 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArch-Net: Model Distillation for Architecture Agnostic Model Deployment
Paper and Code
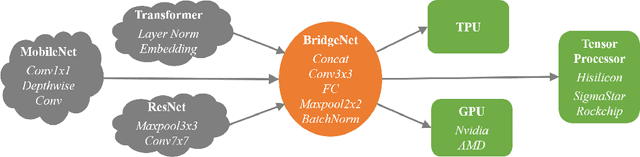
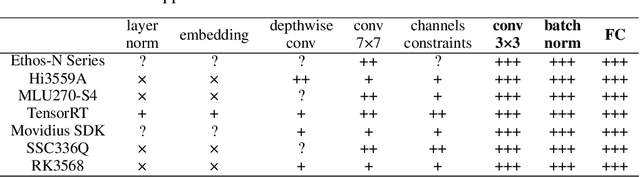
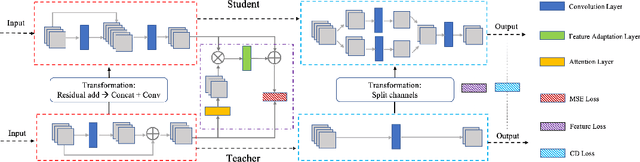

Vast requirement of computation power of Deep Neural Networks is a major hurdle to their real world applications. Many recent Application Specific Integrated Circuit (ASIC) chips feature dedicated hardware support for Neural Network Acceleration. However, as ASICs take multiple years to develop, they are inevitably out-paced by the latest development in Neural Architecture Research. For example, Transformer Networks do not have native support on many popular chips, and hence are difficult to deploy. In this paper, we propose Arch-Net, a family of Neural Networks made up of only operators efficiently supported across most architectures of ASICs. When a Arch-Net is produced, less common network constructs, like Layer Normalization and Embedding Layers, are eliminated in a progressive manner through label-free Blockwise Model Distillation, while performing sub-eight bit quantization at the same time to maximize performance. Empirical results on machine translation and image classification tasks confirm that we can transform latest developed Neural Architectures into fast running and as-accurate Arch-Net, ready for deployment on multiple mass-produced ASIC chips. The code will be available at https://github.com/megvii-research/Arch-Net.