 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartThinker: A Contextual Chain-of-Thought Approach to Optimized Chart Summarization
Mar 17, 2024
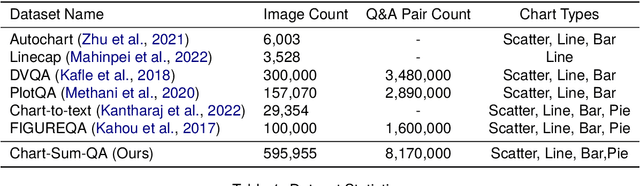
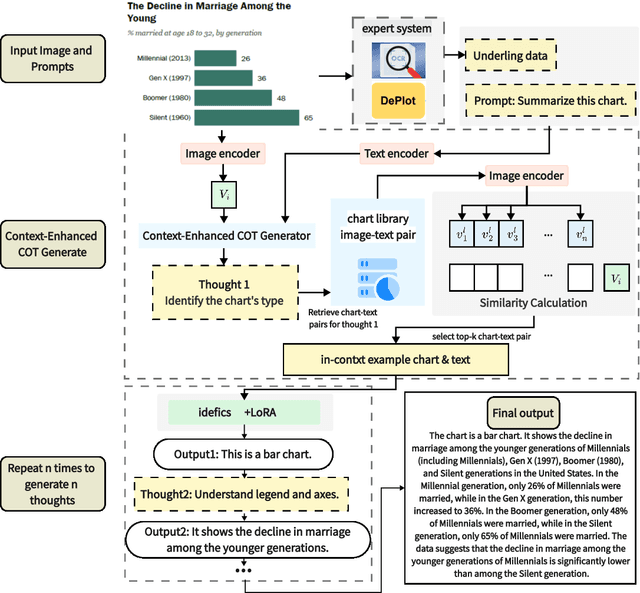
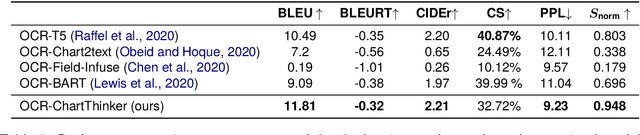
Data visualization serves as a critical means for presenting data and mining its valuable insights. The task of chart summarization, through natural language processing techniques, facilitates in-depth data analysis of charts. However, there still are notable deficiencies in terms of visual-language matching and reasoning ability for existing approaches. To address these limitations, this study constructs a large-scale dataset of comprehensive chart-caption pairs and fine-tuning instructions on each chart. Thanks to the broad coverage of various topics and visual styles within this dataset, better matching degree can be achieved from the view of training data. Moreover, we propose an innovative chart summarization method, ChartThinker, which synthesizes deep analysis based on chains of thought and strategies of context retrieval, aiming to improve the logical coherence and accuracy of the generated summaries. Built upon the curated datasets, our trained model consistently exhibits superior performance in chart summarization tasks, surpassing 8 state-of-the-art models over 7 evaluation metrics. Our dataset and codes are publicly accessible.
LTCR: Long-Text Chinese Rumor Detection Dataset
Jun 13, 2023False information can spread quickly on social media, negatively influencing the citizens' behaviors and responses to social events. To better detect all of the fake news, especially long texts which are harder to find completely, a Long-Text Chinese Rumor detection dataset named LTCR is proposed. The LTCR dataset provides a valuable resource for accurately detecting misinformation, especially in the context of complex fake news related to COVID-19. The dataset consists of 1,729 and 500 pieces of real and fake news, respectively. The average lengths of real and fake news are approximately 230 and 152 characters. We also propose \method, Salience-aware Fake News Detection Model, which achieves the highest accuracy (95.85%), fake news recall (90.91%) and F-score (90.60%) on the dataset. (https://github.com/Enderfga/DoubleCheck)