 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Consistency Regularization for Improved Subject-Driven Image Synthesis
Jun 06, 2025Fine-tuning Stable Diffusion enables subject-driven image synthesis by adapting the model to generate images containing specific subjects. However, existing fine-tuning methods suffer from two key issues: underfitting, where the model fails to reliably capture subject identity, and overfitting, where it memorizes the subject image and reduces background diversity. To address these challenges, we propose two auxiliary consistency losses for diffusion fine-tuning. First, a prior consistency regularization loss ensures that the predicted diffusion noise for prior (non-subject) images remains consistent with that of the pretrained model, improving fidelity. Second, a subject consistency regularization loss enhances the fine-tuned model's robustness to multiplicative noise modulated latent code, helping to preserve subject identity while improving diversity. Our experimental results demonstrate that incorporating these losses into fine-tuning not only preserves subject identity but also enhances image diversity, outperforming DreamBooth in terms of CLIP scores, background variation, and overall visual quality.
PACE: marrying generalization in PArameter-efficient fine-tuning with Consistency rEgularization
Sep 25, 2024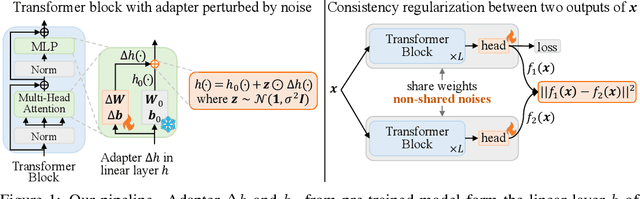
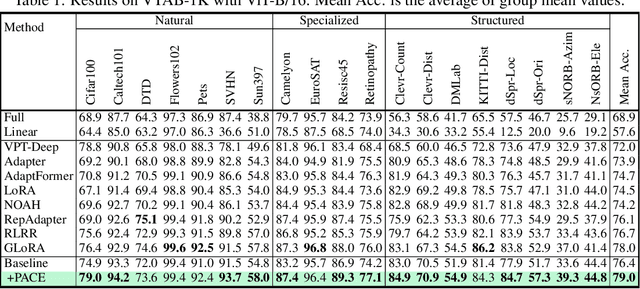
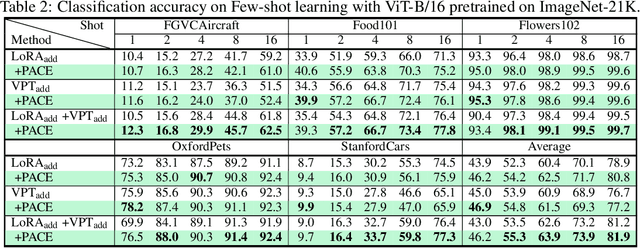
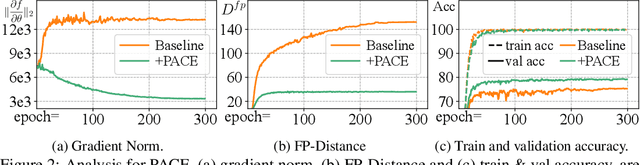
Parameter-Efficient Fine-Tuning (PEFT) effectively adapts pre-trained vision transformers to downstream tasks. However, the optimization for tasks performance often comes at the cost of generalizability in fine-tuned models. To address this issue, we theoretically connect smaller weight gradient norms during training and larger datasets to the improved model generalization. Motivated by this connection, we propose reducing gradient norms for enhanced generalization and aligning fine-tuned model with the pre-trained counterpart to retain knowledge from large-scale pre-training data. Yet, naive alignment does not guarantee gradient reduction and can potentially cause gradient explosion, complicating efforts to manage gradients. To address such issues, we propose PACE, marrying generalization of PArameter-efficient fine-tuning with Consistency rEgularization. We perturb features learned from the adapter with the multiplicative noise and ensure the fine-tuned model remains consistent for same sample under different perturbations. Theoretical analysis shows that PACE not only implicitly regularizes gradients for enhanced generalization, but also implicitly aligns the fine-tuned and pre-trained models to retain knowledge. Experimental evidence supports our theories. PACE outperforms existing PEFT methods in four visual adaptation tasks: VTAB-1k, FGVC, few-shot learning and domain adaptation. Code will be available at https://github.com/MaxwellYaoNi/PACE
CHAIN: Enhancing Generalization in Data-Efficient GANs via lipsCHitz continuity constrAIned Normalization
Apr 07, 2024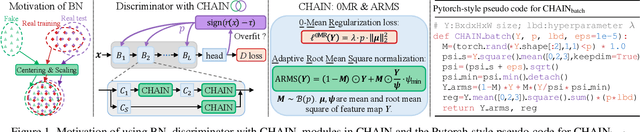
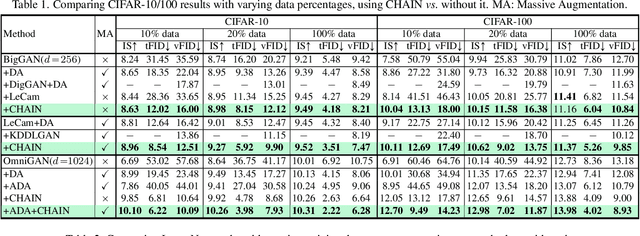

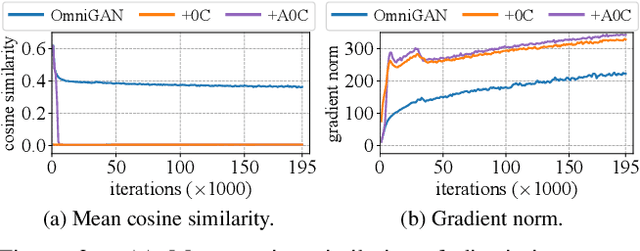
Generative Adversarial Networks (GANs) significantly advanced image generation but their performance heavily depends on abundant training data. In scenarios with limited data, GANs often struggle with discriminator overfitting and unstable training. Batch Normalization (BN), despite being known for enhancing generalization and training stability, has rarely been used in the discriminator of Data-Efficient GANs. Our work addresses this gap by identifying a critical flaw in BN: the tendency for gradient explosion during the centering and scaling steps. To tackle this issue, we present CHAIN (lipsCHitz continuity constrAIned Normalization), which replaces the conventional centering step with zero-mean regularization and integrates a Lipschitz continuity constraint in the scaling step. CHAIN further enhances GAN training by adaptively interpolating the normalized and unnormalized features, effectively avoiding discriminator overfitting. Our theoretical analyses firmly establishes CHAIN's effectiveness in reducing gradients in latent features and weights, improving stability and generalization in GAN training. Empirical evidence supports our theory. CHAIN achieves state-of-the-art results in data-limited scenarios on CIFAR-10/100, ImageNet, five low-shot and seven high-resolution few-shot image datasets. Code: https://github.com/MaxwellYaoNi/CHAIN
Manifold Learning Benefits GANs
Dec 23, 2021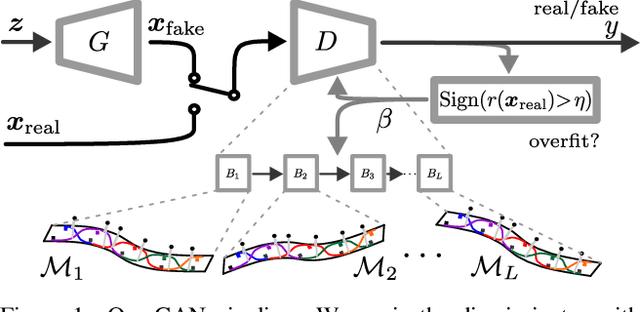
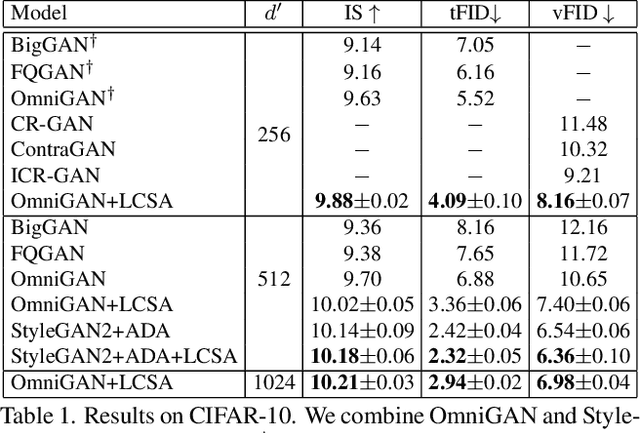
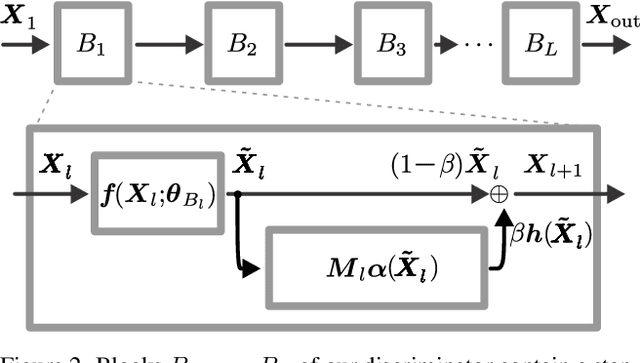
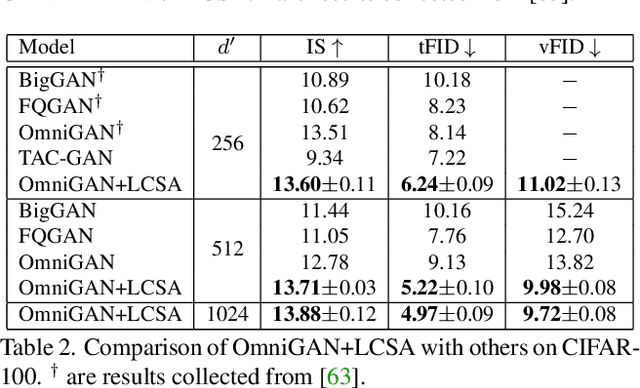
In this paper, we improve Generative Adversarial Networks by incorporating a manifold learning step into the discriminator. We consider locality-constrained linear and subspace-based manifolds, and locality-constrained non-linear manifolds. In our design, the manifold learning and coding steps are intertwined with layers of the discriminator, with the goal of attracting intermediate feature representations onto manifolds. We adaptively balance the discrepancy between feature representations and their manifold view, which represents a trade-off between denoising on the manifold and refining the manifold. We conclude that locality-constrained non-linear manifolds have the upper hand over linear manifolds due to their non-uniform density and smoothness. We show substantial improvements over different recent state-of-the-art baselines.