 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Diffusion: An Alternate Approach to Blind Deconvolution
Dec 04, 2023Blind deconvolution problems are severely ill-posed because neither the underlying signal nor the forward operator are not known exactly. Conventionally, these problems are solved by alternating between estimation of the image and kernel while keeping the other fixed. In this paper, we show that this framework is flawed because of its tendency to get trapped in local minima and, instead, suggest the use of a kernel estimation strategy with a non-blind solver. This framework is employed by a diffusion method which is trained to sample the blur kernel from the conditional distribution with guidance from a pre-trained non-blind solver. The proposed diffusion method leads to state-of-the-art results on both synthetic and real blur datasets.
The Secrets of Non-Blind Poisson Deconvolution
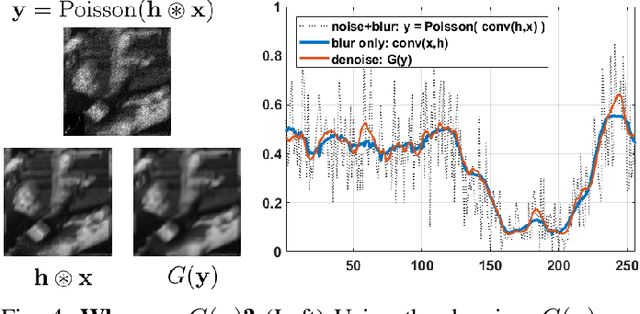
Sep 06, 2023Non-blind image deconvolution has been studied for several decades but most of the existing work focuses on blur instead of noise. In photon-limited conditions, however, the excessive amount of shot noise makes traditional deconvolution algorithms fail. In searching for reasons why these methods fail, we present a systematic analysis of the Poisson non-blind deconvolution algorithms reported in the literature, covering both classical and deep learning methods. We compile a list of five "secrets" highlighting the do's and don'ts when designing algorithms. Based on this analysis, we build a proof-of-concept method by combining the five secrets. We find that the new method performs on par with some of the latest methods while outperforming some older ones.
Structured Kernel Estimation for Photon-Limited Deconvolution
Mar 06, 2023



Images taken in a low light condition with the presence of camera shake suffer from motion blur and photon shot noise. While state-of-the-art image restoration networks show promising results, they are largely limited to well-illuminated scenes and their performance drops significantly when photon shot noise is strong. In this paper, we propose a new blur estimation technique customized for photon-limited conditions. The proposed method employs a gradient-based backpropagation method to estimate the blur kernel. By modeling the blur kernel using a low-dimensional representation with the key points on the motion trajectory, we significantly reduce the search space and improve the regularity of the kernel estimation problem. When plugged into an iterative framework, our novel low-dimensional representation provides improved kernel estimates and hence significantly better deconvolution performance when compared to end-to-end trained neural networks. The source code and pretrained models are available at \url{https://github.com/sanghviyashiitb/structured-kernel-cvpr23}
Photon-Limited Blind Deconvolution using Unsupervised Iterative Kernel Estimation
Aug 02, 2022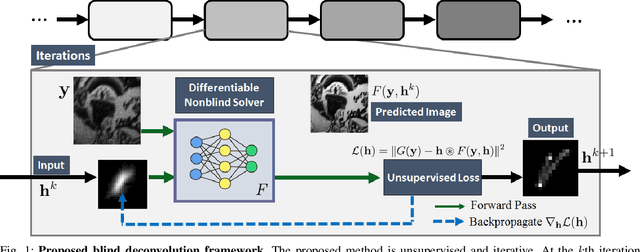
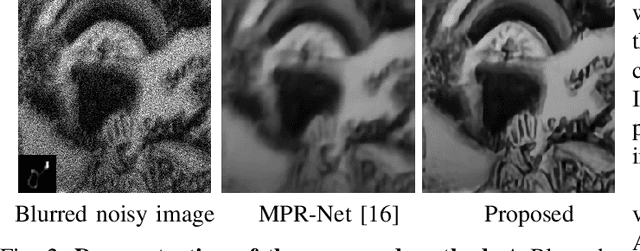
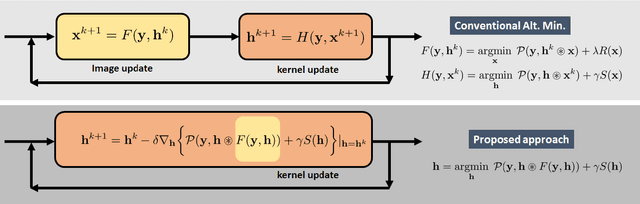
Blind deconvolution in low-light is one of the more challenging problems in image restoration because of the photon shot noise. However, existing algorithms -- both classical and deep-learning based -- are not designed for this condition. When the shot noise is strong, conventional deconvolution methods fail because (1) the presence of noise makes the estimation of the blur kernel difficult; (2) generic deep-restoration models rarely model the forward process explicitly; (3) there are currently no iterative strategies to incorporate a non-blind solver in a kernel estimation stage. This paper addresses these challenges by presenting an unsupervised blind deconvolution method. At the core of this method is a reformulation of the general blind deconvolution framework from the conventional image-kernel alternating minimization to a purely kernel-based minimization. This kernel-based minimization leads to a new iterative scheme that backpropagates an unsupervised loss through a pre-trained non-blind solver to update the blur kernel. Experimental results show that the proposed framework achieves superior results than state-of-the-art blind deconvolution algorithms in low-light conditions.
Graph-Based Depth Denoising & Dequantization for Point Cloud Enhancement
Nov 09, 2021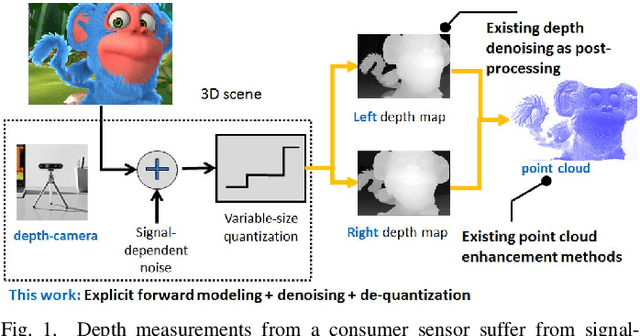
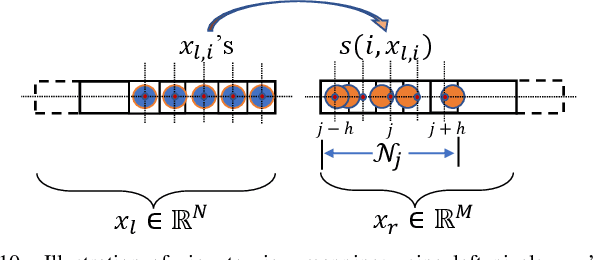
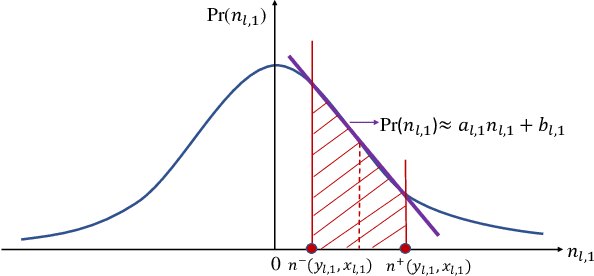
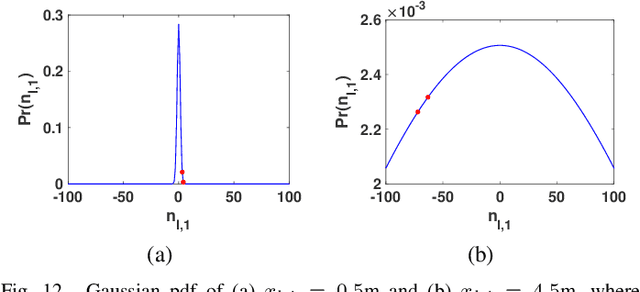
A 3D point cloud is typically constructed from depth measurements acquired by sensors at one or more viewpoints. The measurements suffer from both quantization and noise corruption. To improve quality, previous works denoise a point cloud \textit{a posteriori} after projecting the imperfect depth data onto 3D space. Instead, we enhance depth measurements directly on the sensed images \textit{a priori}, before synthesizing a 3D point cloud. By enhancing near the physical sensing process, we tailor our optimization to our depth formation model before subsequent processing steps that obscure measurement errors. Specifically, we model depth formation as a combined process of signal-dependent noise addition and non-uniform log-based quantization. The designed model is validated (with parameters fitted) using collected empirical data from an actual depth sensor. To enhance each pixel row in a depth image, we first encode intra-view similarities between available row pixels as edge weights via feature graph learning. We next establish inter-view similarities with another rectified depth image via viewpoint mapping and sparse linear interpolation. This leads to a maximum a posteriori (MAP) graph filtering objective that is convex and differentiable. We optimize the objective efficiently using accelerated gradient descent (AGD), where the optimal step size is approximated via Gershgorin circle theorem (GCT). Experiments show that our method significantly outperformed recent point cloud denoising schemes and state-of-the-art image denoising schemes, in two established point cloud quality metrics.
Photon Limited Non-Blind Deblurring Using Algorithm Unrolling
Oct 29, 2021


Image deblurring in photon-limited conditions is ubiquitous in a variety of low-light applications such as photography, microscopy and astronomy. However, the presence of photon shot noise due to low-illumination and/or short exposure makes the deblurring task substantially more challenging than the conventional deblurring problems. In this paper we present an algorithm unrolling approach for the photon-limited deblurring problem by unrolling a Plug-and-Play algorithm for a fixed number of iterations. By introducing a three-operator splitting formation of the Plug-and-Play framework, we obtain a series of differentiable steps which allows the fixed iteration unrolled network to be trained end-to-end. The proposed algorithm demonstrates significantly better image recovery compared to existing state-of-the-art deblurring approaches. We also present a new photon-limited deblurring dataset for evaluating the performance of algorithms.