 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanRefiner: Benchmarking Abnormal Human Generation and Refining with Coarse-to-fine Pose-Reversible Guidance
Jul 09, 2024



Text-to-image diffusion models have significantly advanced in conditional image generation. However, these models usually struggle with accurately rendering images featuring humans, resulting in distorted limbs and other anomalies. This issue primarily stems from the insufficient recognition and evaluation of limb qualities in diffusion models. To address this issue, we introduce AbHuman, the first large-scale synthesized human benchmark focusing on anatomical anomalies. This benchmark consists of 56K synthesized human images, each annotated with detailed, bounding-box level labels identifying 147K human anomalies in 18 different categories. Based on this, the recognition of human anomalies can be established, which in turn enhances image generation through traditional techniques such as negative prompting and guidance. To further boost the improvement, we propose HumanRefiner, a novel plug-and-play approach for the coarse-to-fine refinement of human anomalies in text-to-image generation. Specifically, HumanRefiner utilizes a self-diagnostic procedure to detect and correct issues related to both coarse-grained abnormal human poses and fine-grained anomaly levels, facilitating pose-reversible diffusion generation. Experimental results on the AbHuman benchmark demonstrate that HumanRefiner significantly reduces generative discrepancies, achieving a 2.9x improvement in limb quality compared to the state-of-the-art open-source generator SDXL and a 1.4x improvement over DALL-E 3 in human evaluations. Our data and code are available at https://github.com/Enderfga/HumanRefiner.
ChartThinker: A Contextual Chain-of-Thought Approach to Optimized Chart Summarization
Mar 17, 2024
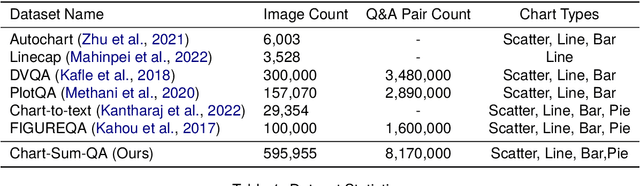
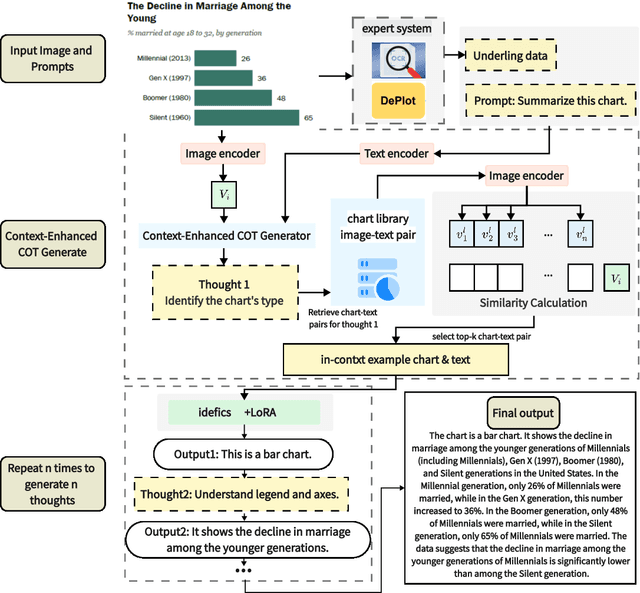
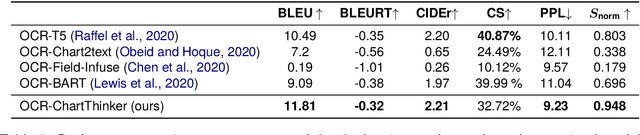
Data visualization serves as a critical means for presenting data and mining its valuable insights. The task of chart summarization, through natural language processing techniques, facilitates in-depth data analysis of charts. However, there still are notable deficiencies in terms of visual-language matching and reasoning ability for existing approaches. To address these limitations, this study constructs a large-scale dataset of comprehensive chart-caption pairs and fine-tuning instructions on each chart. Thanks to the broad coverage of various topics and visual styles within this dataset, better matching degree can be achieved from the view of training data. Moreover, we propose an innovative chart summarization method, ChartThinker, which synthesizes deep analysis based on chains of thought and strategies of context retrieval, aiming to improve the logical coherence and accuracy of the generated summaries. Built upon the curated datasets, our trained model consistently exhibits superior performance in chart summarization tasks, surpassing 8 state-of-the-art models over 7 evaluation metrics. Our dataset and codes are publicly accessible.
Towards A Better Metric for Text-to-Video Generation
Jan 15, 2024Generative models have demonstrated remarkable capability in synthesizing high-quality text, images, and videos. For video generation, contemporary text-to-video models exhibit impressive capabilities, crafting visually stunning videos. Nonetheless, evaluating such videos poses significant challenges. Current research predominantly employs automated metrics such as FVD, IS, and CLIP Score. However, these metrics provide an incomplete analysis, particularly in the temporal assessment of video content, thus rendering them unreliable indicators of true video quality. Furthermore, while user studies have the potential to reflect human perception accurately, they are hampered by their time-intensive and laborious nature, with outcomes that are often tainted by subjective bias. In this paper, we investigate the limitations inherent in existing metrics and introduce a novel evaluation pipeline, the Text-to-Video Score (T2VScore). This metric integrates two pivotal criteria: (1) Text-Video Alignment, which scrutinizes the fidelity of the video in representing the given text description, and (2) Video Quality, which evaluates the video's overall production caliber with a mixture of experts. Moreover, to evaluate the proposed metrics and facilitate future improvements on them, we present the TVGE dataset, collecting human judgements of 2,543 text-to-video generated videos on the two criteria. Experiments on the TVGE dataset demonstrate the superiority of the proposed T2VScore on offering a better metric for text-to-video generation.
Improving Compositional Text-to-image Generation with Large Vision-Language Models
Oct 10, 2023
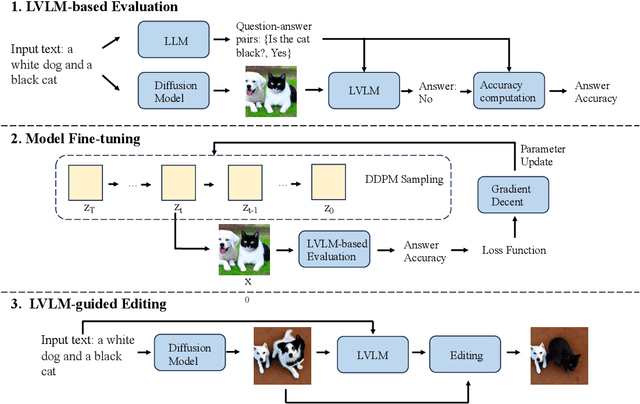


Recent advancements in text-to-image models, particularly diffusion models, have shown significant promise. However, compositional text-to-image models frequently encounter difficulties in generating high-quality images that accurately align with input texts describing multiple objects, variable attributes, and intricate spatial relationships. To address this limitation, we employ large vision-language models (LVLMs) for multi-dimensional assessment of the alignment between generated images and their corresponding input texts. Utilizing this assessment, we fine-tune the diffusion model to enhance its alignment capabilities. During the inference phase, an initial image is produced using the fine-tuned diffusion model. The LVLM is then employed to pinpoint areas of misalignment in the initial image, which are subsequently corrected using the image editing algorithm until no further misalignments are detected by the LVLM. The resultant image is consequently more closely aligned with the input text. Our experimental results validate that the proposed methodology significantly improves text-image alignment in compositional image generation, particularly with respect to object number, attribute binding, spatial relationships, and aesthetic quality.
LTCR: Long-Text Chinese Rumor Detection Dataset
Jun 13, 2023False information can spread quickly on social media, negatively influencing the citizens' behaviors and responses to social events. To better detect all of the fake news, especially long texts which are harder to find completely, a Long-Text Chinese Rumor detection dataset named LTCR is proposed. The LTCR dataset provides a valuable resource for accurately detecting misinformation, especially in the context of complex fake news related to COVID-19. The dataset consists of 1,729 and 500 pieces of real and fake news, respectively. The average lengths of real and fake news are approximately 230 and 152 characters. We also propose \method, Salience-aware Fake News Detection Model, which achieves the highest accuracy (95.85%), fake news recall (90.91%) and F-score (90.60%) on the dataset. (https://github.com/Enderfga/DoubleCheck)
Boosting Text-to-Image Diffusion Models with Fine-Grained Semantic Rewards
Jun 01, 2023

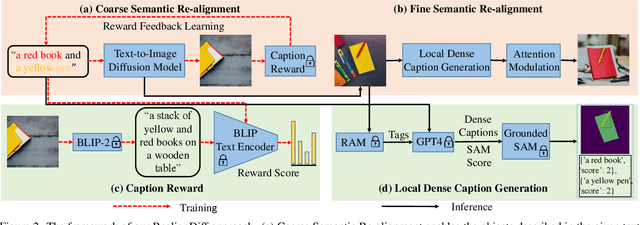
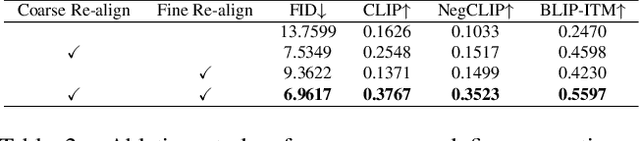
Recent advances in text-to-image diffusion models have achieved remarkable success in generating high-quality, realistic images from given text prompts. However, previous methods fail to perform accurate modality alignment between text concepts and generated images due to the lack of fine-level semantic guidance that successfully diagnoses the modality discrepancy. In this paper, we propose FineRewards to improve the alignment between text and images in text-to-image diffusion models by introducing two new fine-grained semantic rewards: the caption reward and the Semantic Segment Anything (SAM) reward. From the global semantic view, the caption reward generates a corresponding detailed caption that depicts all important contents in the synthetic image via a BLIP-2 model and then calculates the reward score by measuring the similarity between the generated caption and the given prompt. From the local semantic view, the SAM reward segments the generated images into local parts with category labels, and scores the segmented parts by measuring the likelihood of each category appearing in the prompted scene via a large language model, i.e., Vicuna-7B. Additionally, we adopt an assemble reward-ranked learning strategy to enable the integration of multiple reward functions to jointly guide the model training. Adapting results of text-to-image models on the MS-COCO benchmark show that the proposed semantic reward outperforms other baseline reward functions with a considerable margin on both visual quality and semantic similarity with the input prompt. Moreover, by adopting the assemble reward-ranked learning strategy, we further demonstrate that model performance is further improved when adapting under the unifying of the proposed semantic reward with the current image rewards.