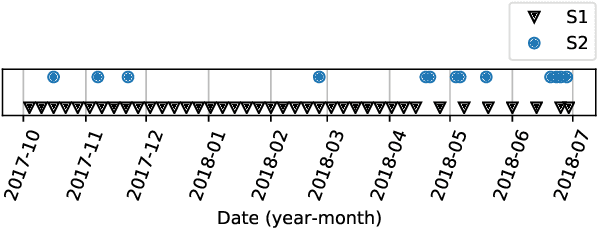
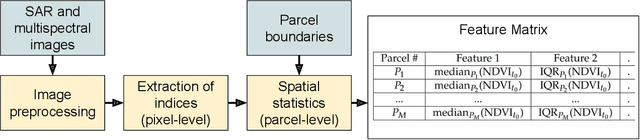
Missing data is a recurrent problem in remote sensing, mainly due to cloud coverage for multispectral images and acquisition problems. This can be a critical issue for crop monitoring, especially for applications relying on machine learning techniques, which generally assume that the feature matrix does not have missing values. This paper proposes a Gaussian Mixture Model (GMM) for the reconstruction of parcel-level features extracted from multispectral images. A robust version of the GMM is also investigated, since datasets can be contaminated by inaccurate samples or features (e.g., wrong crop type reported, inaccurate boundaries, undetected clouds, etc). Additional features extracted from Synthetic Aperture Radar (SAR) images using Sentinel-1 data are also used to provide complementary information and improve the imputations. The robust GMM investigated in this work assigns reduced weights to the outliers during the estimation of the GMM parameters, which improves the final reconstruction. These weights are computed at each step of an Expectation-Maximization (EM) algorithm by using outlier scores provided by the isolation forest algorithm. Experimental validation is conducted on rapeseed and wheat parcels located in the Beauce region (France). Overall, we show that the GMM imputation method outperforms other reconstruction strategies. A mean absolute error (MAE) of 0.013 (resp. 0.019) is obtained for the imputation of the median Normalized Difference Index (NDVI) of the rapeseed (resp. wheat) parcels. Other indicators (e.g., Normalized Difference Water Index) and statistics (for instance the interquartile range, which captures heterogeneity among the parcel indicator) are reconstructed at the same time with good accuracy. In a dataset contaminated by irrelevant samples, using the robust GMM is recommended since the standard GMM imputation can lead to inaccurate imputed values.
Unsupervised crop anomaly detection at the parcel-level using optical and SAR images: application to wheat and rapeseed crops
Apr 17, 2020
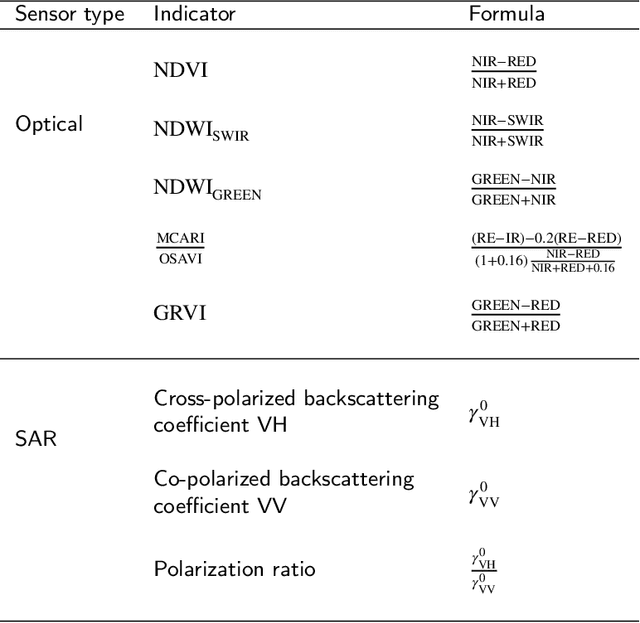

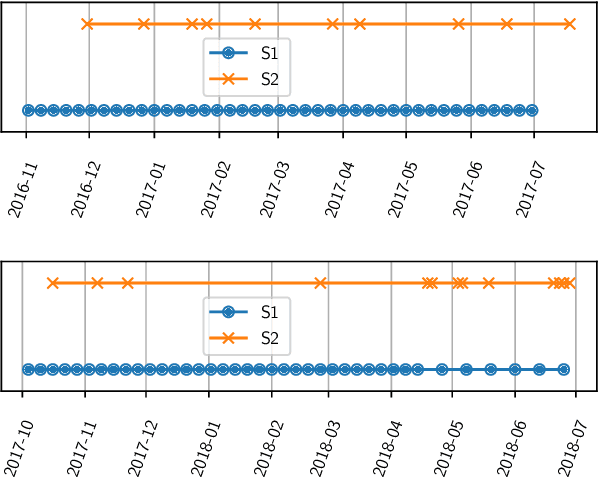
This paper proposes a generic approach for crop anomaly detection at the parcel-level based on unsupervised point anomaly detection techniques. The input data is derived from synthetic aperture radar (SAR) and optical images acquired using Sentinel-1 and Sentinel-2 satellites. The proposed strategy consists of four sequential steps: acquisition and preprocessing of optical and SAR images, extraction of optical and SAR indicators, computation of zonal statistics at the parcel-level and point anomaly detection. This paper analyzes different factors that can affect the results of anomaly detection such as the considered features and the anomaly detection algorithm used. The proposed procedure is validated on two crop types in Beauce (France), namely, rapeseed and wheat crops. Two different parcel delineation databases are considered to validate the robustness of the strategy to changes in parcel boundaries.
Seeing Around Corners with Edge-Resolved Transient Imaging
Feb 17, 2020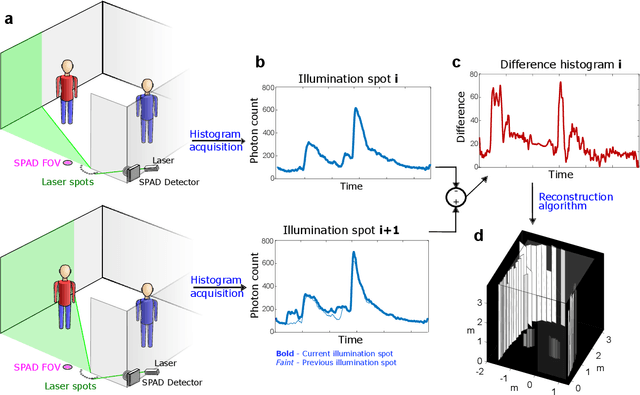
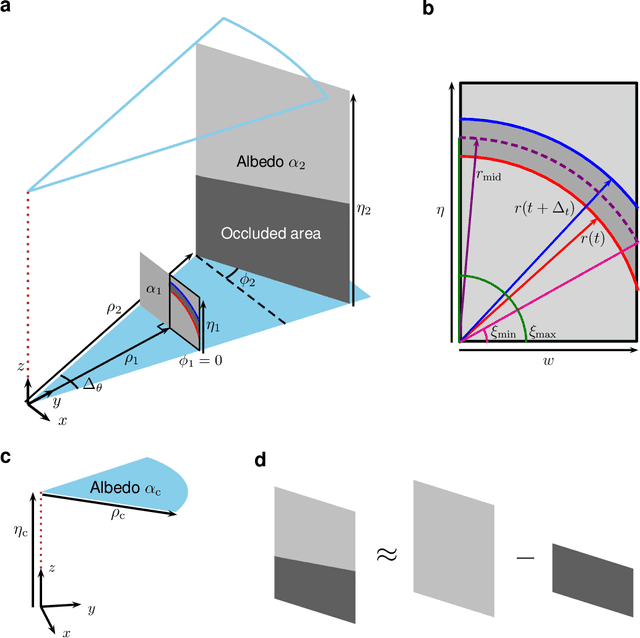
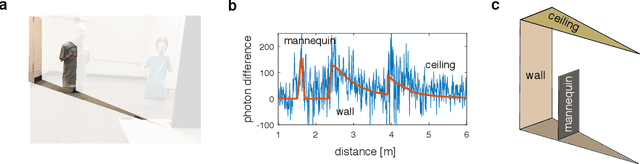

Non-line-of-sight (NLOS) imaging is a rapidly growing field seeking to form images of objects outside the field of view, with potential applications in search and rescue, reconnaissance, and even medical imaging. The critical challenge of NLOS imaging is that diffuse reflections scatter light in all directions, resulting in weak signals and a loss of directional information. To address this problem, we propose a method for seeing around corners that derives angular resolution from vertical edges and longitudinal resolution from the temporal response to a pulsed light source. We introduce an acquisition strategy, scene response model, and reconstruction algorithm that enable the formation of 2.5-dimensional representations -- a plan view plus heights -- and a 180$^{\circ}$ field of view (FOV) for large-scale scenes. Our experiments demonstrate accurate reconstructions of hidden rooms up to 3 meters in each dimension.
A Tensor Factorization Method for 3D Super-Resolution with Application to Dental CT
Jul 26, 2018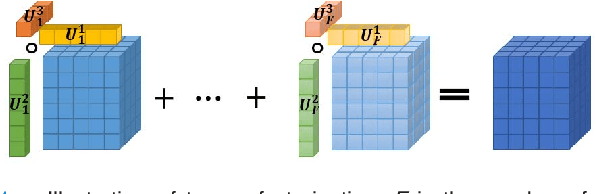
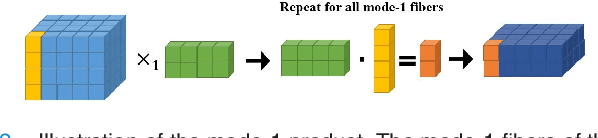
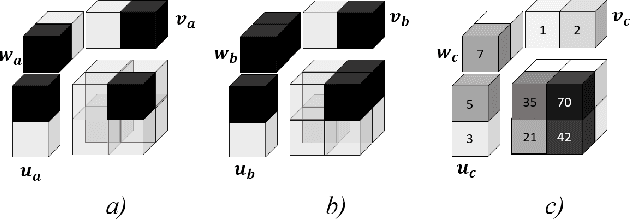
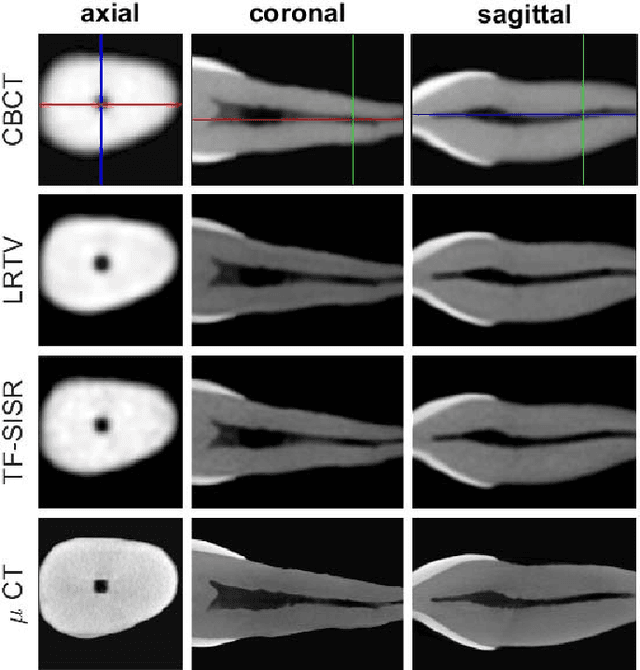
Available super-resolution techniques for 3D images are either computationally inefficient prior-knowledge-based iterative techniques or deep learning methods which require a large database of known low- and high-resolution image pairs. A recently introduced tensor-factorization-based approach offers a fast solution without the use of known image pairs or strict prior assumptions. In this article this factorization framework is investigated for single image resolution enhancement with an off-line estimate of the system point spread function. The technique is applied to 3D cone beam computed tomography for dental image resolution enhancement. To demonstrate the efficiency of our method, it is compared to a recent state-of-the-art iterative technique using low-rank and total variation regularizations. In contrast to this comparative technique, the proposed reconstruction technique gives a 2-order-of-magnitude improvement in running time -- 2 minutes compared to 2 hours for a dental volume of 282$\times$266$\times$392 voxels. Furthermore, it also offers slightly improved quantitative results (peak signal-to-noise ratio, segmentation quality). Another advantage of the presented technique is the low number of hyperparameters. As demonstrated in this paper, the framework is not sensitive to small changes of its parameters, proposing an ease of use.
A Fast Algorithm Based on a Sylvester-like Equation for LS Regression with GMRF Prior
Oct 09, 2017


This paper presents a fast approach for penalized least squares (LS) regression problems using a 2D Gaussian Markov random field (GMRF) prior. More precisely, the computation of the proximity operator of the LS criterion regularized by different GMRF potentials is formulated as solving a Sylvester-like matrix equation. By exploiting the structural properties of GMRFs, this matrix equation is solved columnwise in an analytical way. The proposed algorithm can be embedded into a wide range of proximal algorithms to solve LS regression problems including a convex penalty. Experiments carried out in the case of a constrained LS regression problem arising in a multichannel image processing application, provide evidence that an alternating direction method of multipliers performs quite efficiently in this context.
An unsupervised bayesian approach for the joint reconstruction and classification of cutaneous reflectance confocal microscopy images
Mar 04, 2017
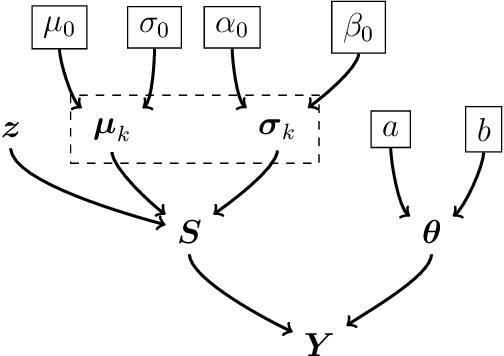
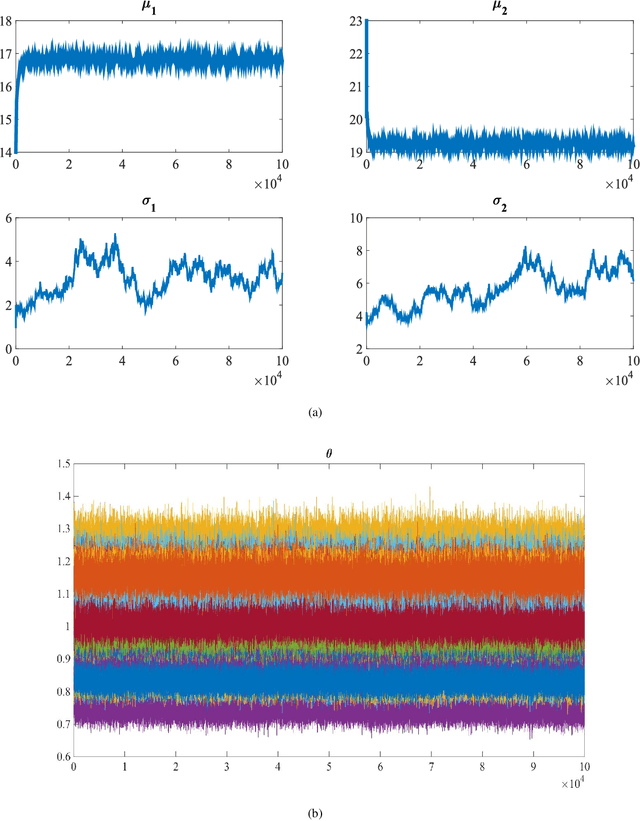
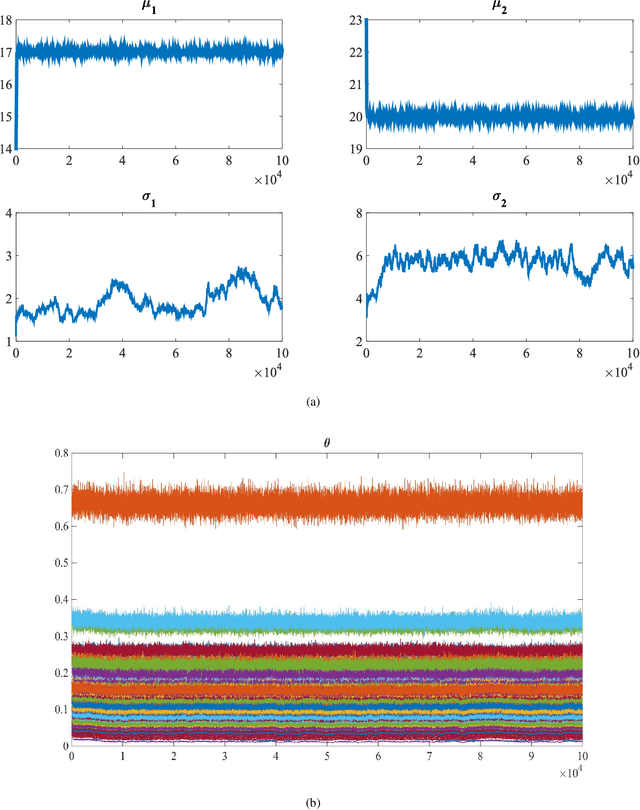
This paper studies a new Bayesian algorithm for the joint reconstruction and classification of reflectance confocal microscopy (RCM) images, with application to the identification of human skin lentigo. The proposed Bayesian approach takes advantage of the distribution of the multiplicative speckle noise affecting the true reflectivity of these images and of appropriate priors for the unknown model parameters. A Markov chain Monte Carlo (MCMC) algorithm is proposed to jointly estimate the model parameters and the image of true reflectivity while classifying images according to the distribution of their reflectivity. Precisely, a Metropolis-whitin-Gibbs sampler is investigated to sample the posterior distribution of the Bayesian model associated with RCM images and to build estimators of its parameters, including labels indicating the class of each RCM image. The resulting algorithm is applied to synthetic data and to real images from a clinical study containing healthy and lentigo patients.