 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCBV: Clean-label Backdoor Attacks on Vision Language Models via Diffusion Models
May 04, 2026Vision-Language Models (VLMs) have achieved remarkable success in tasks such as image captioning and visual question answering (VQA). However, as their applications become increasingly widespread, recent studies have revealed that VLMs are vulnerable to backdoor attacks. Existing backdoor attacks on VLMs primarily rely on data poisoning by adding visual triggers and modifying text labels, where the induced image-text mismatch makes poisoned samples easy to detect. To address this limitation, we propose the Clean-Label Backdoor Attack on VLMs via Diffusion Models (CBV), which leverages diffusion models to generate natural poisoned examples via score matching. Specifically, CBV modifies the score during the reverse generation process of the diffusion model to guide the generation of poisoned samples that contain triggered image features. To further enhance the effectiveness of the attack, we incorporate the textual information of the triggered images as multimodal guidance during generation. Moreover, to enhance stealthiness, we introduce a GradCAM-guided Mask (GM) that restricts modifications to only the most semantically important regions, rather than the entire image. We evaluate our method on MSCOCO and VQA v2 with four representative VLMs, achieving over 80% ASR while preserving normal functionality.
GRPO-VPS: Enhancing Group Relative Policy Optimization with Verifiable Process Supervision for Effective Reasoning
Apr 22, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has advanced the reasoning capabilities of Large Language Models (LLMs) by leveraging direct outcome verification instead of learned reward models. Building on this paradigm, Group Relative Policy Optimization (GRPO) eliminates the need for critic models but suffers from indiscriminate credit assignment for intermediate steps, which limits its ability to identify effective reasoning strategies and incurs overthinking. In this work, we introduce a model-free and verifiable process supervision via probing the model's belief in the correct answer throughout its reasoning trajectory. By segmenting the generation into discrete steps and tracking the conditional probability of the correct answer appended at each segment boundary, we efficiently compute interpretable segment-wise progress measurements to refine GRPO's trajectory-level feedback. This approach enables more targeted and sample-efficient policy updates, while avoiding the need for intermediate supervision derived from costly Monte Carlo rollouts or auxiliary models. Experiments on mathematical and general-domain benchmarks show consistent gains over GRPO across diverse models: up to 2.6-point accuracy improvements and 13.7% reasoning-length reductions on math tasks, and up to 2.4 points and 4% on general-domain tasks, demonstrating strong generalization.
FastCode: Fast and Cost-Efficient Code Understanding and Reasoning
Mar 03, 2026Repository-scale code reasoning is a cornerstone of modern AI-assisted software engineering, enabling Large Language Models (LLMs) to handle complex workflows from program comprehension to complex debugging. However, balancing accuracy with context cost remains a significant bottleneck, as existing agentic approaches often waste computational resources through inefficient, iterative full-text exploration. To address this, we introduce FastCode, a framework that decouples repository exploration from content consumption. FastCode utilizes a structural scouting mechanism to navigate a lightweight semantic-structural map of the codebase, allowing the system to trace dependencies and pinpoint relevant targets without the overhead of full-text ingestion. By leveraging structure-aware navigation tools regulated by a cost-aware policy, the framework constructs high-value contexts in a single, optimized step. Extensive evaluations on the SWE-QA, LongCodeQA, LOC-BENCH, and GitTaskBench benchmarks demonstrate that FastCode consistently outperforms state-of-the-art baselines in reasoning accuracy while significantly reducing token consumption, validating the efficiency of scouting-first strategies for large-scale code reasoning. Source code is available at https://github.com/HKUDS/FastCode.
From Verifiable Dot to Reward Chain: Harnessing Verifiable Reference-based Rewards for Reinforcement Learning of Open-ended Generation
Jan 26, 2026Reinforcement learning with verifiable rewards (RLVR) succeeds in reasoning tasks (e.g., math and code) by checking the final verifiable answer (i.e., a verifiable dot signal). However, extending this paradigm to open-ended generation is challenging because there is no unambiguous ground truth. Relying on single-dot supervision often leads to inefficiency and reward hacking. To address these issues, we propose reinforcement learning with verifiable reference-based rewards (RLVRR). Instead of checking the final answer, RLVRR extracts an ordered linguistic signal from high-quality references (i.e, reward chain). Specifically, RLVRR decomposes rewards into two dimensions: content, which preserves deterministic core concepts (e.g., keywords), and style, which evaluates adherence to stylistic properties through LLM-based verification. In this way, RLVRR combines the exploratory strength of RL with the efficiency and reliability of supervised fine-tuning (SFT). Extensive experiments on more than 10 benchmarks with Qwen and Llama models confirm the advantages of our approach. RLVRR (1) substantially outperforms SFT trained with ten times more data and advanced reward models, (2) unifies the training of structured reasoning and open-ended generation, and (3) generalizes more effectively while preserving output diversity. These results establish RLVRR as a principled and efficient path toward verifiable reinforcement learning for general-purpose LLM alignment. We release our code and data at https://github.com/YJiangcm/RLVRR.
SWE-Lego: Pushing the Limits of Supervised Fine-tuning for Software Issue Resolving
Jan 07, 2026We present SWE-Lego, a supervised fine-tuning (SFT) recipe designed to achieve state-ofthe-art performance in software engineering (SWE) issue resolving. In contrast to prevalent methods that rely on complex training paradigms (e.g., mid-training, SFT, reinforcement learning, and their combinations), we explore how to push the limits of a lightweight SFT-only approach for SWE tasks. SWE-Lego comprises three core building blocks, with key findings summarized as follows: 1) the SWE-Lego dataset, a collection of 32k highquality task instances and 18k validated trajectories, combining real and synthetic data to complement each other in both quality and quantity; 2) a refined SFT procedure with error masking and a difficulty-based curriculum, which demonstrably improves action quality and overall performance. Empirical results show that with these two building bricks alone,the SFT can push SWE-Lego models to state-of-the-art performance among open-source models of comparable size on SWE-bench Verified: SWE-Lego-Qwen3-8B reaches 42.2%, and SWE-Lego-Qwen3-32B attains 52.6%. 3) We further evaluate and improve test-time scaling (TTS) built upon the SFT foundation. Based on a well-trained verifier, SWE-Lego models can be significantly boosted--for example, 42.2% to 49.6% and 52.6% to 58.8% under TTS@16 for the 8B and 32B models, respectively.
InSight-o3: Empowering Multimodal Foundation Models with Generalized Visual Search
Dec 21, 2025The ability for AI agents to "think with images" requires a sophisticated blend of reasoning and perception. However, current open multimodal agents still largely fall short on the reasoning aspect crucial for real-world tasks like analyzing documents with dense charts/diagrams and navigating maps. To address this gap, we introduce O3-Bench, a new benchmark designed to evaluate multimodal reasoning with interleaved attention to visual details. O3-Bench features challenging problems that require agents to piece together subtle visual information from distinct image areas through multi-step reasoning. The problems are highly challenging even for frontier systems like OpenAI o3, which only obtains 40.8% accuracy on O3-Bench. To make progress, we propose InSight-o3, a multi-agent framework consisting of a visual reasoning agent (vReasoner) and a visual search agent (vSearcher) for which we introduce the task of generalized visual search -- locating relational, fuzzy, or conceptual regions described in free-form language, beyond just simple objects or figures in natural images. We then present a multimodal LLM purpose-trained for this task via reinforcement learning. As a plug-and-play agent, our vSearcher empowers frontier multimodal models (as vReasoners), significantly improving their performance on a wide range of benchmarks. This marks a concrete step towards powerful o3-like open systems. Our code and dataset can be found at https://github.com/m-Just/InSight-o3 .
Efficient Reasoning for Large Reasoning Language Models via Certainty-Guided Reflection Suppression
Aug 07, 2025Recent Large Reasoning Language Models (LRLMs) employ long chain-of-thought reasoning with complex reflection behaviors, typically signaled by specific trigger words (e.g., "Wait" and "Alternatively") to enhance performance. However, these reflection behaviors can lead to the overthinking problem where the generation of redundant reasoning steps that unnecessarily increase token usage, raise inference costs, and reduce practical utility. In this paper, we propose Certainty-Guided Reflection Suppression (CGRS), a novel method that mitigates overthinking in LRLMs while maintaining reasoning accuracy. CGRS operates by dynamically suppressing the model's generation of reflection triggers when it exhibits high confidence in its current response, thereby preventing redundant reflection cycles without compromising output quality. Our approach is model-agnostic, requires no retraining or architectural modifications, and can be integrated seamlessly with existing autoregressive generation pipelines. Extensive experiments across four reasoning benchmarks (i.e., AIME24, AMC23, MATH500, and GPQA-D) demonstrate CGRS's effectiveness: it reduces token usage by an average of 18.5% to 41.9% while preserving accuracy. It also achieves the optimal balance between length reduction and performance compared to state-of-the-art baselines. These results hold consistently across model architectures (e.g., DeepSeek-R1-Distill series, QwQ-32B, and Qwen3 family) and scales (4B to 32B parameters), highlighting CGRS's practical value for efficient reasoning.
The Synergy Dilemma of Long-CoT SFT and RL: Investigating Post-Training Techniques for Reasoning VLMs
Jul 10, 2025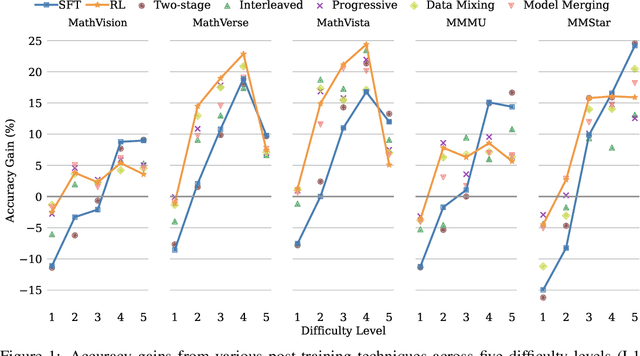
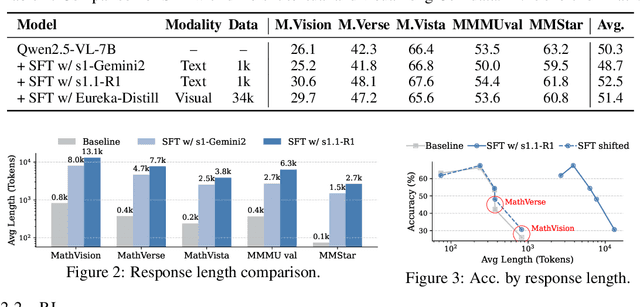
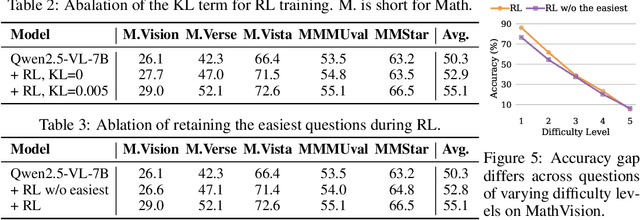
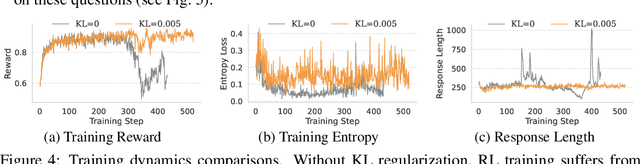
Large vision-language models (VLMs) increasingly adopt post-training techniques such as long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL) to elicit sophisticated reasoning. While these methods exhibit synergy in language-only models, their joint effectiveness in VLMs remains uncertain. We present a systematic investigation into the distinct roles and interplay of long-CoT SFT and RL across multiple multimodal reasoning benchmarks. We find that SFT improves performance on difficult questions by in-depth, structured reasoning, but introduces verbosity and degrades performance on simpler ones. In contrast, RL promotes generalization and brevity, yielding consistent improvements across all difficulty levels, though the improvements on the hardest questions are less prominent compared to SFT. Surprisingly, combining them through two-staged, interleaved, or progressive training strategies, as well as data mixing and model merging, all fails to produce additive benefits, instead leading to trade-offs in accuracy, reasoning style, and response length. This ``synergy dilemma'' highlights the need for more seamless and adaptive approaches to unlock the full potential of combined post-training techniques for reasoning VLMs.
SnapGen: Taming High-Resolution Text-to-Image Models for Mobile Devices with Efficient Architectures and Training
Dec 12, 2024Existing text-to-image (T2I) diffusion models face several limitations, including large model sizes, slow runtime, and low-quality generation on mobile devices. This paper aims to address all of these challenges by developing an extremely small and fast T2I model that generates high-resolution and high-quality images on mobile platforms. We propose several techniques to achieve this goal. First, we systematically examine the design choices of the network architecture to reduce model parameters and latency, while ensuring high-quality generation. Second, to further improve generation quality, we employ cross-architecture knowledge distillation from a much larger model, using a multi-level approach to guide the training of our model from scratch. Third, we enable a few-step generation by integrating adversarial guidance with knowledge distillation. For the first time, our model SnapGen, demonstrates the generation of 1024x1024 px images on a mobile device around 1.4 seconds. On ImageNet-1K, our model, with only 372M parameters, achieves an FID of 2.06 for 256x256 px generation. On T2I benchmarks (i.e., GenEval and DPG-Bench), our model with merely 379M parameters, surpasses large-scale models with billions of parameters at a significantly smaller size (e.g., 7x smaller than SDXL, 14x smaller than IF-XL).
AsCAN: Asymmetric Convolution-Attention Networks for Efficient Recognition and Generation
Nov 07, 2024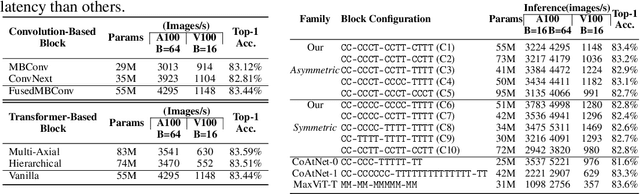
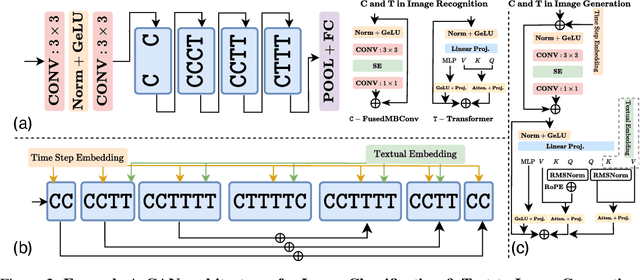
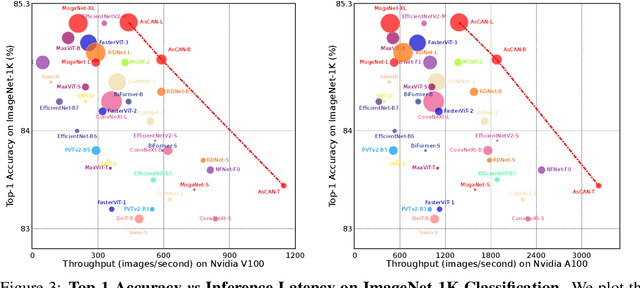
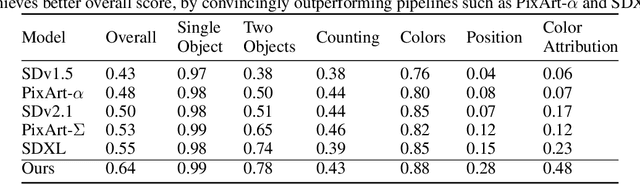
Neural network architecture design requires making many crucial decisions. The common desiderata is that similar decisions, with little modifications, can be reused in a variety of tasks and applications. To satisfy that, architectures must provide promising latency and performance trade-offs, support a variety of tasks, scale efficiently with respect to the amounts of data and compute, leverage available data from other tasks, and efficiently support various hardware. To this end, we introduce AsCAN -- a hybrid architecture, combining both convolutional and transformer blocks. We revisit the key design principles of hybrid architectures and propose a simple and effective \emph{asymmetric} architecture, where the distribution of convolutional and transformer blocks is \emph{asymmetric}, containing more convolutional blocks in the earlier stages, followed by more transformer blocks in later stages. AsCAN supports a variety of tasks: recognition, segmentation, class-conditional image generation, and features a superior trade-off between performance and latency. We then scale the same architecture to solve a large-scale text-to-image task and show state-of-the-art performance compared to the most recent public and commercial models. Notably, even without any computation optimization for transformer blocks, our models still yield faster inference speed than existing works featuring efficient attention mechanisms, highlighting the advantages and the value of our approach.