 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAESTRO: Multi-Agent Evaluation Suite for Testing, Reliability, and Observability
Jan 01, 2026We present MAESTRO, an evaluation suite for the testing, reliability, and observability of LLM-based MAS. MAESTRO standardizes MAS configuration and execution through a unified interface, supports integrating both native and third-party MAS via a repository of examples and lightweight adapters, and exports framework-agnostic execution traces together with system-level signals (e.g., latency, cost, and failures). We instantiate MAESTRO with 12 representative MAS spanning popular agentic frameworks and interaction patterns, and conduct controlled experiments across repeated runs, backend models, and tool configurations. Our case studies show that MAS executions can be structurally stable yet temporally variable, leading to substantial run-to-run variance in performance and reliability. We further find that MAS architecture is the dominant driver of resource profiles, reproducibility, and cost-latency-accuracy trade-off, often outweighing changes in backend models or tool settings. Overall, MAESTRO enables systematic evaluation and provides empirical guidance for designing and optimizing agentic systems.
MATHGLANCE: Multimodal Large Language Models Do Not Know Where to Look in Mathematical Diagrams
Mar 26, 2025Diagrams serve as a fundamental form of visual language, representing complex concepts and their inter-relationships through structured symbols, shapes, and spatial arrangements. Unlike natural images, their inherently symbolic and abstract nature poses significant challenges for Multimodal Large Language Models (MLLMs). However, current benchmarks conflate perceptual and reasoning tasks, making it difficult to assess whether MLLMs genuinely understand mathematical diagrams beyond superficial pattern recognition. To address this gap, we introduce MATHGLANCE, a benchmark specifically designed to isolate and evaluate mathematical perception in MLLMs. MATHGLANCE comprises 1.2K images and 1.6K carefully curated questions spanning four perception tasks: shape classification, object counting, relationship identification, and object grounding, covering diverse domains including plane geometry, solid geometry, and graphical representations. Our evaluation of MLLMs reveals that their ability to understand diagrams is notably limited, particularly in fine-grained grounding tasks. In response, we construct GeoPeP, a perception-oriented dataset of 200K structured geometry image-text pairs explicitly annotated with geometric primitives and precise spatial relationships. Training MLLM on GeoPeP leads to significant gains in perceptual accuracy, which in turn substantially improves mathematical reasoning. Our benchmark and dataset establish critical standards for evaluating and advancing multimodal mathematical understanding, providing valuable resources and insights to foster future MLLM research.
Open Eyes, Then Reason: Fine-grained Visual Mathematical Understanding in MLLMs
Jan 11, 2025



Current multimodal large language models (MLLMs) often underperform on mathematical problem-solving tasks that require fine-grained visual understanding. The limitation is largely attributable to inadequate perception of geometric primitives during image-level contrastive pre-training (e.g., CLIP). While recent efforts to improve math MLLMs have focused on scaling up mathematical visual instruction datasets and employing stronger LLM backbones, they often overlook persistent errors in visual recognition. In this paper, we systematically evaluate the visual grounding capabilities of state-of-the-art MLLMs and reveal a significant negative correlation between visual grounding accuracy and problem-solving performance, underscoring the critical role of fine-grained visual understanding. Notably, advanced models like GPT-4o exhibit a 70% error rate when identifying geometric entities, highlighting that this remains a key bottleneck in visual mathematical reasoning. To address this, we propose a novel approach, SVE-Math (Selective Vision-Enhanced Mathematical MLLM), featuring a geometric-grounded vision encoder and a feature router that dynamically adjusts the contribution of hierarchical visual feature maps. Our model recognizes accurate visual primitives and generates precise visual prompts tailored to the language model's reasoning needs. In experiments, SVE-Math-Qwen2.5-7B outperforms other 7B models by 15% on MathVerse and is compatible with GPT-4V on MathVista. Despite being trained on smaller datasets, SVE-Math-7B achieves competitive performance on GeoQA, rivaling models trained on significantly larger datasets. Our findings emphasize the importance of incorporating fine-grained visual understanding into MLLMs and provide a promising direction for future research.
DeTeCtive: Detecting AI-generated Text via Multi-Level Contrastive Learning
Oct 28, 2024



Current techniques for detecting AI-generated text are largely confined to manual feature crafting and supervised binary classification paradigms. These methodologies typically lead to performance bottlenecks and unsatisfactory generalizability. Consequently, these methods are often inapplicable for out-of-distribution (OOD) data and newly emerged large language models (LLMs). In this paper, we revisit the task of AI-generated text detection. We argue that the key to accomplishing this task lies in distinguishing writing styles of different authors, rather than simply classifying the text into human-written or AI-generated text. To this end, we propose DeTeCtive, a multi-task auxiliary, multi-level contrastive learning framework. DeTeCtive is designed to facilitate the learning of distinct writing styles, combined with a dense information retrieval pipeline for AI-generated text detection. Our method is compatible with a range of text encoders. Extensive experiments demonstrate that our method enhances the ability of various text encoders in detecting AI-generated text across multiple benchmarks and achieves state-of-the-art results. Notably, in OOD zero-shot evaluation, our method outperforms existing approaches by a large margin. Moreover, we find our method boasts a Training-Free Incremental Adaptation (TFIA) capability towards OOD data, further enhancing its efficacy in OOD detection scenarios. We will open-source our code and models in hopes that our work will spark new thoughts in the field of AI-generated text detection, ensuring safe application of LLMs and enhancing compliance. Our code is available at https://github.com/heyongxin233/DeTeCtive.
PACE: marrying generalization in PArameter-efficient fine-tuning with Consistency rEgularization
Sep 25, 2024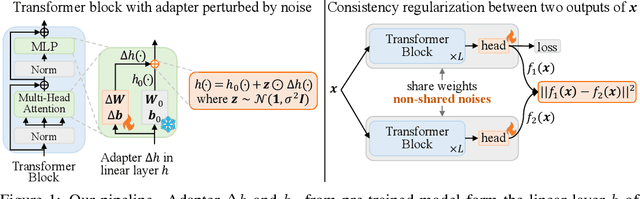
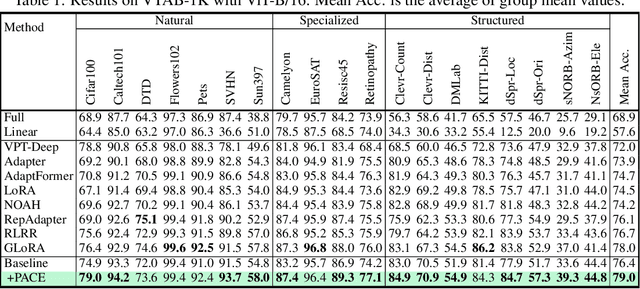
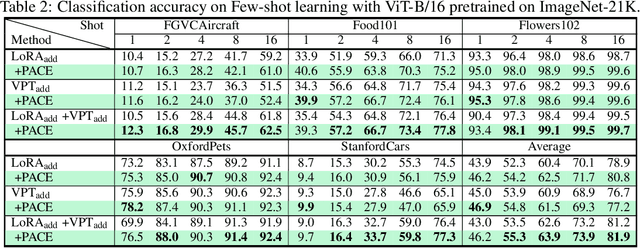
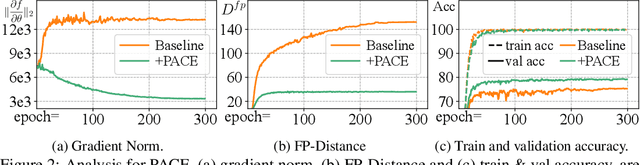
Parameter-Efficient Fine-Tuning (PEFT) effectively adapts pre-trained vision transformers to downstream tasks. However, the optimization for tasks performance often comes at the cost of generalizability in fine-tuned models. To address this issue, we theoretically connect smaller weight gradient norms during training and larger datasets to the improved model generalization. Motivated by this connection, we propose reducing gradient norms for enhanced generalization and aligning fine-tuned model with the pre-trained counterpart to retain knowledge from large-scale pre-training data. Yet, naive alignment does not guarantee gradient reduction and can potentially cause gradient explosion, complicating efforts to manage gradients. To address such issues, we propose PACE, marrying generalization of PArameter-efficient fine-tuning with Consistency rEgularization. We perturb features learned from the adapter with the multiplicative noise and ensure the fine-tuned model remains consistent for same sample under different perturbations. Theoretical analysis shows that PACE not only implicitly regularizes gradients for enhanced generalization, but also implicitly aligns the fine-tuned and pre-trained models to retain knowledge. Experimental evidence supports our theories. PACE outperforms existing PEFT methods in four visual adaptation tasks: VTAB-1k, FGVC, few-shot learning and domain adaptation. Code will be available at https://github.com/MaxwellYaoNi/PACE
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
Jun 05, 2024



In this paper, we present a light-weight detection transformer, LW-DETR, which outperforms YOLOs for real-time object detection. The architecture is a simple stack of a ViT encoder, a projector, and a shallow DETR decoder. Our approach leverages recent advanced techniques, such as training-effective techniques, e.g., improved loss and pretraining, and interleaved window and global attentions for reducing the ViT encoder complexity. We improve the ViT encoder by aggregating multi-level feature maps, and the intermediate and final feature maps in the ViT encoder, forming richer feature maps, and introduce window-major feature map organization for improving the efficiency of interleaved attention computation. Experimental results demonstrate that the proposed approach is superior over existing real-time detectors, e.g., YOLO and its variants, on COCO and other benchmark datasets. Code and models are available at (https://github.com/Atten4Vis/LW-DETR).
VRP-SAM: SAM with Visual Reference Prompt
Feb 27, 2024



In this paper, we propose a novel Visual Reference Prompt (VRP) encoder that empowers the Segment Anything Model (SAM) to utilize annotated reference images as prompts for segmentation, creating the VRP-SAM model. In essence, VRP-SAM can utilize annotated reference images to comprehend specific objects and perform segmentation of specific objects in target image. It is note that the VRP encoder can support a variety of annotation formats for reference images, including \textbf{point}, \textbf{box}, \textbf{scribble}, and \textbf{mask}. VRP-SAM achieves a breakthrough within the SAM framework by extending its versatility and applicability while preserving SAM's inherent strengths, thus enhancing user-friendliness. To enhance the generalization ability of VRP-SAM, the VRP encoder adopts a meta-learning strategy. To validate the effectiveness of VRP-SAM, we conducted extensive empirical studies on the Pascal and COCO datasets. Remarkably, VRP-SAM achieved state-of-the-art performance in visual reference segmentation with minimal learnable parameters. Furthermore, VRP-SAM demonstrates strong generalization capabilities, allowing it to perform segmentation of unseen objects and enabling cross-domain segmentation.
Semantic-Aware Autoregressive Image Modeling for Visual Representation Learning
Dec 16, 2023The development of autoregressive modeling (AM) in computer vision lags behind natural language processing (NLP) in self-supervised pre-training. This is mainly caused by the challenge that images are not sequential signals and lack a natural order when applying autoregressive modeling. In this study, inspired by human beings' way of grasping an image, i.e., focusing on the main object first, we present a semantic-aware autoregressive image modeling (SemAIM) method to tackle this challenge. The key insight of SemAIM is to autoregressive model images from the semantic patches to the less semantic patches. To this end, we first calculate a semantic-aware permutation of patches according to their feature similarities and then perform the autoregression procedure based on the permutation. In addition, considering that the raw pixels of patches are low-level signals and are not ideal prediction targets for learning high-level semantic representation, we also explore utilizing the patch features as the prediction targets. Extensive experiments are conducted on a broad range of downstream tasks, including image classification, object detection, and instance/semantic segmentation, to evaluate the performance of SemAIM. The results demonstrate SemAIM achieves state-of-the-art performance compared with other self-supervised methods. Specifically, with ViT-B, SemAIM achieves 84.1% top-1 accuracy for fine-tuning on ImageNet, 51.3% AP and 45.4% AP for object detection and instance segmentation on COCO, which outperforms the vanilla MAE by 0.5%, 1.0%, and 0.5%, respectively.
Multi-Mode Online Knowledge Distillation for Self-Supervised Visual Representation Learning
Apr 13, 2023
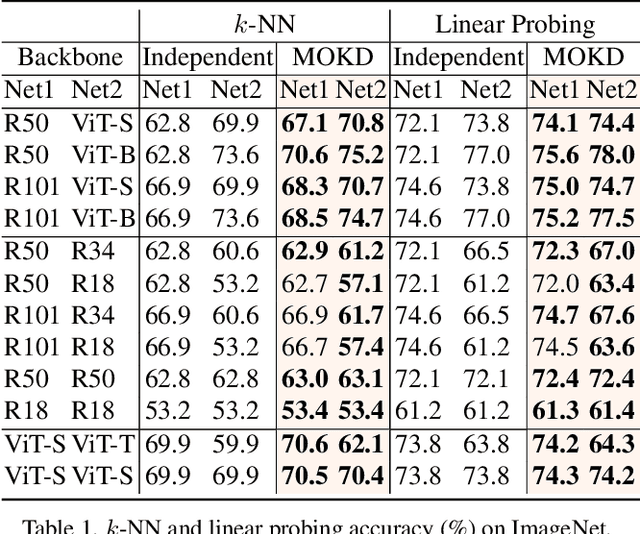

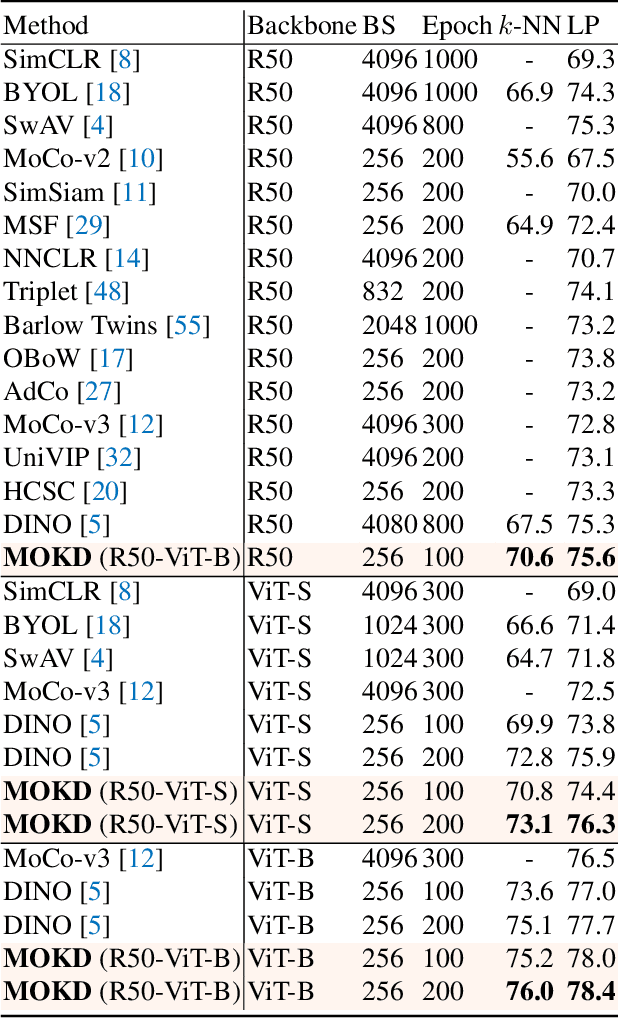
Self-supervised learning (SSL) has made remarkable progress in visual representation learning. Some studies combine SSL with knowledge distillation (SSL-KD) to boost the representation learning performance of small models. In this study, we propose a Multi-mode Online Knowledge Distillation method (MOKD) to boost self-supervised visual representation learning. Different from existing SSL-KD methods that transfer knowledge from a static pre-trained teacher to a student, in MOKD, two different models learn collaboratively in a self-supervised manner. Specifically, MOKD consists of two distillation modes: self-distillation and cross-distillation modes. Among them, self-distillation performs self-supervised learning for each model independently, while cross-distillation realizes knowledge interaction between different models. In cross-distillation, a cross-attention feature search strategy is proposed to enhance the semantic feature alignment between different models. As a result, the two models can absorb knowledge from each other to boost their representation learning performance. Extensive experimental results on different backbones and datasets demonstrate that two heterogeneous models can benefit from MOKD and outperform their independently trained baseline. In addition, MOKD also outperforms existing SSL-KD methods for both the student and teacher models.
Teacher-Student Knowledge Distillation for Radar Perception on Embedded Accelerators
Mar 14, 2023Many radar signal processing methodologies are being developed for critical road safety perception tasks. Unfortunately, these signal processing algorithms are often poorly suited to run on embedded hardware accelerators used in automobiles. Conversely, end-to-end machine learning (ML) approaches better exploit the performance gains brought by specialized accelerators. In this paper, we propose a teacher-student knowledge distillation approach for low-level radar perception tasks. We utilize a hybrid model for stationary object detection as a teacher to train an end-to-end ML student model. The student can efficiently harness embedded compute for real-time deployment. We demonstrate that the proposed student model runs at speeds 100x faster than the teacher model.