 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Consistency Regularization for Improved Subject-Driven Image Synthesis
Jun 06, 2025Fine-tuning Stable Diffusion enables subject-driven image synthesis by adapting the model to generate images containing specific subjects. However, existing fine-tuning methods suffer from two key issues: underfitting, where the model fails to reliably capture subject identity, and overfitting, where it memorizes the subject image and reduces background diversity. To address these challenges, we propose two auxiliary consistency losses for diffusion fine-tuning. First, a prior consistency regularization loss ensures that the predicted diffusion noise for prior (non-subject) images remains consistent with that of the pretrained model, improving fidelity. Second, a subject consistency regularization loss enhances the fine-tuned model's robustness to multiplicative noise modulated latent code, helping to preserve subject identity while improving diversity. Our experimental results demonstrate that incorporating these losses into fine-tuning not only preserves subject identity but also enhances image diversity, outperforming DreamBooth in terms of CLIP scores, background variation, and overall visual quality.
Steering Rectified Flow Models in the Vector Field for Controlled Image Generation
Nov 27, 2024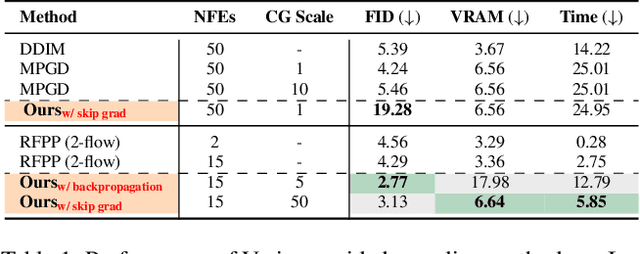
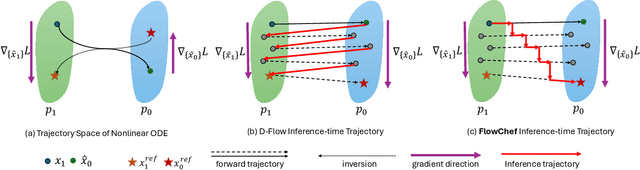
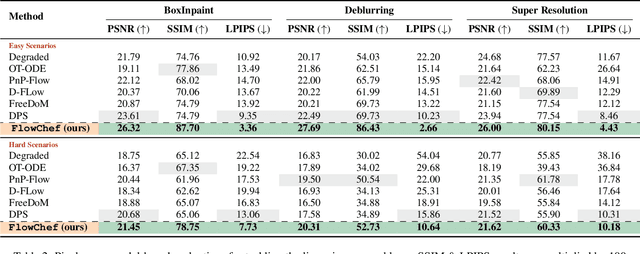

Diffusion models (DMs) excel in photorealism, image editing, and solving inverse problems, aided by classifier-free guidance and image inversion techniques. However, rectified flow models (RFMs) remain underexplored for these tasks. Existing DM-based methods often require additional training, lack generalization to pretrained latent models, underperform, and demand significant computational resources due to extensive backpropagation through ODE solvers and inversion processes. In this work, we first develop a theoretical and empirical understanding of the vector field dynamics of RFMs in efficiently guiding the denoising trajectory. Our findings reveal that we can navigate the vector field in a deterministic and gradient-free manner. Utilizing this property, we propose FlowChef, which leverages the vector field to steer the denoising trajectory for controlled image generation tasks, facilitated by gradient skipping. FlowChef is a unified framework for controlled image generation that, for the first time, simultaneously addresses classifier guidance, linear inverse problems, and image editing without the need for extra training, inversion, or intensive backpropagation. Finally, we perform extensive evaluations and show that FlowChef significantly outperforms baselines in terms of performance, memory, and time requirements, achieving new state-of-the-art results. Project Page: \url{https://flowchef.github.io}.
DICE: Discrete Inversion Enabling Controllable Editing for Multinomial Diffusion and Masked Generative Models
Oct 10, 2024Discrete diffusion models have achieved success in tasks like image generation and masked language modeling but face limitations in controlled content editing. We introduce DICE (Discrete Inversion for Controllable Editing), the first approach to enable precise inversion for discrete diffusion models, including multinomial diffusion and masked generative models. By recording noise sequences and masking patterns during the reverse diffusion process, DICE enables accurate reconstruction and flexible editing of discrete data without the need for predefined masks or attention manipulation. We demonstrate the effectiveness of DICE across both image and text domains, evaluating it on models such as VQ-Diffusion, Paella, and RoBERTa. Our results show that DICE preserves high data fidelity while enhancing editing capabilities, offering new opportunities for fine-grained content manipulation in discrete spaces. For project webpage, see https://hexiaoxiao-cs.github.io/DICE/.
Spectrum-Aware Parameter Efficient Fine-Tuning for Diffusion Models
May 31, 2024Adapting large-scale pre-trained generative models in a parameter-efficient manner is gaining traction. Traditional methods like low rank adaptation achieve parameter efficiency by imposing constraints but may not be optimal for tasks requiring high representation capacity. We propose a novel spectrum-aware adaptation framework for generative models. Our method adjusts both singular values and their basis vectors of pretrained weights. Using the Kronecker product and efficient Stiefel optimizers, we achieve parameter-efficient adaptation of orthogonal matrices. We introduce Spectral Orthogonal Decomposition Adaptation (SODA), which balances computational efficiency and representation capacity. Extensive evaluations on text-to-image diffusion models demonstrate SODA's effectiveness, offering a spectrum-aware alternative to existing fine-tuning methods.
Implicit In-context Learning
May 23, 2024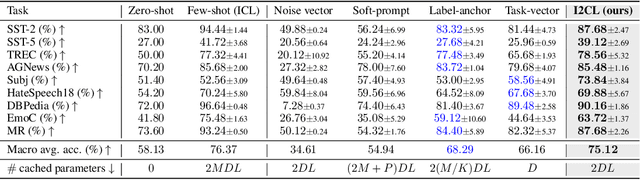
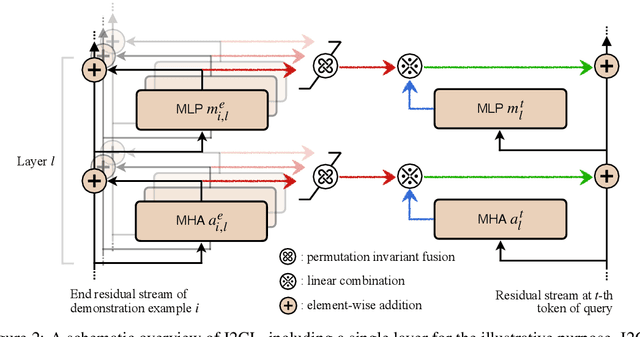

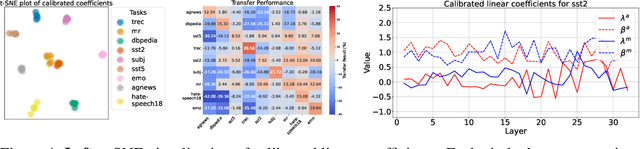
In-context Learning (ICL) empowers large language models (LLMs) to adapt to unseen tasks during inference by prefixing a few demonstration examples prior to test queries. Despite its versatility, ICL incurs substantial computational and memory overheads compared to zero-shot learning and is susceptible to the selection and order of demonstration examples. In this work, we introduce Implicit In-context Learning (I2CL), an innovative paradigm that addresses the challenges associated with traditional ICL by absorbing demonstration examples within the activation space. I2CL first generates a condensed vector representation, namely a context vector, from the demonstration examples. It then integrates the context vector during inference by injecting a linear combination of the context vector and query activations into the model's residual streams. Empirical evaluation on nine real-world tasks across three model architectures demonstrates that I2CL achieves few-shot performance with zero-shot cost and exhibits robustness against the variation of demonstration examples. Furthermore, I2CL facilitates a novel representation of "task-ids", enhancing task similarity detection and enabling effective transfer learning. We provide a comprehensive analysis of I2CL, offering deeper insights into its mechanisms and broader implications for ICL. The source code is available at: https://github.com/LzVv123456/I2CL.
Improving Compositional Text-to-image Generation with Large Vision-Language Models
Oct 10, 2023
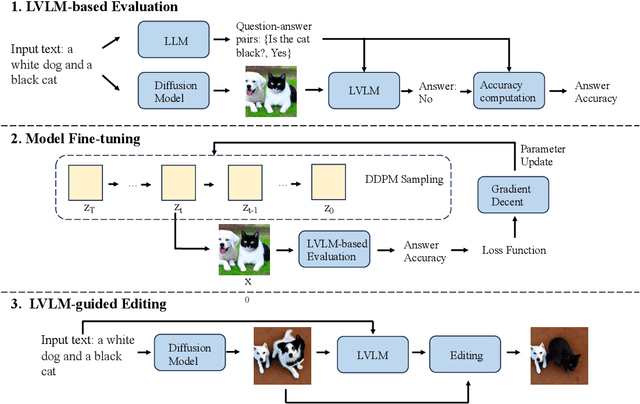


Recent advancements in text-to-image models, particularly diffusion models, have shown significant promise. However, compositional text-to-image models frequently encounter difficulties in generating high-quality images that accurately align with input texts describing multiple objects, variable attributes, and intricate spatial relationships. To address this limitation, we employ large vision-language models (LVLMs) for multi-dimensional assessment of the alignment between generated images and their corresponding input texts. Utilizing this assessment, we fine-tune the diffusion model to enhance its alignment capabilities. During the inference phase, an initial image is produced using the fine-tuned diffusion model. The LVLM is then employed to pinpoint areas of misalignment in the initial image, which are subsequently corrected using the image editing algorithm until no further misalignments are detected by the LVLM. The resultant image is consequently more closely aligned with the input text. Our experimental results validate that the proposed methodology significantly improves text-image alignment in compositional image generation, particularly with respect to object number, attribute binding, spatial relationships, and aesthetic quality.
ImageBind-LLM: Multi-modality Instruction Tuning
Sep 11, 2023
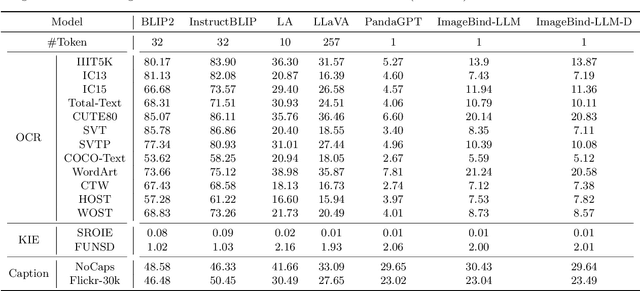
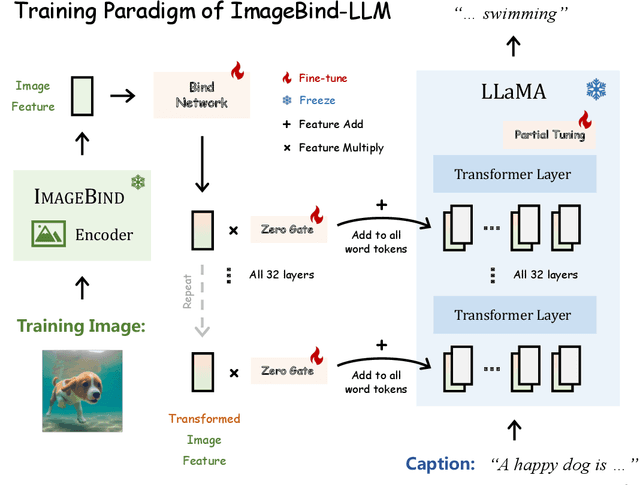
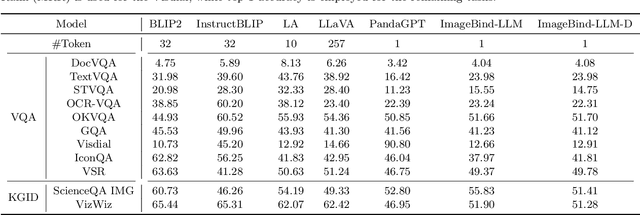
We present ImageBind-LLM, a multi-modality instruction tuning method of large language models (LLMs) via ImageBind. Existing works mainly focus on language and image instruction tuning, different from which, our ImageBind-LLM can respond to multi-modality conditions, including audio, 3D point clouds, video, and their embedding-space arithmetic by only image-text alignment training. During training, we adopt a learnable bind network to align the embedding space between LLaMA and ImageBind's image encoder. Then, the image features transformed by the bind network are added to word tokens of all layers in LLaMA, which progressively injects visual instructions via an attention-free and zero-initialized gating mechanism. Aided by the joint embedding of ImageBind, the simple image-text training enables our model to exhibit superior multi-modality instruction-following capabilities. During inference, the multi-modality inputs are fed into the corresponding ImageBind encoders, and processed by a proposed visual cache model for further cross-modal embedding enhancement. The training-free cache model retrieves from three million image features extracted by ImageBind, which effectively mitigates the training-inference modality discrepancy. Notably, with our approach, ImageBind-LLM can respond to instructions of diverse modalities and demonstrate significant language generation quality. Code is released at https://github.com/OpenGVLab/LLaMA-Adapter.
Improving Tuning-Free Real Image Editing with Proximal Guidance
Jun 29, 2023
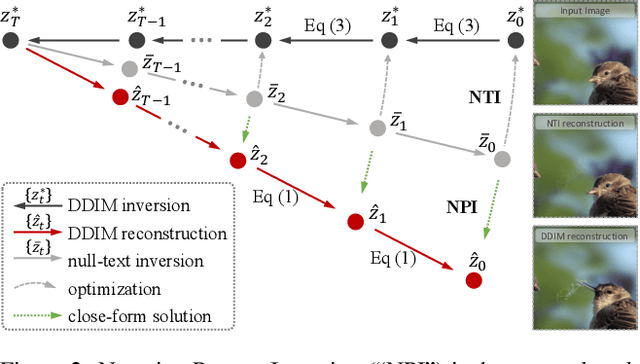
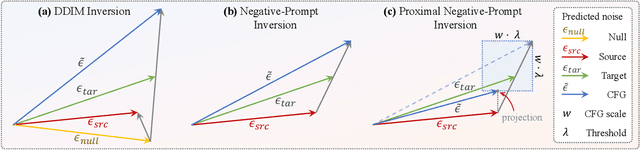

DDIM inversion has revealed the remarkable potential of real image editing within diffusion-based methods. However, the accuracy of DDIM reconstruction degrades as larger classifier-free guidance (CFG) scales being used for enhanced editing. Null-text inversion (NTI) optimizes null embeddings to align the reconstruction and inversion trajectories with larger CFG scales, enabling real image editing with cross-attention control. Negative-prompt inversion (NPI) further offers a training-free closed-form solution of NTI. However, it may introduce artifacts and is still constrained by DDIM reconstruction quality. To overcome these limitations, we propose proximal guidance and incorporate it to NPI with cross-attention control. We enhance NPI with a regularization term and reconstruction guidance, which reduces artifacts while capitalizing on its training-free nature. Additionally, we extend the concepts to incorporate mutual self-attention control, enabling geometry and layout alterations in the editing process. Our method provides an efficient and straightforward approach, effectively addressing real image editing tasks with minimal computational overhead.
Run, Don't Walk: Chasing Higher FLOPS for Faster Neural Networks
Mar 07, 2023To design fast neural networks, many works have been focusing on reducing the number of floating-point operations (FLOPs). We observe that such reduction in FLOPs, however, does not necessarily lead to a similar level of reduction in latency. This mainly stems from inefficiently low floating-point operations per second (FLOPS). To achieve faster networks, we revisit popular operators and demonstrate that such low FLOPS is mainly due to frequent memory access of the operators, especially the depthwise convolution. We hence propose a novel partial convolution (PConv) that extracts spatial features more efficiently, by cutting down redundant computation and memory access simultaneously. Building upon our PConv, we further propose FasterNet, a new family of neural networks, which attains substantially higher running speed than others on a wide range of devices, without compromising on accuracy for various vision tasks. For example, on ImageNet-1k, our tiny FasterNet-T0 is $3.1\times$, $3.1\times$, and $2.5\times$ faster than MobileViT-XXS on GPU, CPU, and ARM processors, respectively, while being $2.9\%$ more accurate. Our large FasterNet-L achieves impressive $83.5\%$ top-1 accuracy, on par with the emerging Swin-B, while having $49\%$ higher inference throughput on GPU, as well as saving $42\%$ compute time on CPU. Code is available at \url{https://github.com/JierunChen/FasterNet}.
Crowd Counting by Self-supervised Transfer Colorization Learning and Global Prior Classification
May 20, 2021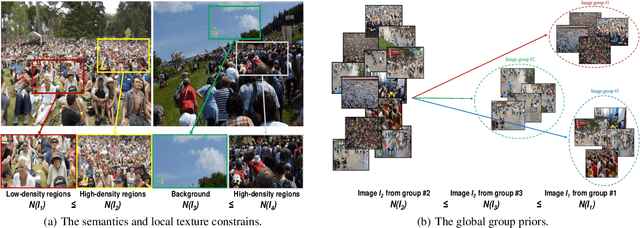

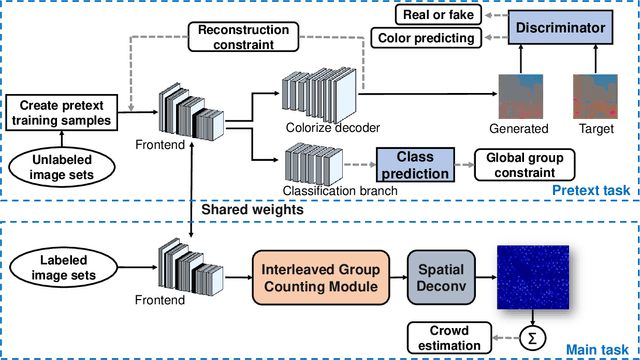

Labeled crowd scene images are expensive and scarce. To significantly reduce the requirement of the labeled images, we propose ColorCount, a novel CNN-based approach by combining self-supervised transfer colorization learning and global prior classification to leverage the abundantly available unlabeled data. The self-supervised colorization branch learns the semantics and surface texture of the image by using its color components as pseudo labels. The classification branch extracts global group priors by learning correlations among image clusters. Their fused resultant discriminative features (global priors, semantics and textures) provide ample priors for counting, hence significantly reducing the requirement of labeled images. We conduct extensive experiments on four challenging benchmarks. ColorCount achieves much better performance as compared with other unsupervised approaches. Its performance is close to the supervised baseline with substantially less labeled data (10\% of the original one).