 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
M2-omni: Advancing Omni-MLLM for Comprehensive Modality Support with Competitive Performance
Feb 26, 2025We present M2-omni, a cutting-edge, open-source omni-MLLM that achieves competitive performance to GPT-4o. M2-omni employs a unified multimodal sequence modeling framework, which empowers Large Language Models(LLMs) to acquire comprehensive cross-modal understanding and generation capabilities. Specifically, M2-omni can process arbitrary combinations of audio, video, image, and text modalities as input, generating multimodal sequences interleaving with audio, image, or text outputs, thereby enabling an advanced and interactive real-time experience. The training of such an omni-MLLM is challenged by significant disparities in data quantity and convergence rates across modalities. To address these challenges, we propose a step balance strategy during pre-training to handle the quantity disparities in modality-specific data. Additionally, a dynamically adaptive balance strategy is introduced during the instruction tuning stage to synchronize the modality-wise training progress, ensuring optimal convergence. Notably, we prioritize preserving strong performance on pure text tasks to maintain the robustness of M2-omni's language understanding capability throughout the training process. To our best knowledge, M2-omni is currently a very competitive open-source model to GPT-4o, characterized by its comprehensive modality and task support, as well as its exceptional performance. We expect M2-omni will advance the development of omni-MLLMs, thus facilitating future research in this domain.
M2-RAAP: A Multi-Modal Recipe for Advancing Adaptation-based Pre-training towards Effective and Efficient Zero-shot Video-text Retrieval
Jan 31, 2024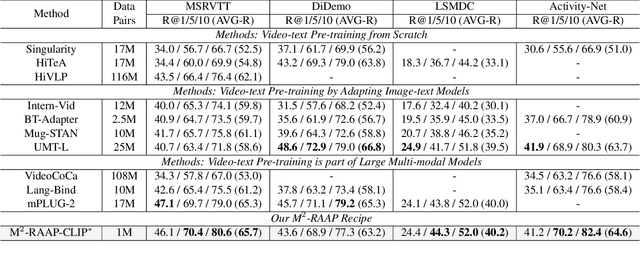

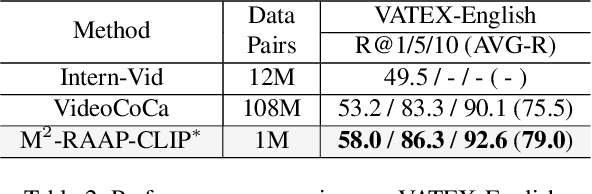
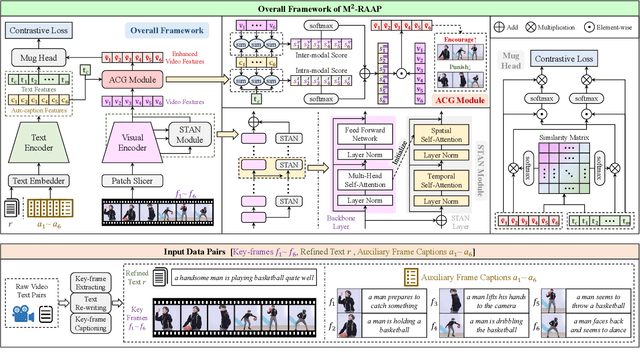
We present a Multi-Modal Recipe for Advancing Adaptation-based Pre-training towards effective and efficient zero-shot video-text retrieval, dubbed M2-RAAP. Upon popular image-text models like CLIP, most current adaptation-based video-text pre-training methods are confronted by three major issues, i.e., noisy data corpus, time-consuming pre-training, and limited performance gain. Towards this end, we conduct a comprehensive study including four critical steps in video-text pre-training. Specifically, we investigate 1) data filtering and refinement, 2) video input type selection, 3) temporal modeling, and 4) video feature enhancement. We then summarize this empirical study into the M2-RAAP recipe, where our technical contributions lie in 1) the data filtering and text re-writing pipeline resulting in 1M high-quality bilingual video-text pairs, 2) the replacement of video inputs with key-frames to accelerate pre-training, and 3) the Auxiliary-Caption-Guided (ACG) strategy to enhance video features. We conduct extensive experiments by adapting three image-text foundation models on two refined video-text datasets from different languages, validating the robustness and reproducibility of M2-RAAP for adaptation-based pre-training. Results demonstrate that M2-RAAP yields superior performance with significantly reduced data (-90%) and time consumption (-95%), establishing a new SOTA on four English zero-shot retrieval datasets and two Chinese ones. We are preparing our refined bilingual data annotations and codebase, which will be available at https://github.com/alipay/Ant-Multi-Modal-Framework/tree/main/prj/M2_RAAP.
Arch-Net: Model Distillation for Architecture Agnostic Model Deployment
Nov 01, 2021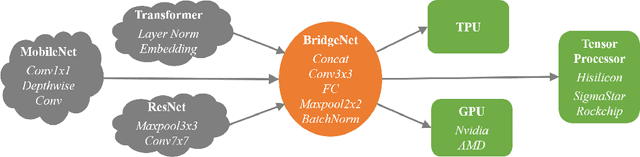
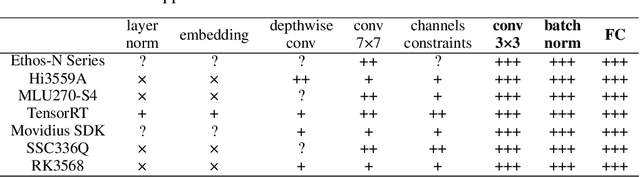
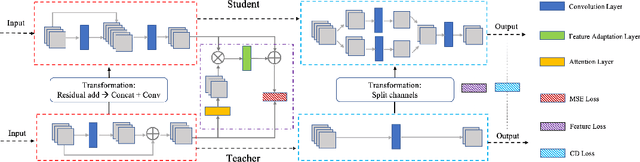

Vast requirement of computation power of Deep Neural Networks is a major hurdle to their real world applications. Many recent Application Specific Integrated Circuit (ASIC) chips feature dedicated hardware support for Neural Network Acceleration. However, as ASICs take multiple years to develop, they are inevitably out-paced by the latest development in Neural Architecture Research. For example, Transformer Networks do not have native support on many popular chips, and hence are difficult to deploy. In this paper, we propose Arch-Net, a family of Neural Networks made up of only operators efficiently supported across most architectures of ASICs. When a Arch-Net is produced, less common network constructs, like Layer Normalization and Embedding Layers, are eliminated in a progressive manner through label-free Blockwise Model Distillation, while performing sub-eight bit quantization at the same time to maximize performance. Empirical results on machine translation and image classification tasks confirm that we can transform latest developed Neural Architectures into fast running and as-accurate Arch-Net, ready for deployment on multiple mass-produced ASIC chips. The code will be available at https://github.com/megvii-research/Arch-Net.