 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Compositional Text-to-image Generation with Large Vision-Language Models
Paper and Code
Oct 10, 2023
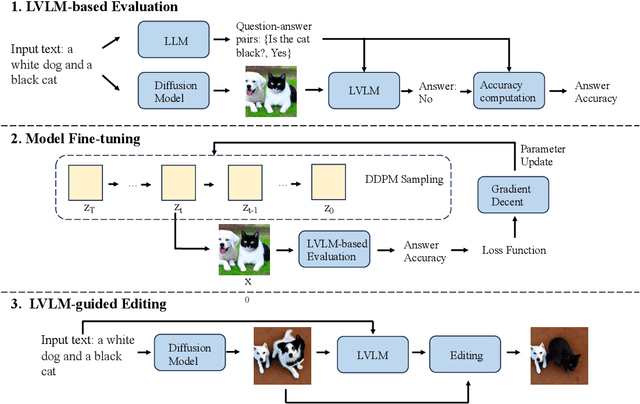


Recent advancements in text-to-image models, particularly diffusion models, have shown significant promise. However, compositional text-to-image models frequently encounter difficulties in generating high-quality images that accurately align with input texts describing multiple objects, variable attributes, and intricate spatial relationships. To address this limitation, we employ large vision-language models (LVLMs) for multi-dimensional assessment of the alignment between generated images and their corresponding input texts. Utilizing this assessment, we fine-tune the diffusion model to enhance its alignment capabilities. During the inference phase, an initial image is produced using the fine-tuned diffusion model. The LVLM is then employed to pinpoint areas of misalignment in the initial image, which are subsequently corrected using the image editing algorithm until no further misalignments are detected by the LVLM. The resultant image is consequently more closely aligned with the input text. Our experimental results validate that the proposed methodology significantly improves text-image alignment in compositional image generation, particularly with respect to object number, attribute binding, spatial relationships, and aesthetic quality.