 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper-Resolved Canopy Height Mapping from Sentinel-2 Time Series Using LiDAR HD Reference Data across Metropolitan France
Dec 12, 2025Fine-scale forest monitoring is essential for understanding canopy structure and its dynamics, which are key indicators of carbon stocks, biodiversity, and forest health. Deep learning is particularly effective for this task, as it integrates spectral, temporal, and spatial signals that jointly reflect the canopy structure. To address this need, we introduce THREASURE-Net, a novel end-to-end framework for Tree Height Regression And Super-Resolution. The model is trained on Sentinel-2 time series using reference height metrics derived from LiDAR HD data at multiple spatial resolutions over Metropolitan France to produce annual height maps. We evaluate three model variants, producing tree-height predictions at 2.5 m, 5 m, and 10 m resolution. THREASURE-Net does not rely on any pretrained model nor on reference very high resolution optical imagery to train its super-resolution module; instead, it learns solely from LiDAR-derived height information. Our approach outperforms existing state-of-the-art methods based on Sentinel data and is competitive with methods based on very high resolution imagery. It can be deployed to generate high-precision annual canopy-height maps, achieving mean absolute errors of 2.62 m, 2.72 m, and 2.88 m at 2.5 m, 5 m, and 10 m resolution, respectively. These results highlight the potential of THREASURE-Net for scalable and cost-effective structural monitoring of temperate forests using only freely available satellite data. The source code for THREASURE-Net is available at: https://github.com/Global-Earth-Observation/threasure-net.
Tree species classification at the pixel-level using deep learning and multispectral time series in an imbalanced context
Aug 05, 2024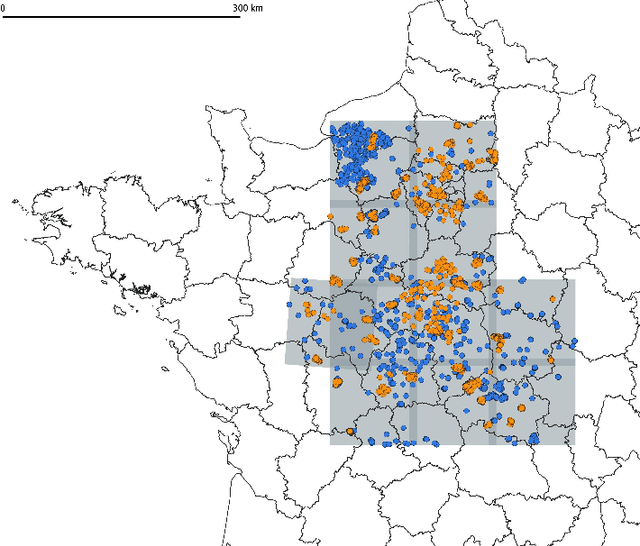
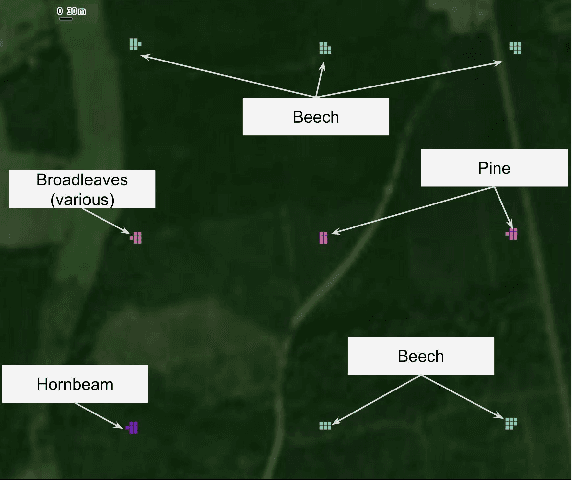
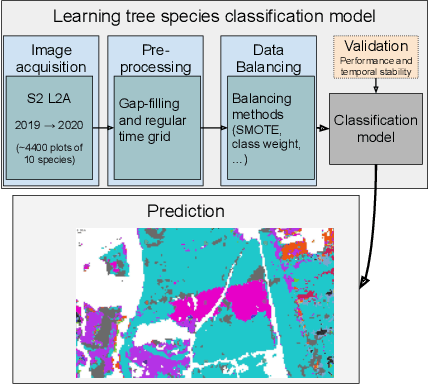
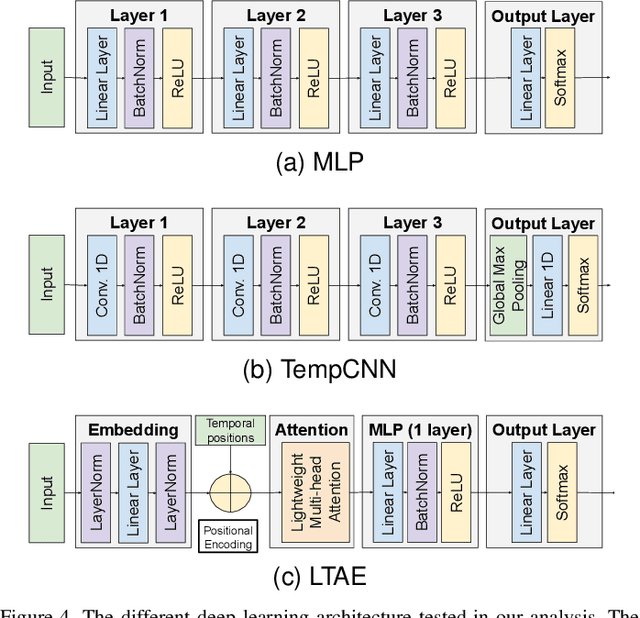
This paper investigates tree species classification using Sentinel-2 multispectral satellite image time-series. Despite their critical importance for many applications, such maps are often unavailable, outdated, or inaccurate for large areas. The interest of using remote sensing time series to produce these maps has been highlighted in many studies. However, many methods proposed in the literature still rely on a standard classification algorithm, usually the Random Forest (RF) algorithm with vegetation indices. This study shows that the use of deep learning models can lead to a significant improvement in classification results, especially in an imbalanced context where the RF algorithm tends to predict towards the majority class. In our use case in the center of France with 10 tree species, we obtain an overall accuracy (OA) around 95% and a F1-macro score around 80% using three different benchmark deep learning architectures. In contrast, using the RF algorithm yields an OA of 93% and an F1 of 60%, indicating that the minority classes are not classified with sufficient accuracy. Therefore, the proposed framework is a strong baseline that can be easily implemented in most scenarios, even with a limited amount of reference data. Our results highlight that standard multilayer perceptron can be competitive with batch normalization and a sufficient amount of parameters. Other architectures (convolutional or attention-based) can also achieve strong results when tuned properly. Furthermore, our results show that DL models are naturally robust to imbalanced data, although similar results can be obtained using dedicated techniques.
Estimation of forest height and biomass from open-access multi-sensor satellite imagery and GEDI Lidar data: high-resolution maps of metropolitan France
Oct 23, 2023
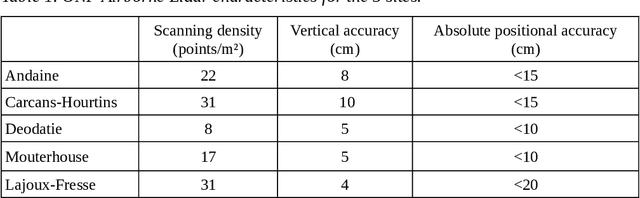
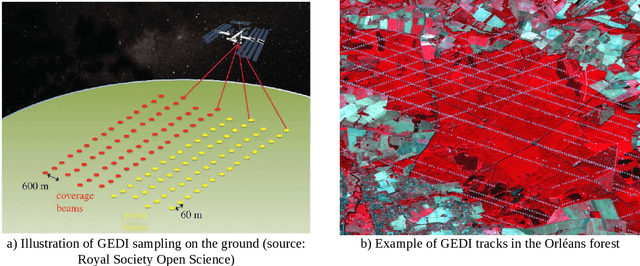

Mapping forest resources and carbon is important for improving forest management and meeting the objectives of storing carbon and preserving the environment. Spaceborne remote sensing approaches have considerable potential to support forest height monitoring by providing repeated observations at high spatial resolution over large areas. This study uses a machine learning approach that was previously developed to produce local maps of forest parameters (basal area, height, diameter, etc.). The aim of this paper is to present the extension of the approach to much larger scales such as the French national coverage. We used the GEDI Lidar mission as reference height data, and the satellite images from Sentinel-1, Sentinel-2 and ALOS-2 PALSA-2 to estimate forest height and produce a map of France for the year 2020. The height map is then derived into volume and aboveground biomass (AGB) using allometric equations. The validation of the height map with local maps from ALS data shows an accuracy close to the state of the art, with a mean absolute error (MAE) of 4.3 m. Validation on inventory plots representative of French forests shows an MAE of 3.7 m for the height. Estimates are slightly better for coniferous than for broadleaved forests. Volume and AGB maps derived from height shows MAEs of 75 tons/ha and 93 m${}^3$/ha respectively. The results aggregated by sylvo-ecoregion and forest types (owner and species) are further improved, with MAEs of 23 tons/ha and 30 m${}^3$/ha. The precision of these maps allows to monitor forests locally, as well as helping to analyze forest resources and carbon on a territorial scale or on specific types of forests by combining the maps with geolocated information (administrative area, species, type of owner, protected areas, environmental conditions, etc.). Height, volume and AGB maps produced in this study are made freely available.
A Robust and Flexible EM Algorithm for Mixtures of Elliptical Distributions with Missing Data
Jan 28, 2022
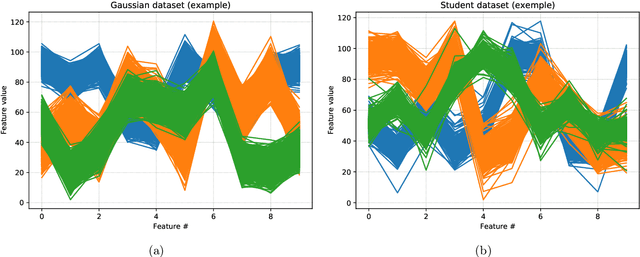
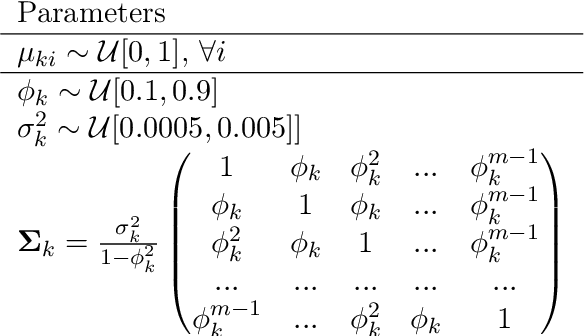
This paper tackles the problem of missing data imputation for noisy and non-Gaussian data. A classical imputation method, the Expectation Maximization (EM) algorithm for Gaussian mixture models, has shown interesting properties when compared to other popular approaches such as those based on k-nearest neighbors or on multiple imputations by chained equations. However, Gaussian mixture models are known to be not robust to heterogeneous data, which can lead to poor estimation performance when the data is contaminated by outliers or come from a non-Gaussian distributions. To overcome this issue, a new expectation maximization algorithm is investigated for mixtures of elliptical distributions with the nice property of handling potential missing data. The complete-data likelihood associated with mixtures of elliptical distributions is well adapted to the EM framework thanks to its conditional distribution, which is shown to be a Student distribution. Experimental results on synthetic data demonstrate that the proposed algorithm is robust to outliers and can be used with non-Gaussian data. Furthermore, experiments conducted on real-world datasets show that this algorithm is very competitive when compared to other classical imputation methods.
Reconstruction of Sentinel-2 Time Series Using Robust Gaussian Mixture Models -- Application to the Detection of Anomalous Crop Development in wheat and rapeseed crops
Oct 22, 2021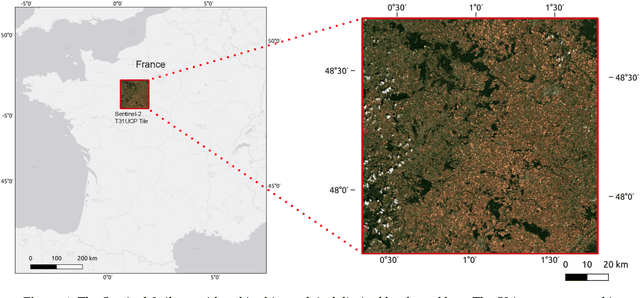
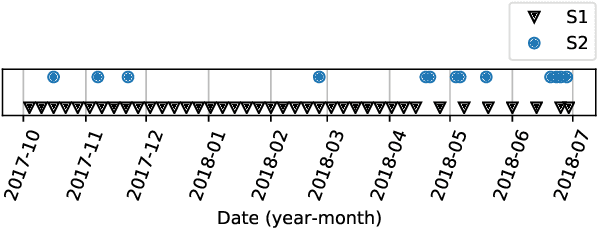
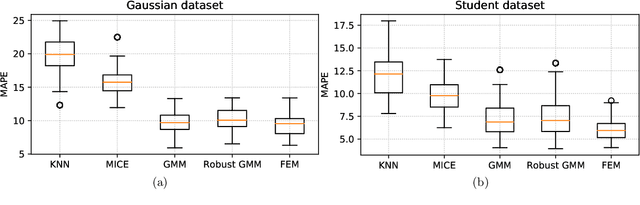
Missing data is a recurrent problem in remote sensing, mainly due to cloud coverage for multispectral images and acquisition problems. This can be a critical issue for crop monitoring, especially for applications relying on machine learning techniques, which generally assume that the feature matrix does not have missing values. This paper proposes a Gaussian Mixture Model (GMM) for the reconstruction of parcel-level features extracted from multispectral images. A robust version of the GMM is also investigated, since datasets can be contaminated by inaccurate samples or features (e.g., wrong crop type reported, inaccurate boundaries, undetected clouds, etc). Additional features extracted from Synthetic Aperture Radar (SAR) images using Sentinel-1 data are also used to provide complementary information and improve the imputations. The robust GMM investigated in this work assigns reduced weights to the outliers during the estimation of the GMM parameters, which improves the final reconstruction. These weights are computed at each step of an Expectation-Maximization (EM) algorithm by using outlier scores provided by the isolation forest algorithm. Experimental validation is conducted on rapeseed and wheat parcels located in the Beauce region (France). Overall, we show that the GMM imputation method outperforms other reconstruction strategies. A mean absolute error (MAE) of 0.013 (resp. 0.019) is obtained for the imputation of the median Normalized Difference Index (NDVI) of the rapeseed (resp. wheat) parcels. Other indicators (e.g., Normalized Difference Water Index) and statistics (for instance the interquartile range, which captures heterogeneity among the parcel indicator) are reconstructed at the same time with good accuracy. In a dataset contaminated by irrelevant samples, using the robust GMM is recommended since the standard GMM imputation can lead to inaccurate imputed values.
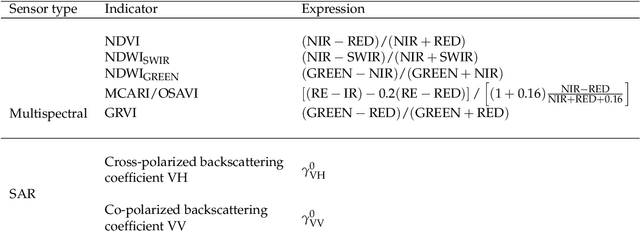
Unsupervised crop anomaly detection at the parcel-level using optical and SAR images: application to wheat and rapeseed crops
Apr 17, 2020
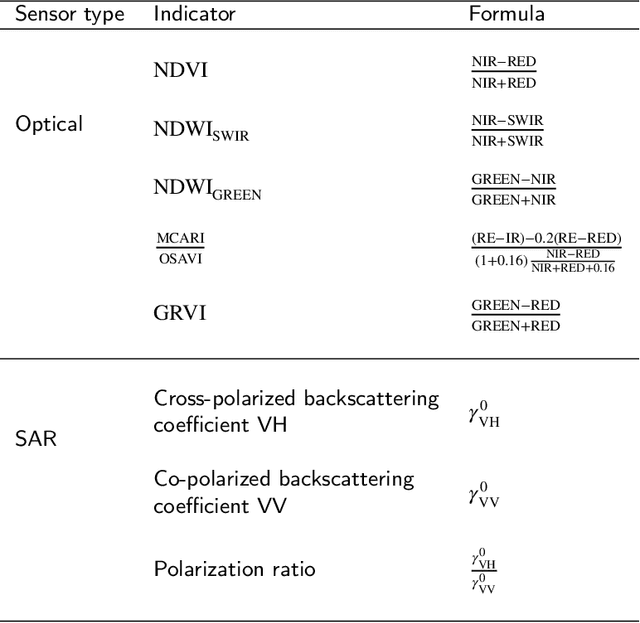

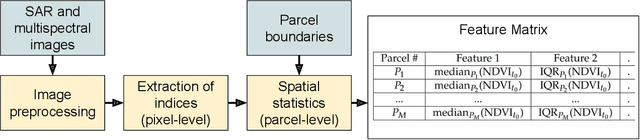
This paper proposes a generic approach for crop anomaly detection at the parcel-level based on unsupervised point anomaly detection techniques. The input data is derived from synthetic aperture radar (SAR) and optical images acquired using Sentinel-1 and Sentinel-2 satellites. The proposed strategy consists of four sequential steps: acquisition and preprocessing of optical and SAR images, extraction of optical and SAR indicators, computation of zonal statistics at the parcel-level and point anomaly detection. This paper analyzes different factors that can affect the results of anomaly detection such as the considered features and the anomaly detection algorithm used. The proposed procedure is validated on two crop types in Beauce (France), namely, rapeseed and wheat crops. Two different parcel delineation databases are considered to validate the robustness of the strategy to changes in parcel boundaries.