 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACE: marrying generalization in PArameter-efficient fine-tuning with Consistency rEgularization
Paper and Code
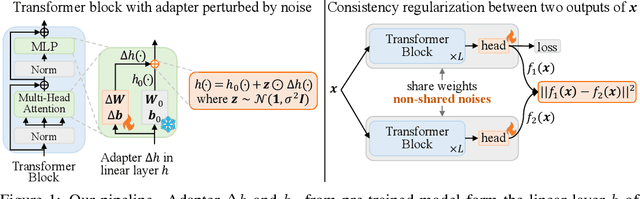
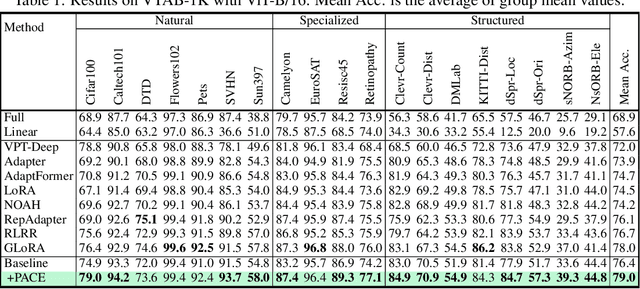
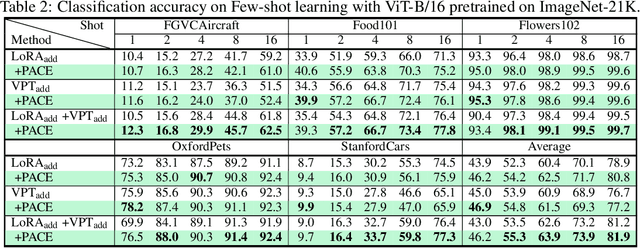
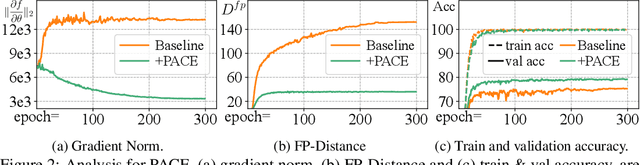
Parameter-Efficient Fine-Tuning (PEFT) effectively adapts pre-trained vision transformers to downstream tasks. However, the optimization for tasks performance often comes at the cost of generalizability in fine-tuned models. To address this issue, we theoretically connect smaller weight gradient norms during training and larger datasets to the improved model generalization. Motivated by this connection, we propose reducing gradient norms for enhanced generalization and aligning fine-tuned model with the pre-trained counterpart to retain knowledge from large-scale pre-training data. Yet, naive alignment does not guarantee gradient reduction and can potentially cause gradient explosion, complicating efforts to manage gradients. To address such issues, we propose PACE, marrying generalization of PArameter-efficient fine-tuning with Consistency rEgularization. We perturb features learned from the adapter with the multiplicative noise and ensure the fine-tuned model remains consistent for same sample under different perturbations. Theoretical analysis shows that PACE not only implicitly regularizes gradients for enhanced generalization, but also implicitly aligns the fine-tuned and pre-trained models to retain knowledge. Experimental evidence supports our theories. PACE outperforms existing PEFT methods in four visual adaptation tasks: VTAB-1k, FGVC, few-shot learning and domain adaptation. Code will be available at https://github.com/MaxwellYaoNi/PACE